mengzi retrieval lm
1.0.0
В Langboat Technology мы уделяем особое внимание совершенствованию предварительно обученных моделей, чтобы сделать их легче и удовлетворить реальные потребности отрасли. Подход, основанный на поиске (например, RETRO, REALM и RAG), имеет решающее значение для достижения этой цели.
Этот репозиторий представляет собой экспериментальную реализацию языковой модели с расширенным поиском. В настоящее время он поддерживает только извлечение данных в GPT-Neo.
Мы создали форк Huggingface Transformers и lm-evaluation-harness, чтобы добавить поддержку поиска. Индексирующая часть реализована в виде HTTP-сервера, чтобы лучше разделить поиск и обучение.
Большая часть реализации модели скопирована из RETRO-pytorch и GPT-Neo. Мы используем transformers-cli , чтобы добавить новую модель с именем Re_gptForCausalLM на основе GPT-Neo, а затем добавить к ней поисковую часть.
Мы загрузили модель, установленную на EleutherAI/gpt-neo-125M, используя библиотеку поиска 200G.
Вы можете инициализировать модель следующим образом:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )И оцените модель так:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1Мы вычисляем сходство, используя встраивание предложения_трансформеров в качестве текстового представления. Вы можете инициализировать модель Sentence-BERT следующим образом:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )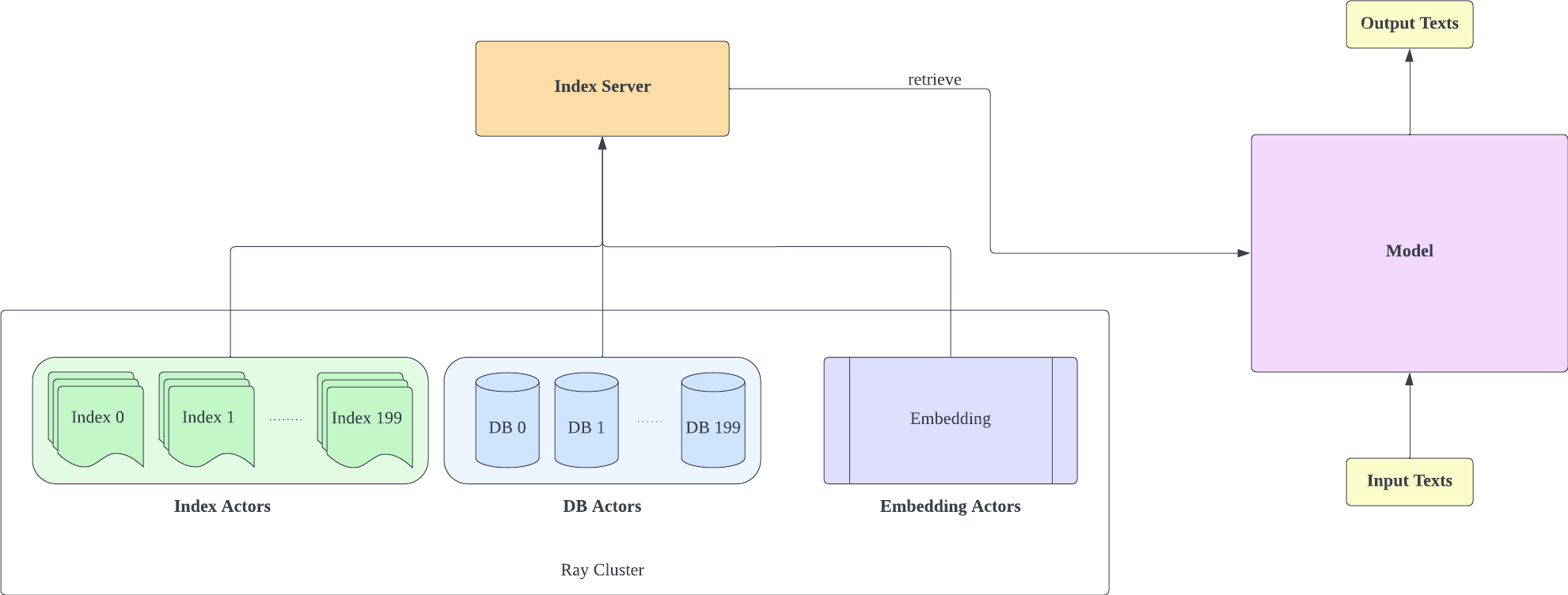
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " Используя IVF1024PQ48 в качестве фабрики индексов faiss, мы загрузили индекс и базу данных в концентратор моделей Huggingface, которые можно загрузить с помощью следующей команды.
В файле download_index_db.py вы можете указать количество индексов и баз данных, которые вы хотите загрузить.
python -u download_index_db.py --num 200Вы можете вручную загрузить установленную модель здесь: https://huggingface.co/Langboat/ReGPT-125M-200G.
Индексный сервер основан на FastAPI и Ray. С помощью Ray's Actor задачи с интенсивными вычислениями инкапсулируются асинхронно, что позволяет нам эффективно использовать ресурсы ЦП и графического процессора с помощью всего лишь одного экземпляра сервера FastAPI. Вы можете инициализировать индексный сервер следующим образом:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- Имейте в виду, что количество осколков конфигурации IVF1024PQ48.json должно соответствовать количеству загруженных индексов. Вы можете просмотреть текущий загруженный индексный номер в db_path.
- Эта конфигурация была протестирована на A100-40G, поэтому, если у вас другой графический процессор, мы рекомендуем настроить его под ваше оборудование.
- После развертывания сервера индексирования вам необходимо изменить request_server в lm-evaluation-harness/config.json и train/config.json.
- Вы можете уменьшить encoder_actor_count в config_IVF1024PQ48.json, чтобы уменьшить требуемые ресурсы памяти.
· db_path: место загрузки базы данных с HuggingFace. Примером может служить «../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966».
Эта команда загрузит базу данных и индексирует данные из HuggingFace.
Измените индексную папку в файле конфигурации (config IVF1024PQ48), чтобы она указывала путь к индексной папке, и отправьте снимки папки базы данных в качестве пути к базе данных в сценарий api.py.
Остановите сервер индексирования с помощью следующей команды
ray stop
- Имейте в виду, что вам необходимо держать сервер индексирования включенным во время обучения, оценки и вывода.
Используйте train/train.py для реализации обучения; train/config.json можно изменить, чтобы изменить параметры обучения.
Вы можете инициализировать обучение следующим образом:
cd train
python -u train.py
- Поскольку серверу индексирования необходимо использовать ресурсы памяти, лучше развернуть сервер индексирования и обучение модели на разных графических процессорах.
Используйте train/inference.py в качестве вывода, чтобы определить потерю текста и его недоумение.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- Файлы test_data.json и train_data.json в папке данных в настоящее время поддерживаются в форматах файлов. Вы можете изменить свои данные в этом формате.
Используйте lm-evaluation-harness в качестве метода оценки.
Мы установили seq_len lm-evaluation-harness равным 1025 в качестве начальной настройки для сравнения моделей, поскольку seq_len нашего обучения модели равен 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path: путь к подходящей модели.
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1Результаты оценки следующие:
| модель | викитекст word_perplexity |
|---|---|
| ЭлеутерАИ/gpt-нео-125М | 35,8774 |
| Лангбот/РеГПТ-125М-200Г | 22.115 |
| ЭлеутерAI/gpt-neo-1.3B | 17,6979 |
| Лангбот/РеГПТ-125М-400Г | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

