YAYI2
1.0.0

[README] [?HF Repo] [?Веб-версия]
китайский | английский
[2024.03.28] Все модели и данные загружены в Magic Community.
[2023.12.22] Мы выпустили технический отчет YAYI 2: Многоязычные модели больших языков с открытым исходным кодом.
YAYI 2 — это новое поколение модели большого языка с открытым исходным кодом, разработанной Чжункэ Венге, включая версии Base и Chat, с размером параметра 30 байт. YAYI2-30B — это большая языковая модель, основанная на Transformer, которая использует высококачественный многоязычный корпус из более чем 2 триллионов токенов для предварительного обучения. Для общих и конкретных сценариев применения мы используем миллионы инструкций для точной настройки и применяем методы обучения с подкреплением обратной связи с участием человека, чтобы лучше согласовать модель с человеческими ценностями.
На этот раз модель с открытым исходным кодом — базовая модель YAYI2-30B. Мы надеемся способствовать развитию китайского сообщества предварительно обученных крупных моделей с открытым исходным кодом через открытый исходный код больших моделей Yayi и активно вносить в это свой вклад. Благодаря открытому исходному коду мы работаем с каждым партнером над созданием экосистемы крупных моделей Yayi.
Более подробную техническую информацию можно найти в нашем техническом отчете YAYI 2: Многоязычные модели больших языков с открытым исходным кодом.
| Имя набора данных | размер | ? Идентификация модели ВЧ | Скачать адрес | Логотип волшебной модели | Скачать адрес |
|---|---|---|---|---|---|
| Данные предварительной подготовки YAYI2 | 500 г | венге-исследования/yayi2_pretrain_data | Загрузка набора данных | венге-исследования/yayi2_pretrain_data | Загрузка набора данных |
| Название модели | длина контекста | ? Идентификация модели ВЧ | Скачать адрес | Логотип волшебной модели | Скачать адрес |
|---|---|---|---|---|---|
| ЯИ2-30Б | 4096 | венге-исследования/yayi2-30b | Загрузка модели | венге-исследования/yayi2-30b | Загрузка модели |
| YAYI2-30B-Чат | 4096 | венге-исследования/yayi2-30b-чат | Вскоре... |
Мы провели оценки на нескольких наборах эталонных данных, включая C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval и MBPP. Мы исследовали эффективность модели в понимании языка, предметных знаниях, математических рассуждениях, логических рассуждениях и генерации кода. Модель YAYI 2 демонстрирует значительное улучшение производительности по сравнению с моделями с открытым исходным кодом аналогичного размера.
| знание предмета | математика | логические рассуждения | код | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Модель | C-Eval(val) | ММЛУ | AGIEval | КММЛУ | GAOKAO-Скамейка | GSM8K | МАТЕМАТИКА | BBH | HumanEval | МБПП |
| 5 выстрелов | 5 выстрелов | 3/0-выстрел | 5 выстрелов | 0 выстрелов | 8/4 выстрела | 4 выстрела | 3 выстрела | 0 выстрелов | 3 выстрела | |
| МПТ-30Б | - | 46,9 | 33,8 | - | - | 15.2 | 3.1 | 38,0 | 25,0 | 32,8 |
| Сокол-40Б | - | 55,4 | 37,0 | - | - | 19,6 | 5,5 | 37,1 | 0,6 | 29,8 |
| ЛЛаМА2-34Б | - | 62,6 | 43,4 | - | - | 42,2 | 6.2 | 44,1 | 22,6 | 33,0 |
| Байчуань2-13Б | 59,0 | 59,5 | 37,4 | 61,3 | 45,6 | 52,6 | 10.1 | 49,0 | 17.1 | 30,8 |
| Квен-14Б | 71,7 | 67,9 | 51,9 | 70,2 | 62,5 | 61,6 | 25,2 | 53,7 | 32,3 | 39,8 |
| СтажерLM-20B | 58,8 | 62,1 | 44,6 | 59,0 | 45,5 | 52,6 | 7,9 | 52,5 | 25,6 | 35,6 |
| Аквила2-34Б | 98,5 | 76,0 | 43,8 | 78,5 | 37,8 | 50,0 | 17,8 | 42,5 | 0,0 | 41,0 |
| Йи-34Б | 81,8 | 76,3 | 56,5 | 82,6 | 68,3 | 67,6 | 15,9 | 66,4 | 26,2 | 38,2 |
| ЯИ2-30Б | 80,9 | 80,5 | 62,0 | 84,0 | 64,4 | 71,2 | 14,8 | 54,5 | 53,1 | 45,8 |
Мы провели оценку, используя исходный код, предоставленный репозиторием OpenCompass Github. Результаты оценки моделей сравнения мы перечисляем в списке OpenCompass по состоянию на 15 декабря 2023 г. Для других моделей, которые не участвовали в оценке на платформе OpenCompass, включая MPT, Falcon и LLaMa 2, мы приняли результаты, сообщенные LLaMA 2.
Мы приводим простые примеры, чтобы проиллюстрировать, как быстро использовать YAYI2-30B для вывода. Этот пример можно запустить на одном A100/A800.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envОбратите внимание, что для этого проекта требуется Python 3.8 или выше.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))При первом посещении модель необходимо скачать и загрузить, что может занять некоторое время.
Этот проект поддерживает тонкую настройку инструкций на основе глубокой скорости распределенной среды обучения. Настройте среду и выполните соответствующий сценарий, чтобы начать тонкую настройку полных параметров или тонкую настройку LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps Формат данных: см. data/yayi_train_example.json , который представляет собой стандартный файл "conversations" . Каждый фрагмент данных состоит из "system" и "conversations" , где "system" — это глобальная информация о настройке роли и может быть пустой строкой. "conversations" — это несколько раундов диалога между людьми и персонажами яи.
Инструкции по эксплуатации: Запустите следующую команду, чтобы начать полную настройку параметров модели Yayi. Эта команда поддерживает обучение на нескольких машинах и нескольких картах. Рекомендуется использовать аппаратную конфигурацию 16*A100 (80G) или выше.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True Или запустите через командную строку:
bash scripts/start.sh Обратите внимание: если вам нужно использовать шаблон ChatML для точной настройки инструкций, вы можете изменить --module training.trainer_yayi2 в команде на --module training.trainer_chatml ; если вам нужно настроить шаблон Chat, вы можете изменить его; система в шаблоне чата Trainer_chatml.py Специальные определения токенов для трех ролей: пользователя и помощника. Ниже приведен пример шаблона ChatML. Если этот или пользовательский шаблон используется во время обучения, он также должен быть согласованным во время вывода.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh На этапе предварительного обучения мы не только использовали данные Интернета для тренировки языковых способностей модели, но также добавляли общие выбранные данные и данные предметной области для повышения профессиональных навыков модели. Распределение данных следующее: 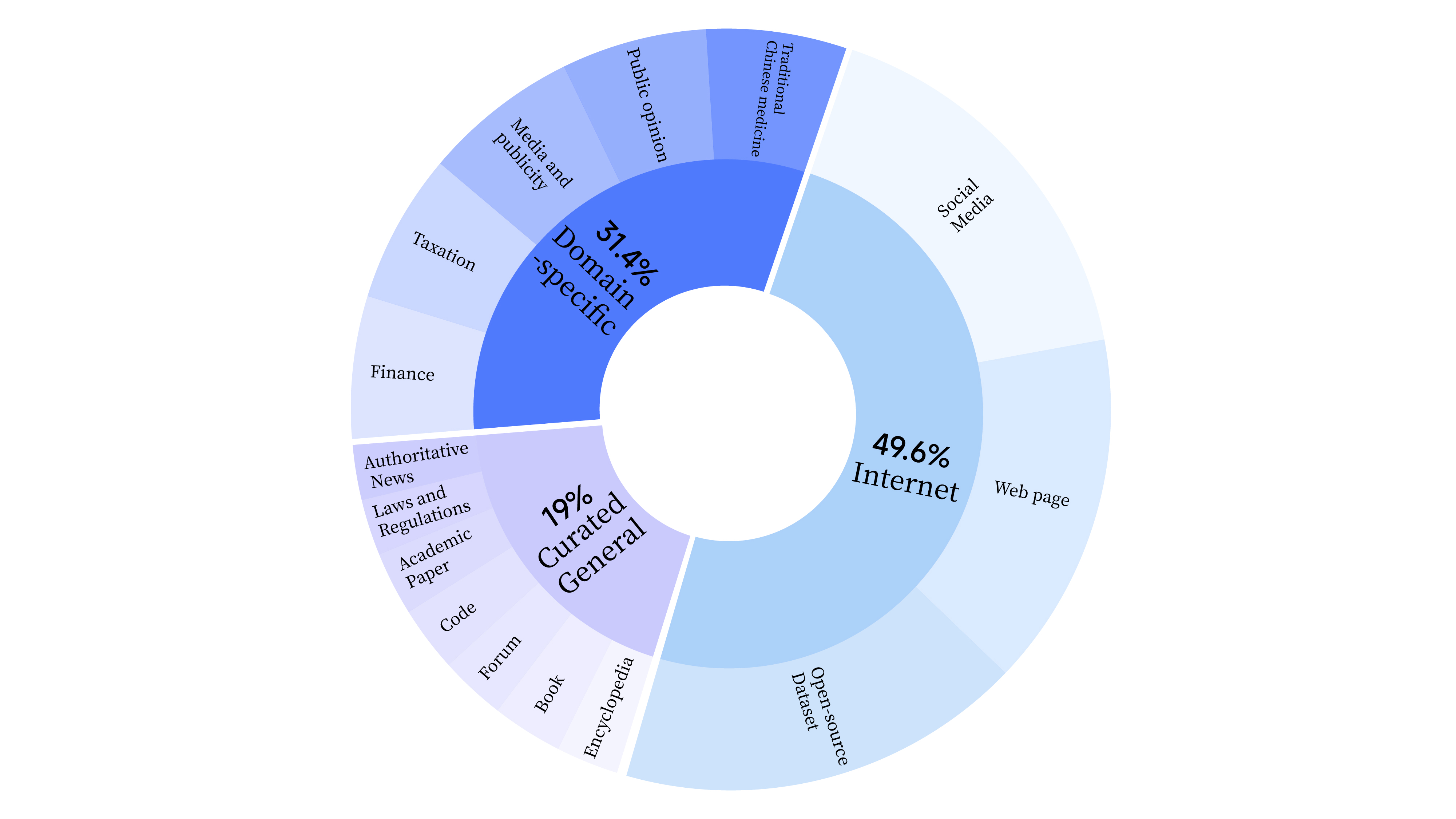
Мы построили набор конвейеров обработки данных для улучшения качества данных во всех аспектах, включая четыре модуля: стандартизация, эвристическая очистка, многоуровневая дедупликация и фильтрация токсичности. Всего мы собрали 240 ТБ необработанных данных, и после предварительной обработки осталось только 10,6 ТБ высококачественных данных. Общий процесс выглядит следующим образом: 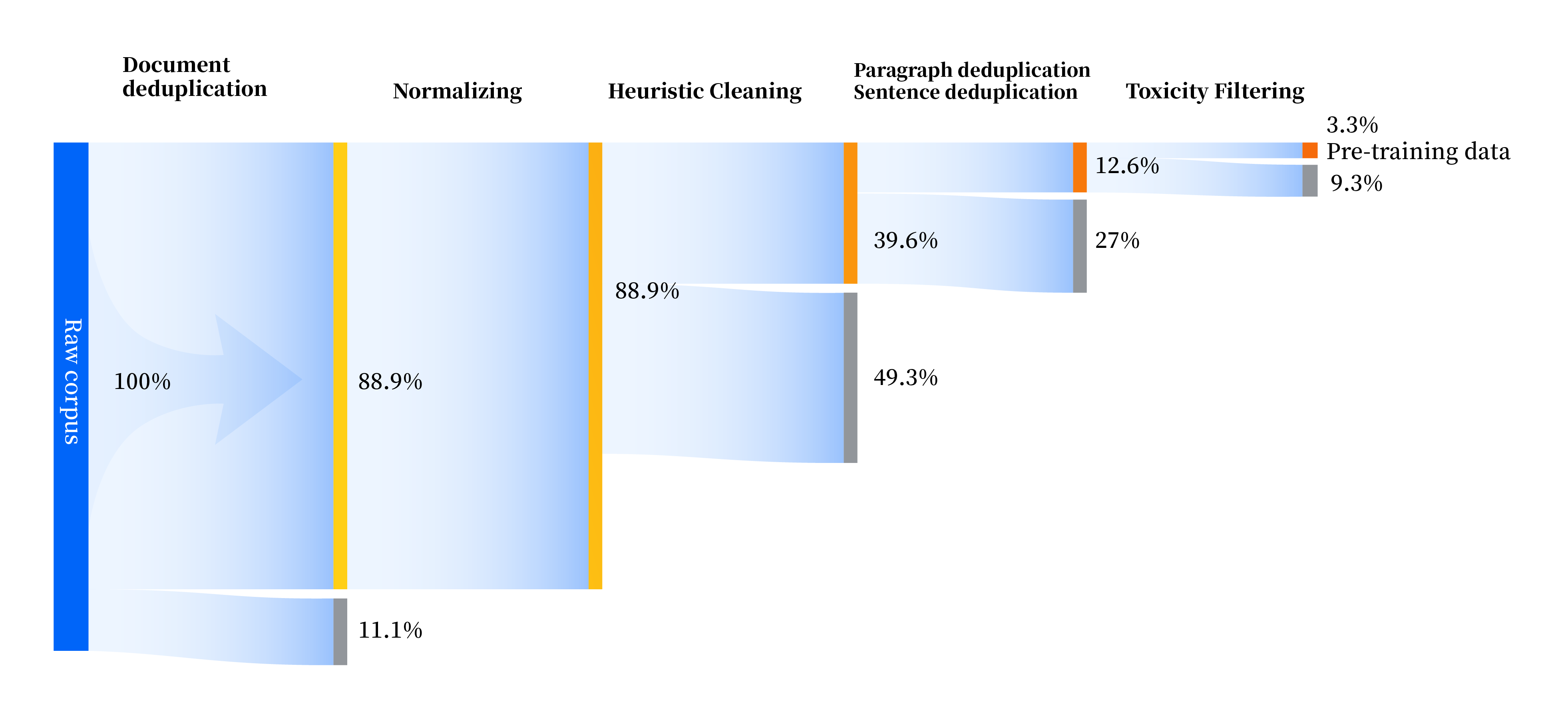

Кривая потерь модели YAYI 2 показана на рисунке ниже: 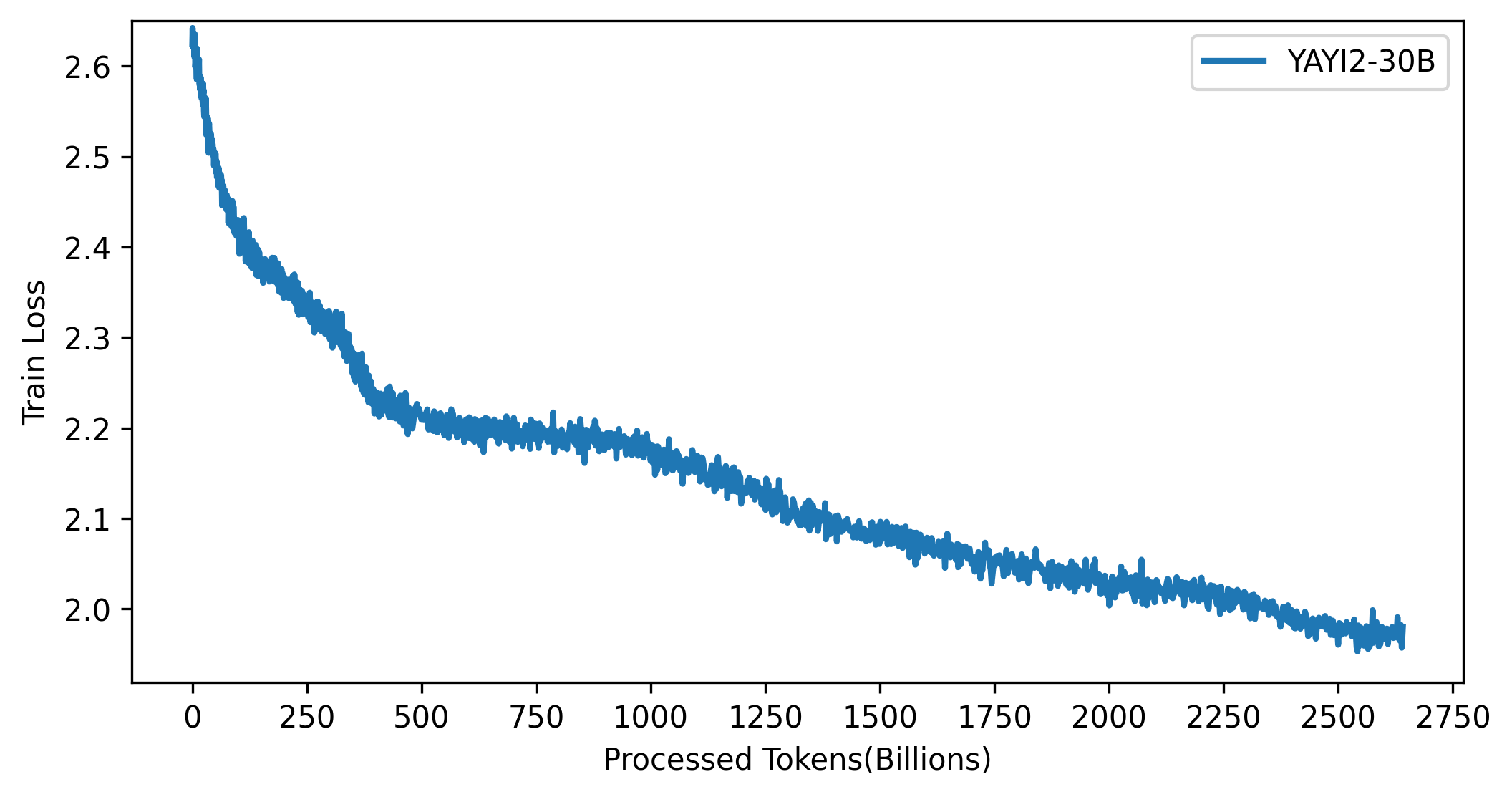
Код в этом проекте имеет открытый исходный код в соответствии с протоколом Apache-2.0. Использование сообществом модели и данных YAYI 2 должно соответствовать «Лицензионному соглашению сообщества Yayi YAYI 2». Если вам необходимо использовать модели серии YAYI 2 или их производные в коммерческих целях, заполните «Информацию о коммерческой регистрации модели YAYI 2» и отправьте ее по адресу [email protected]. Мы ответим в течение 3 рабочих дней после получения электронного письма. Проверка будет проводиться ежедневно. После прохождения проверки вы получите коммерческую лицензию. Пожалуйста, строго соблюдайте соответствующее содержание «Типового коммерческого лицензионного соглашения YAYI 2» во время использования. Благодарим за сотрудничество.
Если вы используете нашу модель в своей работе, пожалуйста, цитируйте нашу статью:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


