GraphGPT: обучение графам с помощью генеративных предварительно обученных преобразователей
Этот репозиторий является официальной реализацией «GraphGPT: обучение графов с помощью генеративных предварительно обученных преобразователей» в PyTorch.
GraphGPT: обучение графам с помощью генеративных предварительно обученных преобразователей
Цифан Чжао, Вэйдун Жэнь, Тяньюй Ли, Сяосяо Сюй, Хун Лю
Обновлять:
13.10.2024
- Выпущена версия 0.4.0. Подробности можно узнать на сайте
CHANGELOG.md . - Достижение SOTA в 3 крупномасштабных наборах данных ogb:
- PCQM4M-v2 (без 3D): 0,0802 (предыдущий SOTA 0,0821)
- ogbl-ppa: 68,76 (предыдущий SOTA 65,24)
- ogbl-citation2: 91.15 (предыдущий SOTA 90.72)
18.08.2024
- Выпущена версия 0.3.1. Подробности можно узнать на сайте
CHANGELOG.md .
09.07.2024
- Выпущена версия 0.3.0.
19.03.2024
- Выпущена версия 0.2.0.
- Внедрите
permute_nodes для набора данных в стиле карты на уровне графа, чтобы увеличить вариации эйлеровых путей и получить лучшие и надежные результаты. - Добавьте
StackedGSTTokenizer , чтобы токены семантики (т. е. атрибуты узла/ребра) можно было складывать вместе со структурными токенами, а длина последовательности была бы значительно уменьшена. - коды рефакторинга.
23.01.2024
- v0.1.1, исправлены ошибки пакета common-io.
03.01.2024
- Первоначальный выпуск кодов.
Будущие направления
Закон масштабирования: каков предел масштабирования моделей GraphGPT?
- Как мы знаем, GPT, обученный на текстовых данных, может масштабироваться до сотен миллиардов параметров и постоянно совершенствовать свои возможности.
- Текстовые данные могут содержать триллионы токенов, имеют очень высокую сложность и содержат множество знаний, включая социальные и естественные знания.
- Напротив, данные графа без атрибутов узла/ребра содержат только информацию о структуре, которая весьма ограничена по сравнению с текстовыми данными. Большую часть скрытой информации (например, степени, количество подструктур и т. д.) за структурой можно точно вычислить с помощью таких пакетов, как networkx. Следовательно, информация из структуры графа может не поддерживать масштабирование размера модели до миллиардов параметров.
- Наши предварительные эксперименты с различными крупномасштабными наборами графических данных показывают, что мы можем масштабировать GraphGPT до более чем 400 миллионов параметров с повышением производительности. Но дальше улучшить результаты мы не можем. Возможно, это связано с недостаточностью наших экспериментов. Но возможно, что это вызвано внутренними ограничениями графических данных.
- Большие наборы данных графа (либо один большой граф, либо огромное количество маленьких графов) с атрибутами узла/ребра могут предоставить нам достаточно информации для обучения большой модели GraphGPT. Даже в этом случае одного набора данных графа может быть недостаточно, и нам может потребоваться собрать различные наборы данных графа для обучения одного GraphGPT.
- Проблема здесь в том, как определить универсальный токенизатор для атрибутов ребер/узлов из различных наборов данных графа.
Высококачественные графические данные. Что такое высококачественные графические данные для обучения GraphGPT для выполнения общих задач?
- Например, если мы хотим обучить одну модель для всех видов задач по пониманию и генерации молекул, какие данные нам следует использовать?
- В ходе нашего предварительного исследования мы добавили ZINC (4,6M) и CEPDB (2,3M) к предварительному обучению, и не обнаружили никаких преимуществ при точной настройке PCQM4M-v2 для задачи прогнозирования гомо-люмо-зазора. Возможные причины могут быть следующими:
- #structure# Графические шаблоны, лежащие в основе графа молекулы, относительно просты.
- Шаблоны графов, такие как цепочки или кольца из 5/6 узлов, очень распространены.
- В среднем на узел приходится по 2 ребра, что означает, что атомы имеют в среднем 2 связи.
- #семантика# Химические правила построения органических малых молекул просты: у атома углерода — 4 связи, у атома азота — 3 связи, у атома кислорода — 2 связи, у атома водорода — 1 связь и так далее. Проще говоря, пока у нас есть количество связей в атомах, мы можем генерировать любые молекулы.
- Правила структуры и семантики настолько просты, что даже модель среднего размера может учиться на наборе данных среднего размера. Так что добавление дополнительных данных не помогает. Мы предварительно обучаем малые/средние/базовые/большие модели, используя данные о 3,7 млн молекул, и их потери очень близки, что указывает на ограниченный выигрыш от увеличения размеров моделей на этапе предварительного обучения.
- Во-вторых, если мы хотим обучить одну модель для любых типов задач понимания структуры графа, какие данные нам следует использовать?
- Должны ли мы использовать настоящие графические данные из социальных сетей, сетей цитирования и т. д. или просто использовать синтетические графовые данные, такие как случайные графики Эрдеша-Реньи?
- Наши предварительные эксперименты показывают, что использование случайных графов для предварительного обучения GraphGPT помогает модели понять структуры графов, но это нестабильно. Мы подозреваем, что это связано с распределением структур графа на этапах предварительного обучения и точной настройки. Например, если у них одинаковое количество ребер на узел, одинаковое количество узлов, то парадигма предварительного обучения и точной настройки работает хорошо.
- #Универсальность# Итак, как научить модель GraphGPT универсально понимать любую структуру графа?
- Это возвращает нас к предыдущим вопросам о законе масштабирования: каковы подходящие и высококачественные данные графа для продолжения масштабирования GraphGPT, чтобы он мог хорошо выполнять различные графические задачи?
Несколько выстрелов: может ли GraphGPT получить возможность нескольких выстрелов?
- Если возможно, как спроектировать обучающие данные, чтобы GraphGPT мог их изучить?
- Судя по нашим предварительным экспериментам с набором данных PCQM4M-v2, наблюдается немалая способность к обучению! Но это не значит, что этого не может быть. Это может быть связано со следующими причинами:
- Модель недостаточно большая. Мы используем базовую модель с параметрами ~ 100 млн.
- Данных для обучения недостаточно. Мы используем только 3,7 млн молекул, что дает лишь ограниченное количество токенов для обучения.
- Формат обучающих данных не подходит для того, чтобы модель могла получить возможность выполнения нескольких выстрелов.
Обзор:

Мы предлагаем GraphGPT, новую модель обучения графов с помощью генеративных предобучаемых графовых эйлеровых преобразователей (GET) с самоконтролем. Сначала мы представляем GET, который состоит из базового преобразователя кодера/декодера и преобразования, которое превращает каждый граф или выбранный подграф в последовательность токенов, представляющих узел, ребро и атрибуты, обратимо с использованием эйлерова пути. Затем мы предварительно обучаем GET либо задаче прогнозирования следующего токена (NTP), либо запланированной задаче прогнозирования маскированного токена (SMTP). Наконец, мы настраиваем модель с помощью контролируемых задач. Эта интуитивно понятная, но эффективная модель обеспечивает превосходные или близкие результаты по сравнению с современными методами для задач на уровне графа, ребра и узла в крупномасштабном наборе молекулярных данных PCQM4Mv2, наборе данных белково-белковых ассоциаций ogbl-ppa. , набор сетевых данных цитирования ogbl-citation2 и набор данных ogbn-proteins из теста Open Graph Benchmark (OGB). Кроме того, генеративное предварительное обучение позволяет нам обучать GraphGPT до 2B+ параметров с постоянно увеличивающейся производительностью, что выходит за рамки возможностей GNN и предыдущих преобразователей графов.
График в последовательности
После преобразования эйлеризованных графов в последовательности существует несколько различных способов прикрепить к последовательностям атрибуты узлов и ребер. Мы называем эти методы short , long и prolonged .
Учитывая граф, мы сначала эйлеризуем его, а затем превращаем в эквивалентную последовательность. Затем мы циклически переиндексируем узлы.
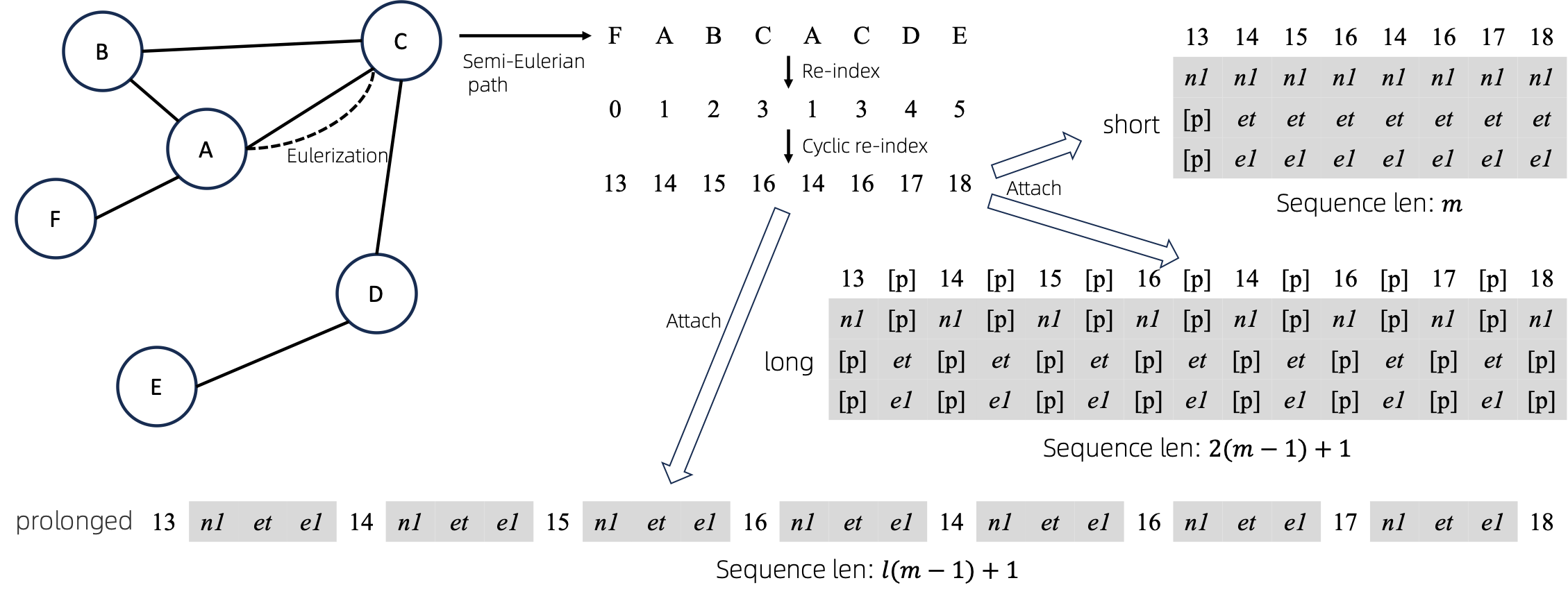
Предположим, что граф имеет один атрибут узла и один атрибут ребра, а затем выше показаны методы short , long и prolong .
На приведенных выше рисунках n1 , n2 и e1 представляют собой токены атрибутов узла и ребра, а [p] представляет токен заполнения.
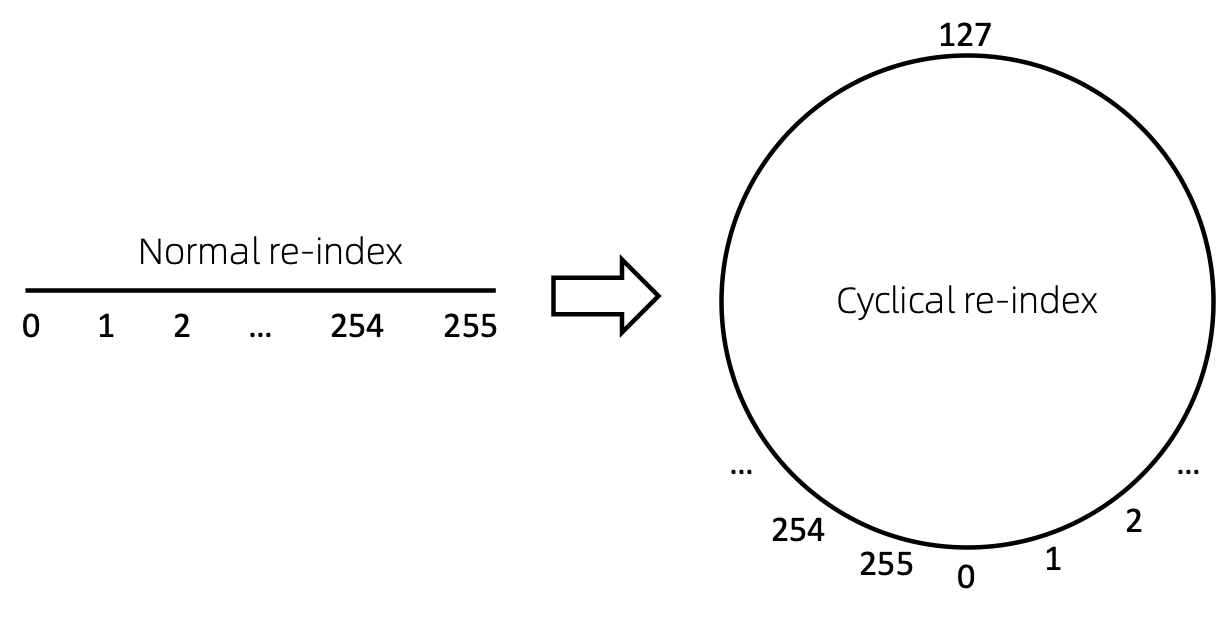
Циклическая переиндексация узла
Самый простой способ переиндексировать последовательность узлов — начать с 0 и постепенно добавлять 1. Таким образом, токены мелких индексов будут достаточно обучены, а крупных — нет. Чтобы преодолеть эту проблему, мы предлагаем cyclical re-index , который начинается со случайного числа в заданном диапазоне, скажем, [0, 255] и увеличивается на 1. После достижения границы, например, 255 , индекс следующего узла будет равен 0. .
Результаты
Устарело. Скоро будет обновлено.
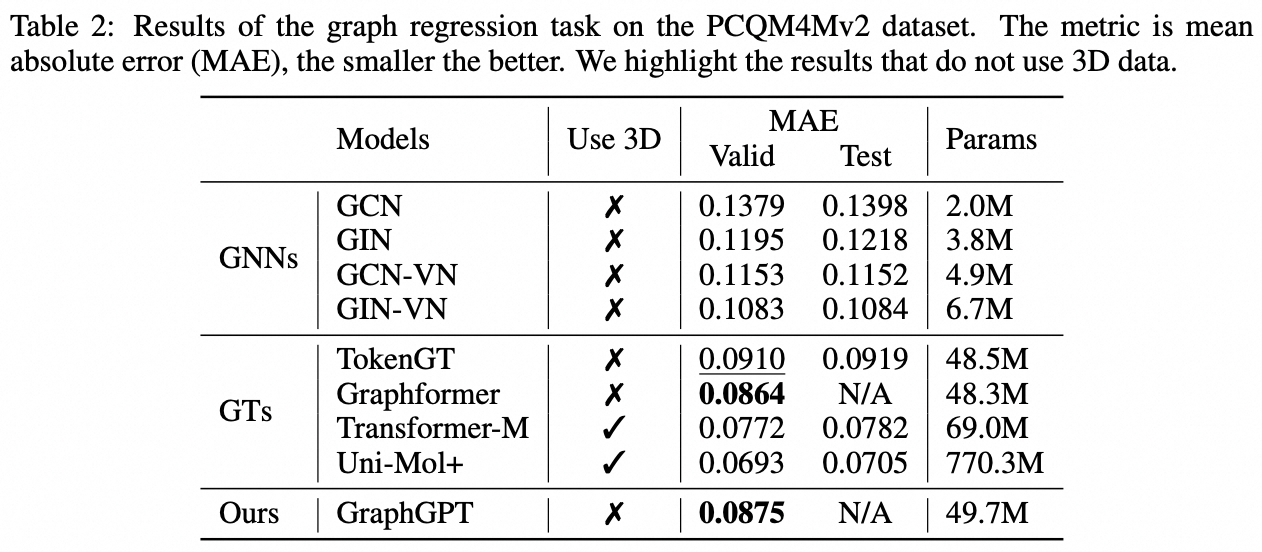
Задача уровня графа: набор данных PCQM4M-v2
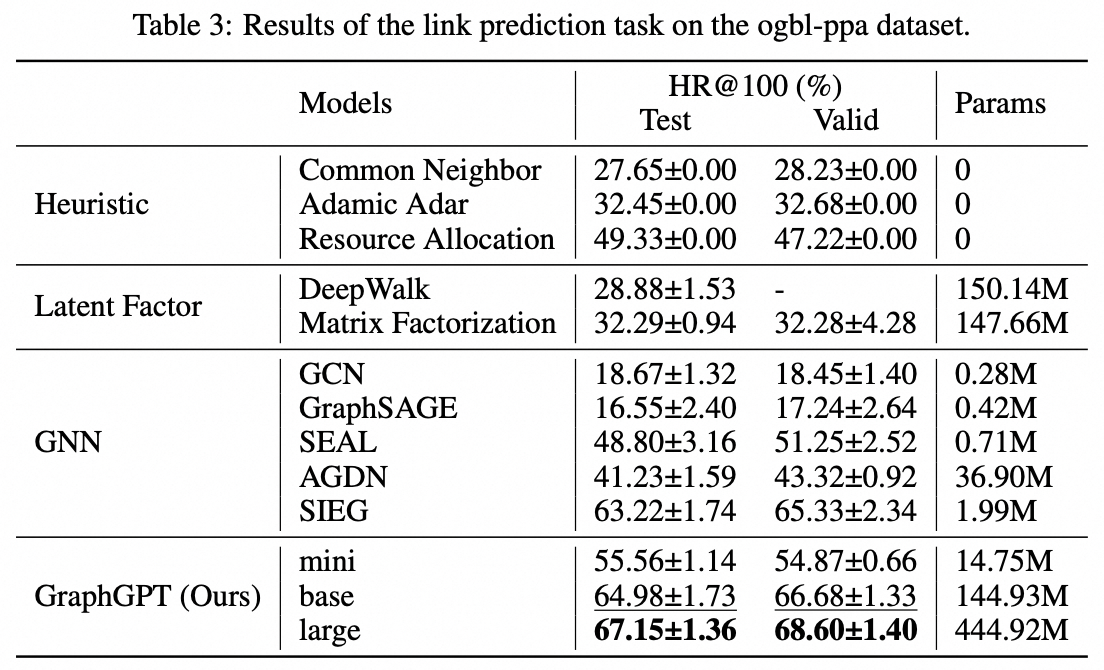
Задача краевого уровня: набор данных ogbl-ppa
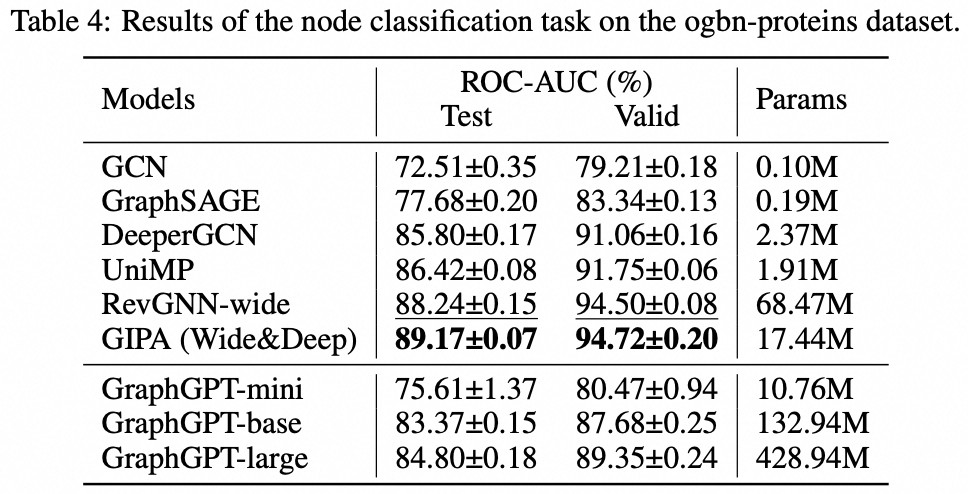
Задача уровня узла: набор данных ogbn-proteins
Установка
- Клонировать этот репозиторий
git clone https://github.com/alibaba/graph-gpt.git
- Установите зависимости в файле require.txt (с использованием Anaconda, протестировано с помощью py38, pytorch-1131 и CUDA-11.7, 11.8 и 12.1 на графических процессорах V100 и A100).
conda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc
Наборы данных
Наборы данных загружаются с помощью пакета Python ogb.
Когда вы запускаете скрипты в ./examples , набор данных будет загружен автоматически.
Однако набор данных PCQM4M-v2 огромен, и его загрузка и предварительная обработка могут быть проблематичными. Мы предлагаем cd ./src/utils/ и python dataset_utils.py загрузить и предварительно обработать набор данных отдельно.
Бегать
- Предварительное обучение: измените параметры в
./examples/graph_lvl/pcqm4m_v2_pretrain.sh , например, dataset_name , model_name , batch_size , workerCount и т. д., а затем запустите ./examples/graph_lvl/pcqm4m_v2_pretrain.sh для предварительного обучения модели с помощью PCQM4M-v2. набор данных.- Чтобы запустить пример игрушки, запустите напрямую
./examples/toy_examples/reddit_pretrain.sh .
- Точная настройка: измените параметры в
./examples/graph_lvl/pcqm4m_v2_supervised.sh , например dataset_name , model_name , batch_size , workerCount , pretrain_cpt и т. д., а затем запустите ./examples/graph_lvl/pcqm4m_v2_supervised.sh для точной настройки с последующими задачами. .- Чтобы запустить пример игрушки, запустите напрямую
./examples/toy_examples/reddit_supervised.sh .
Код Норма
Предварительная фиксация
- Подробности на официальном сайте
-
.pre-commit-config.yaml : создайте файл со следующим содержимым для Python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : black
-
pre-commit install : установите pre-commit в ваши git-хуки.- pre-commit теперь будет выполняться при каждом коммите.
- Каждый раз, когда вы клонируете проект с использованием предварительной фиксации, первым делом всегда следует выполнять
pre-commit install .
-
pre-commit run --all-files : запустить все перехватчики предварительной фиксации в репозитории -
pre-commit autoupdate : автоматическое обновление ваших хуков до последней версии -
git commit -n : проверки перед фиксацией можно отключить для конкретной фиксации с помощью команды
Цитирование
Если вы считаете эту работу полезной, пожалуйста, процитируйте следующие статьи:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}Контакт
Цифан Чжао ([email protected])
Искренне ценим ваши предложения по нашей работе!
Лицензия
Выпущено по лицензии MIT (см. LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


