gen ai document sumarization
1.0.0
В этом проекте исследуется потенциал генеративных моделей искусственного интеллекта с открытым исходным кодом, особенно основанных на архитектуре Transformer, для автоматизации обобщения содержимого документов. Цель — оценить и применить существующие генеративные модели ИИ для анализа, понимания контекста и создания сводок для неструктурированных документов.
Для достижения этой цели я доработал две известные модели: t5-small и facebook/bart-base, сосредоточив внимание на повышении их эффективности обобщения.
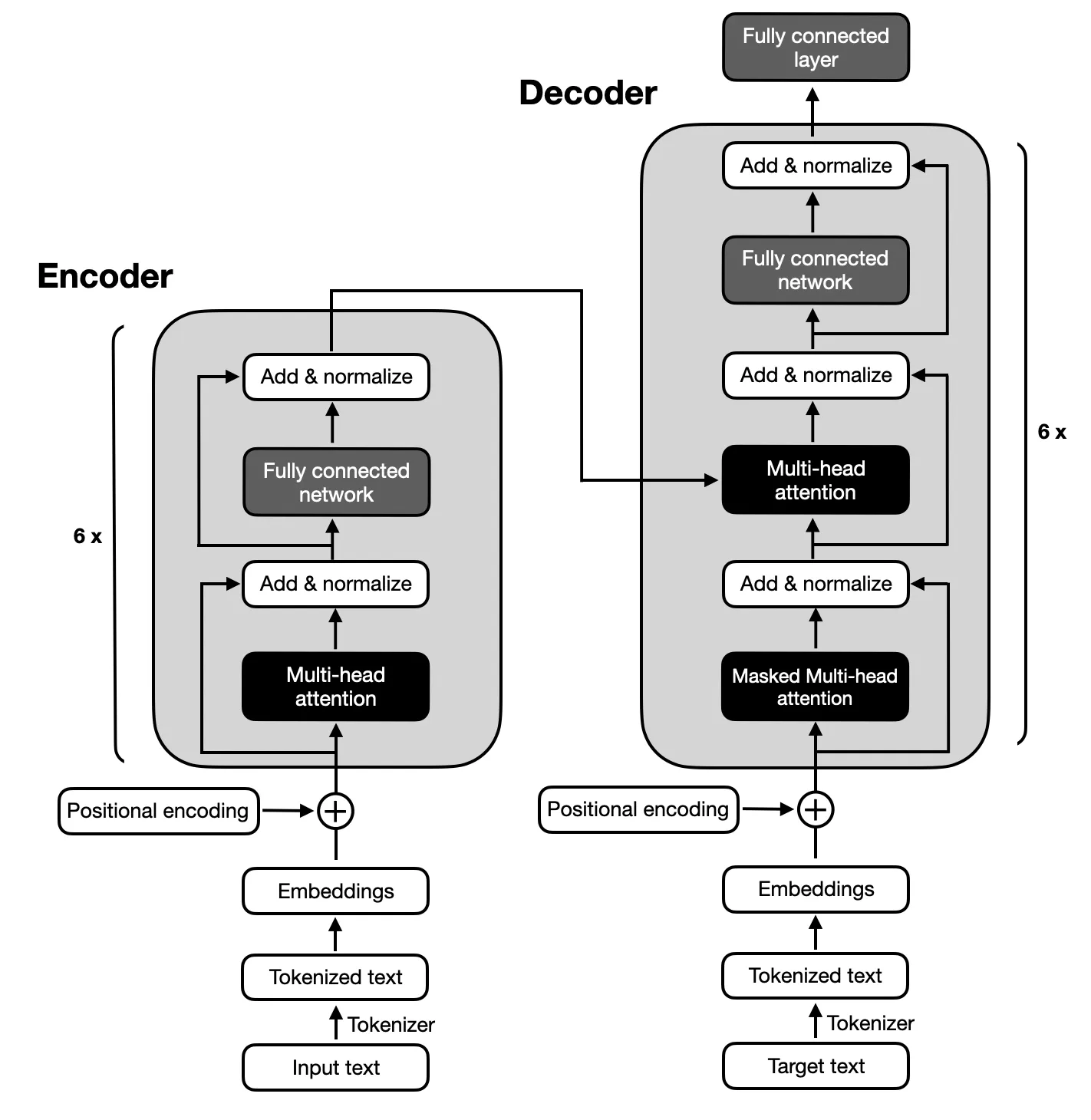
Основное внимание уделяется моделям кодера-декодера, следующим архитектуре, предложенной оригинальными Трансформерами, из-за сложного сопоставления между входными и выходными последовательностями, необходимыми для суммирования текста. Модели кодировщика-декодера умеют фиксировать отношения внутри этих последовательностей, что делает их подходящими для этой задачи.
Убедитесь, что в вашей системе установлен Python 3.x. Затем выполните следующие действия, чтобы настроить среду:
$ xcode-select --install
$ pip3 install --upgrade pip
$ pip3 install --upgrade setuptools$ pip3 install -r requirements.txt
python3 main.pyПроект состоит из шести основных этапов:
Набор данных, используемый для точной настройки моделей T5 и BART, представлял собой Большой набор патентных данных, который состоит из 1,3 миллиона патентных документов США, а также их абстрактных резюме, написанных человеком. Каждый документ в этом наборе данных отнесен к коду Совместной патентной классификации (CPC), охватывающему широкий спектр тем: от потребностей человека до физики и электричества. Такое разнообразие гарантирует, что модели сталкиваются с широким разнообразием языкового использования и технического жаргона, что имеет решающее значение для разработки надежных возможностей обобщения.
Большой набор патентных данных был выбран из-за его соответствия цели проекта по обобщению сложных документов. Патенты по своей сути носят подробный и технический характер, что делает их идеальным испытанием для проверки способности моделей сжимать информацию, сохраняя при этом основное содержание и контекст. Структурированный формат набора данных и наличие высококачественных сводок обеспечивают прочную основу для обучения и оценки эффективности моделей при создании точных и связных сводок.
Эффективность моделей оценивалась с использованием метрики ROUGE, подчеркивающей их способность генерировать резюме, тесно связанные с рефератами, написанными людьми. Модели BART и T5 были доработаны с использованием большого набора патентных данных с упором на достижение высококачественного абстрактного обобщения.
| Метрика | Ценить |
|---|---|
| Потеря оценки (Потеря оценки) | 1,9244 |
| Руж-1 | 0,5007 |
| Руж-2 | 0,2704 |
| Руж-Л | 0,3627 |
| Руж-Лсум | 0,3636 |
| Средняя продолжительность генерации (Gen Len) | 122.1489 |
| Время выполнения (секунды) | 1459,3826 |
| Выборок в секунду | 1.312 |
| Шагов в секунду | 0,164 |
| Метрика | Ценить |
|---|---|
| Потеря оценки (Потеря оценки) | 1,9984 |
| Руж-1 | 0,503 |
| Руж-2 | 0,286 |
| Руж-Л | 0,3813 |
| Руж-Лсум | 0,3813 |
| Средняя продолжительность генерации (Gen Len) | 151,918 |
| Время выполнения (секунды) | 714.4344 |
| Выборок в секунду | 2,679 |
| Шагов в секунду | 0,336 |


