WilmerAI
1.0.0
Это личный проект, который находится в стадии активной разработки. Он может содержать и, скорее всего, содержит ошибки, неполный код или другие непредвиденные проблемы. Таким образом, программное обеспечение предоставляется «как есть», без каких-либо гарантий.
WilmerAI отражает работу одного разработчика и усилия его личного времени и ресурсов; любые взгляды, методологии и т. д., содержащиеся в нем, являются его собственными и не должны отражаться на его работодателе.
WilmerAI — это сложная система промежуточного программного обеспечения, предназначенная для приема входящих запросов и выполнения различных задач перед их отправкой в API-интерфейсы LLM. Эта работа включает в себя использование модели большого языка (LLM) для категоризации приглашения и направления его в соответствующий рабочий процесс или обработку большого контекста (более 200 000 токенов) для создания меньшего и более управляемого приглашения, подходящего для большинства локальных моделей.
WilmerAI означает «Что, если языковые модели умело направляют все выводы?»
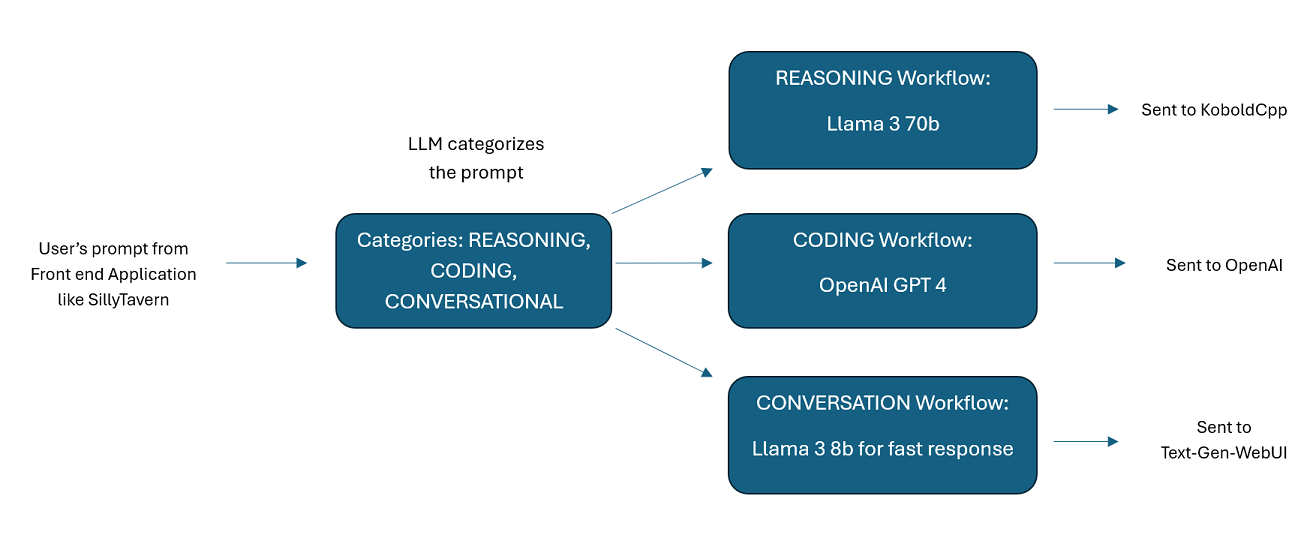
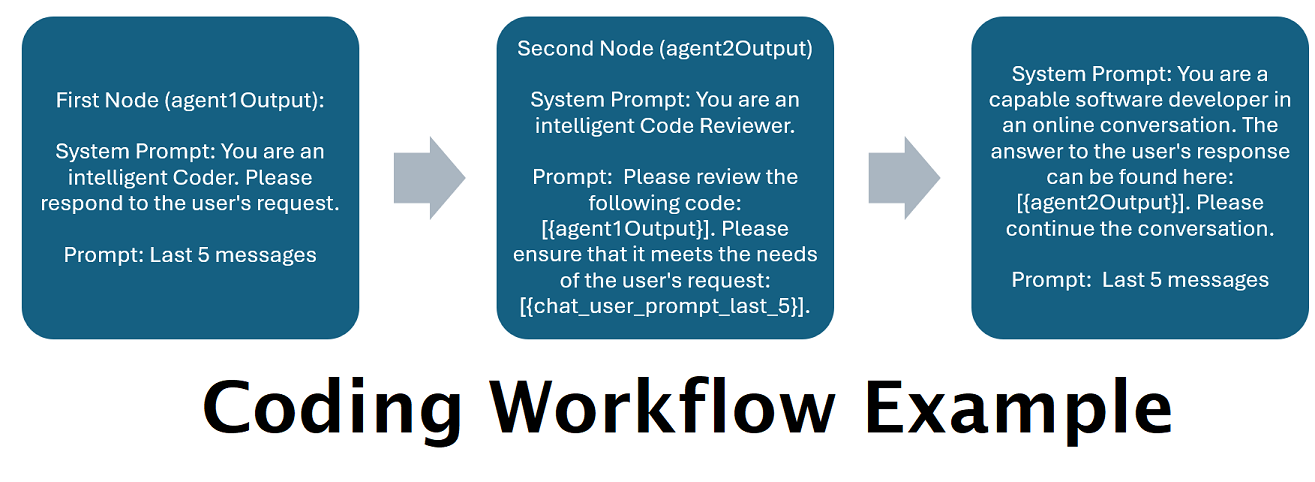
Помощники, работающие на базе нескольких LLM в тандеме : входящие запросы можно распределять по «категориям», при этом каждая категория управляется рабочим процессом. Каждый рабочий процесс может иметь столько узлов, сколько вам нужно, причем каждый узел работает на другом LLM. Например, если вы спросите своего помощника: «Можете ли вы написать мне игру «Змейка» на Python?», это можно отнести к категории КОДИРОВАНИЕ и перейти к вашему рабочему процессу кодирования. Первый узел этого рабочего процесса может попросить Codestral-22b (или ChatGPT 4o, если хотите) ответить на вопрос. Второй узел может попросить Deepseek V2 или Claude Sonnet проверить его код. Следующий узел может попросить Codestral еще раз дать окончательный ответ, а затем ответить вам. Независимо от того, представляет ли ваш рабочий процесс всего лишь одну модель, которая отвечает, потому что это ваш лучший программист, или же множество узлов различных LLM работают вместе для генерации ответа — выбор за вами.
Поддержка API Offline Wikipedia . У WilmerAI есть узел, который может выполнять вызовы OfflineWikipediaTextApi. Это означает, что у вас может быть категория, например «ФАКТИЧЕСКИЕ», которая просматривает ваше входящее сообщение, генерирует на его основе запрос, запрашивает API Википедии для связанной статьи и использует эту статью в качестве внедрения контекста RAG для ответа.
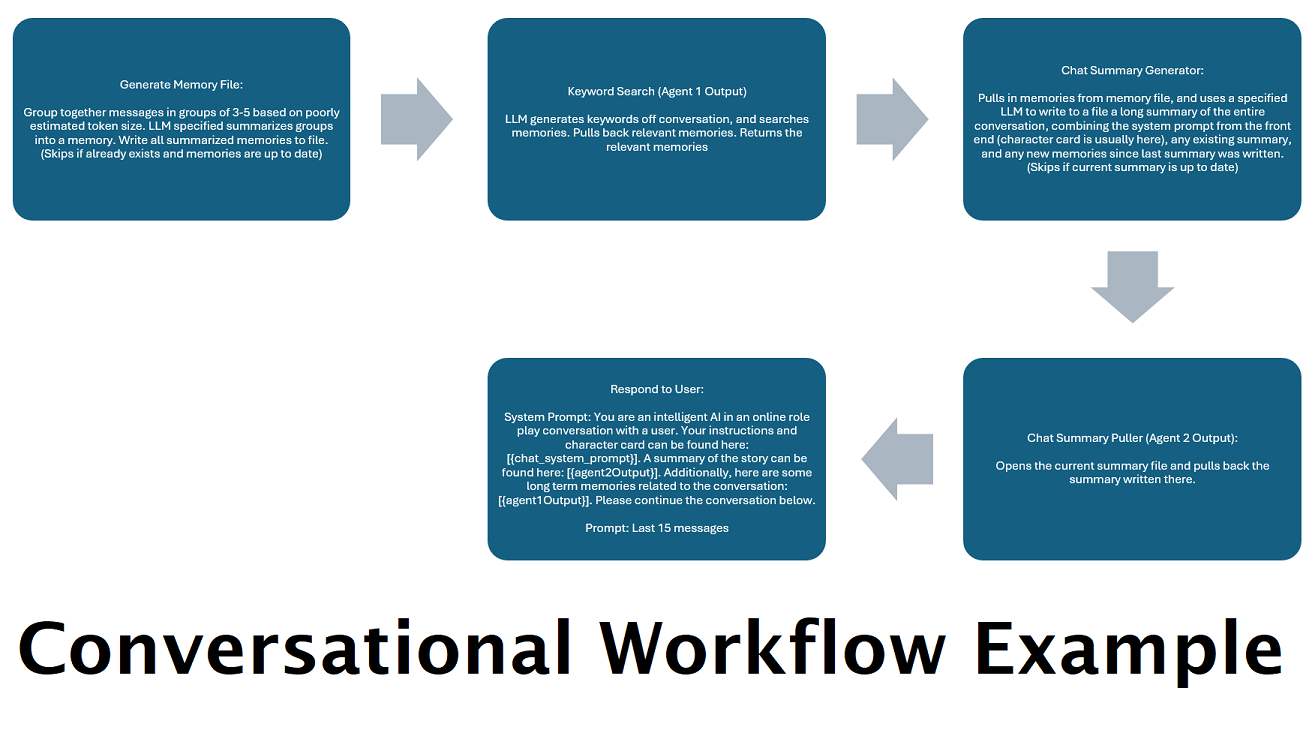
Постоянно генерируемые сводки чата для имитации «памяти» : узел «Сводка чата» будет генерировать «воспоминания», разбивая ваши сообщения на части, а затем суммируя их и сохраняя в файл. Затем он возьмет эти обобщенные фрагменты и сгенерирует постоянно обновляемую сводку всего разговора, которую можно будет извлечь и использовать в подсказке LLM. Результаты позволяют вам вести более 200 тысяч контекстных разговоров и относительно отслеживать сказанное, даже если количество подсказок LLM ограничено 5 тысячами контекстов или меньше.
Используйте несколько компьютеров для параллельной обработки воспоминаний и ответов . Если у вас есть два компьютера, на которых могут выполняться LLM, вы можете назначить один «ответчиком», а другой — ответственным за создание воспоминаний/сводок. Этот тип рабочего процесса позволяет вам продолжать общение со своим LLM во время обновления воспоминаний/сводки, продолжая при этом использовать существующие воспоминания. Это означает, что вам не нужно ждать обновления сводки, даже если вы поручите эту задачу большой и мощной модели, чтобы у вас были более качественные воспоминания. (См. пример пользовательской convo-role-dual-model )
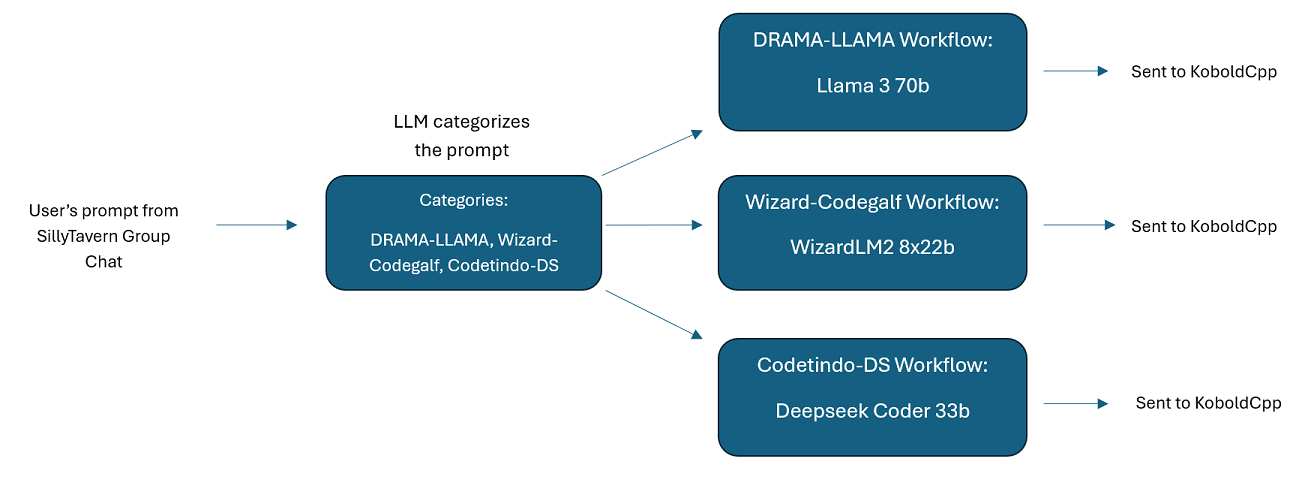
Групповые чаты с несколькими LLM в SillyTavern: при желании можно использовать Wilmer для группового чата в ST, где каждый персонаж является отдельным LLM (это делает лично автор). В DocsSillyTavern доступны примеры персонажей, разделились на две группы. Эти примеры символов/групп являются подмножествами более крупных групп, которые использует автор.
Функциональность промежуточного программного обеспечения: WilmerAI находится между интерфейсом, который вы используете для связи с LLM (например, SillyTavern, OpenWebUI или даже терминалом программы Python) и серверным API, обслуживающим LLM. Он может одновременно обрабатывать несколько серверных LLM.
Использование нескольких LLM одновременно: Пример настройки: SillyTavern -> WilmerAI -> несколько экземпляров KoboldCpp. Например, Wilmer может подключиться к Command-R 35b, Codestral 22b, Gemma-2-27b и использовать все это в своих ответах пользователю. Если выбранный вами LLM доступен через конечную точку v1/Completion или чат/Completion, или конечную точку Generate KoboldCpp, вы можете его использовать.
Настраиваемые пресеты : пресеты сохраняются в файле JSON, который вы можете легко настроить. Почти всеми пресетами можно управлять через json, включая имена параметров. Это означает, что вам не нужно ждать обновления Wilmer, чтобы использовать что-то новое. Например, DRY недавно вышел на KoboldCpp. Если этого не было в предустановленном json для Уилмера, вы можете просто добавить его и начать использовать.
Конечные точки API: он предоставляет конечные точки chat/Completions совместимые с OpenAI API, а также конечные точки v1/Completions для подключения через внешний интерфейс и может подключаться к любому типу на внутренней стороне. Это позволяет использовать сложные конфигурации, такие как подключение к Wilmer в качестве API v1/Completion, а затем подключение Wilmer к чату/Completion, v1/Completion KoboldCpp Генерировать конечные точки одновременно.
Шаблоны подсказок: поддерживаются шаблоны подсказок для конечных точек API v1/Completions . У WilmerAI также есть собственный шаблон подсказок для подключений из внешнего интерфейса через v1/Completions . Шаблон можно найти в папке «Документы» и он готов к загрузке в SillyTavern.

Имейте в виду, что рабочие процессы по своей природе могут выполнять множество вызовов конечной точки API в зависимости от того, как вы их настроили. WilmerAI не отслеживает использование токенов, не сообщает о точном использовании токенов через свой API и не предлагает никаких реальных способов мониторинга использования токенов. Поэтому, если отслеживание использования токенов важно для вас из соображений экономии, обязательно отслеживайте, сколько токенов вы используете, с помощью любой информационной панели, предоставляемой вам вашими API-интерфейсами LLM, особенно на ранних этапах, когда вы привыкаете к этому программному обеспечению.
Ваш LLM напрямую влияет на качество WilmerAI. Это проект, основанный на LLM, где потоки и результаты почти полностью зависят от подключенных LLM и их ответов. Если вы подключите Wilmer к модели, которая производит выходные данные более низкого качества, или если ваши настройки или шаблон приглашения имеют недостатки, общее качество Wilmer также будет намного ниже. В этом смысле он мало чем отличается от агентских рабочих процессов.
Хотя автор делает все возможное, чтобы сделать что-то полезное и качественное, это амбициозный сольный проект, и у него обязательно будут свои проблемы (тем более, что автор не является разработчиком Python по своей природе и в значительной степени полагался на искусственный интеллект, чтобы помочь ему добиться этого). далеко). Хотя он постепенно это понимает.
Уилмер предоставляет как конечную точку OpenAI v1/Completions, так и чат/Completions, что делает его совместимым с большинством интерфейсов. Хотя я в основном использовал это с SillyTavern, оно также может работать и с Open-WebUI.
Чтобы подключиться как дополнение текста в SillyTavern, выполните следующие действия (скриншот ниже взят из SillyTavern):
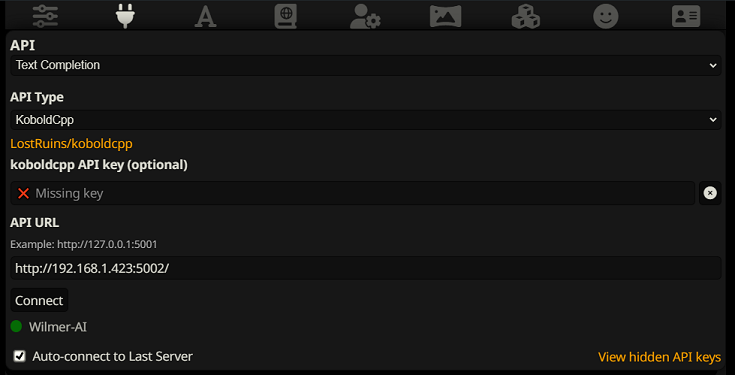
При использовании дополнений текста вам необходимо использовать формат шаблона подсказки, специфичный для WilmerAI. Импортируемый файл ST можно найти в Docs/SillyTavern/InstructTemplate . Шаблон контекста также включен, если вы хотите его использовать.
Образец инструкции выглядит следующим образом:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
Из SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
Между тегами нет ожидаемых символов новой строки или символов.
Убедитесь, что шаблон контекста включен (флажок над раскрывающимся списком).
Чтобы подключиться как завершение чата в SillyTavern, выполните следующие действия (скриншот ниже взят из SillyTavern):
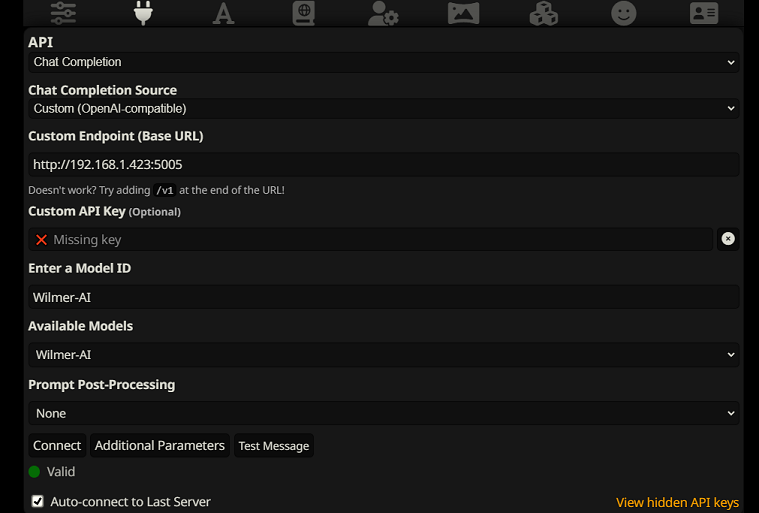
chatCompleteAddUserAssistant значение true. (Я не рекомендую устанавливать для обоих значение true одновременно. Используйте имена персонажей из SillyTavern, ИЛИ пользователя/помощника из Wilmer. В противном случае ИИ может запутаться.)Для любого типа подключения я рекомендую перейти к значку «A» в SillyTavern и выбрать «Включить имена» и «Принудительно использовать группы и персоны» в режиме инструкций, а затем перейти к крайнему левому значку (где находятся сэмплеры) и проверить « поток» в левом верхнем углу, а затем в правом верхнем углу проверьте «разблокировать» в контексте и перетащите его на 200 000+. Пусть Уилмер побеспокоится о контексте.
В настоящее время у Уилмера нет пользовательского интерфейса; все контролируется через файлы конфигурации JSON, расположенные в папке «Public». Эта папка содержит все необходимые конфигурации. При обновлении или загрузке новой копии WilmerAI вам следует просто скопировать папку «Public» в новую установку, чтобы сохранить настройки.
В этом разделе вы узнаете, как настроить Wilmer. Я разбил разделы на этапы; Я мог бы порекомендовать скопировать каждый шаг, один за другим, в LLM и попросить его помочь вам настроить этот раздел. Это может значительно облегчить задачу.
ВАЖНЫЕ ПРИМЕЧАНИЯ
Важно отметить три вещи относительно установки Уилмера.
А) Файлы предустановок на 100% настраиваются. Содержимое этого файла передается в API llm. Это связано с тем, что облачные API не поддерживают некоторые из различных предустановок, которые обрабатываются локальными API LLM. Таким образом, если вы используете OpenAI API или другие облачные сервисы, вызовы, вероятно, завершится неудачей, если вы используете одну из обычных локальных предустановок AI. См. предустановку «OpenAI-API» для примера того, что принимает openAI.
Б) Недавно я заменил все подсказки в Уилмере, чтобы перейти от второго лица к третьему. Для меня это дало довольно приличные результаты, и я надеюсь, что и для вас тоже.
C) По умолчанию во всех пользовательских файлах включена потоковая передача ответов. Вам либо нужно включить это в интерфейсе, вызывающем Wilmer, чтобы оба параметра совпадали, либо вам нужно зайти в Users/username.json и установить для Stream значение «false». Если у вас есть несоответствие, когда внешний интерфейс ожидает/не ожидает потоковой передачи, а ваш Wilmer ожидает обратного, скорее всего, на внешнем интерфейсе ничего не отобразится.
Установка Wilmer проста. Убедитесь, что у вас установлен Python; автор использовал программу с Python 3.10 и 3.12, и обе работают хорошо.
Вариант 1. Использование предоставленных сценариев
Для удобства Wilmer включает файл BAT для Windows и файл .sh для macOS. Эти сценарии создадут виртуальную среду, установят необходимые пакеты из requirements.txt и затем запустят Wilmer. Вы можете использовать эти сценарии для запуска Wilmer каждый раз.
.bat ..sh .ВАЖНО: Никогда не запускайте файл BAT или SH, не проверив его предварительно, так как это может быть рискованно. Если вы не уверены в безопасности такого файла, откройте его в Блокноте/TextEdit, скопируйте содержимое, а затем попросите своего LLM проверить его на наличие потенциальных проблем.
Вариант 2: Ручная установка
Альтернативно вы можете вручную установить зависимости и запустить Wilmer, выполнив следующие действия:
Установите необходимые пакеты:
pip install -r requirements.txtЗапустите программу:
python server.pyПредоставленные сценарии предназначены для оптимизации процесса путем настройки виртуальной среды. Однако вы можете смело игнорировать их, если предпочитаете установку вручную.
ПРИМЕЧАНИЕ . При запуске файла bat, файла sh или файла Python все три теперь принимают следующие ДОПОЛНИТЕЛЬНЫЕ аргументы:
Так, например, рассмотрим следующие возможные прогоны:
bash run_macos.sh (будет использовать пользователя, указанного в _current-user.json, конфигурации в «Public», журналы в «logs»)bash run_macos.sh --User "single-model-assistant" (по умолчанию будет общедоступным для конфигураций и «log» для журналов)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (для "логов" будет использоваться только значение по умолчанию)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"Эти необязательные аргументы позволяют пользователям запускать несколько экземпляров WilmerAI, каждый экземпляр использует другой профиль пользователя, входит в систему в другом месте и при желании указывает конфигурации в другом месте.
В папке Public/Configs вы найдете ряд папок, содержащих файлы json. Две из них, которые вас больше всего интересуют, — это папка Endpoints и папка Users .
ПРИМЕЧАНИЕ. Узлы рабочего процесса Factual пользователей с assistant-single-model , assistant-multi-model и group-chat-example попытаются использовать проект OfflineWikipediaTextApi для извлечения полных статей Википедии в RAG. Если у вас нет этого API, в рабочем процессе не должно возникнуть никаких проблем, но лично я использую этот API, чтобы улучшить фактические ответы, которые я получаю. Вы можете указать IP-адрес вашего API в пользовательском формате JSON по вашему выбору.
Сначала выберите, какого пользователя шаблона вы хотите использовать:
Assistant-single-model : этот шаблон предназначен для одной небольшой модели, используемой на всех узлах. Он также имеет маршруты для множества различных типов категорий и использует соответствующие предустановки для каждого узла. Если вам интересно, почему существуют маршруты для разных категорий, когда есть только одна модель: это для того, чтобы вы могли дать каждой категории свои собственные пресеты, а также для того, чтобы вы могли создавать для них собственные рабочие процессы. Возможно, вы хотите, чтобы программист выполнил несколько итераций для проверки себя или чтобы продумал все в несколько этапов.
Assistant-multi-model : этот шаблон предназначен для одновременного использования множества моделей. Глядя на конечные точки этого пользователя, вы можете видеть, что каждая категория имеет свою конечную точку. Ничто не мешает вам повторно использовать один и тот же API для нескольких категорий. Например, вы можете использовать Llama 3.1 70b для кодирования, математических вычислений и рассуждений, а Command-R 35b 08-2024 — для категоризации, разговоров и фактов. Не думайте, что вам НУЖНО 10 разных моделей. Это просто для того, чтобы вы могли принести столько, сколько захотите. Этот пользователь использует соответствующие настройки для каждого узла в рабочих процессах.
convo-roleplay-single-model : этот пользователь использует единую модель с настраиваемым рабочим процессом, который хорош для разговоров и должен подходить для ролевых игр (ожидает обратной связи для настройки при необходимости). Это обходит всю маршрутизацию.
convo-roleplay-dual-model : этот пользователь использует две модели с настраиваемым рабочим процессом, который хорош для разговоров и должен подойти для ролевых игр (ожидает обратной связи для настройки при необходимости). Это обходит всю маршрутизацию. ПРИМЕЧАНИЕ . Этот рабочий процесс лучше всего работает, если у вас есть 2 компьютера, на которых можно запускать LLM. При текущих настройках этого пользователя, когда вы отправляете сообщение Уилмеру, вам ответит модель ответчика (компьютер 1). Тогда в этой точке рабочий процесс применит «блокировку рабочего процесса». Модель сводки памяти/чата (компьютер 2) затем начнет обновлять воспоминания и сводку разговора, которая передается отвечающему, чтобы помочь ему запомнить материал. Если вы отправите еще одно приглашение во время записи воспоминаний, ответчик (компьютер 1) возьмет все существующее резюме и ответит вам. Блокировка рабочего процесса не позволит вам повторно войти в раздел новых воспоминаний. Это означает, что вы можете продолжать разговаривать со своей моделью респондента, пока пишутся новые воспоминания. Это ОГРОМНОЕ повышение производительности. Я попробовал это, и время отклика для меня было потрясающим. Без этого я получаю ответы за 30 секунд 3-5 раз, а потом внезапно приходится ждать 2 минуты, чтобы сгенерировать воспоминания. При этом каждое сообщение длится 30 секунд каждый раз на Llama 3.1 70b в моей Mac Studio.
group-chat-example : Этот пользователь является примером моих личных групповых чатов. Включенные персонажи и группы — это настоящие персонажи и настоящие группы, которые я использую. Вы можете найти примеры символов в папке Docs/SillyTavern . Это символы, совместимые с SillyTavern, которые вы можете импортировать непосредственно в эту программу или любую программу, поддерживающую типы импорта символов .png. У персонажей команды разработчиков есть только один узел на рабочий процесс: они просто отвечают вам. Персонажи консультативной группы имеют 2 узла на каждый рабочий процесс: первый узел генерирует ответ, а второй узел обеспечивает соблюдение «персоны» персонажа (конечная точка, отвечающая за это, является конечной точкой businessgroup-speaker ). Персонажи группового чата очень помогают разнообразить получаемые ответы, даже если вы используете только одну модель. Однако я стремлюсь использовать разные модели для каждого персонажа (но повторно использовать модели между группами; так, например, у меня есть персонаж модели Llama 3.1 70b в каждой группе).
После того, как вы выбрали пользователя, которого хотите использовать, необходимо выполнить несколько шагов:
Обновите конечные точки для вашего пользователя в разделе Public/Configs/Endpoints. Примеры персонажей рассортированы по папкам для каждого. Папка конечной точки пользователя указана в нижней части файла user.json. Вам потребуется заполнить каждую конечную точку соответствующим образом для используемых вами LLM. Вы можете найти несколько примеров конечных точек в папке _example-endpoints .
Вам нужно будет установить текущего пользователя. Это можно сделать при запуске файла bat/sh/py, используя аргумент --User, или в Public/Configs/Users/_current-user.json. Просто укажите имя пользователя в качестве текущего пользователя и сохраните.
Вам нужно будет открыть свой пользовательский json-файл и просмотреть параметры. Здесь вы можете указать, хотите ли вы потоковую передачу или нет, можете установить IP-адрес для вашего автономного вики-API (если вы его используете), указать, куда вы хотите, чтобы ваши воспоминания/файлы сводных данных находились во время потоков DiscountId, а также указать, куда вы хотите хочу, чтобы база данных sqllite работала, если вы используете блокировки рабочего процесса.
Вот и все! Запустите Уилмера, подключитесь к нему, и все будет в порядке.
Сначала мы настроим конечные точки и модели. В папке Public/Configs вы должны увидеть следующие подпапки. Давайте пройдемся по тому, что вам нужно.
Эти файлы конфигурации представляют конечные точки LLM API, к которым вы подключены. Например, следующий файл JSON SmallModelEndpoint.json определяет конечную точку:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}Эти файлы конфигурации представляют различные типы API, которые вы можете использовать при использовании Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} Эти файлы определяют шаблон приглашения для модели. Рассмотрим следующий пример: llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} Эти шаблоны применяются ко всем вызовам конечной точки v1/Completion. Если вы предпочитаете не использовать шаблон, существует файл _chatonly.json , который разбивает сообщения только символами новой строки.
Создание и активация пользователя включает в себя четыре основных шага. Следуйте инструкциям ниже, чтобы настроить нового пользователя.
Сначала в папке Users создайте файл JSON для нового пользователя. Самый простой способ сделать это — скопировать существующий пользовательский файл JSON, вставить его как дубликат, а затем переименовать. Вот пример пользовательского файла JSON:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 , что делает его видимым в вашей сети, если он запущен на другом компьютере. Поддерживается запуск нескольких экземпляров Wilmer на разных портах.true , маршрутизатор отключается, и все запросы отправляются только в указанный рабочий процесс, что делает его единственным экземпляром рабочего процесса Wilmer.customWorkflowOverride имеет значение true .Routing без расширения .json .DiscussionId .chatCompleteAddUserAssistant равно true .DataFinder группы примеров. Затем обновите файл _current-user.json , чтобы указать, какого пользователя вы хотите использовать. Сопоставьте имя нового пользовательского файла JSON без расширения .json .
ПРИМЕЧАНИЕ . Вы можете игнорировать это, если вместо этого хотите использовать аргумент --User при запуске Wilmer.
Создайте JSON-файл маршрутизации в папке Routing . Этот файл можно назвать как угодно. Обновите свойство routingConfig в пользовательском файле JSON, указав это имя без расширения .json . Вот пример файла конфигурации маршрутизации:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json , запускаемого при выборе категории. В папке Workflow создайте новую папку, соответствующую имени пользователя из папки Users . Самый быстрый способ сделать это — скопировать существующую папку пользователя, продублировать ее и переименовать.
Если вы решите не вносить других изменений, вам придется пройти рабочие процессы и обновить конечные точки, чтобы они указывали на нужную вам конечную точку. Если вы используете пример рабочего процесса, добавленного с помощью Wilmer, то здесь у вас все должно быть в порядке.
В папке «Public» у вас должно быть:
Рабочие процессы в этом проекте изменяются и контролируются в папке Public/Workflows в папке рабочих процессов вашего пользователя. Например, если вашего пользователя зовут socg и у вас есть файл socg.json в папке Users , то в рабочих процессах у вас должна быть папка Workflows/socg .
Вот пример того, как может выглядеть JSON рабочего процесса:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]Вышеупомянутый рабочий процесс состоит из узлов разговора. Оба узла делают одну простую вещь: отправляют сообщение LLM, указанному в конечной точке.
title . Полезно называть эти окончания «Один», «Два» и т. д., чтобы отслеживать выходные данные агента. Выходные данные первого узла сохраняются в {agent1Output} , второго — в {agent2Output} и так далее.Endpoints без расширения .json .Presets без расширения .json .false (см. первый пример узла выше). Если вы отправляете запрос, установите для него значение true (см. второй пример узла выше). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
Вы можете использовать несколько переменных в этих подсказках. Они будут соответствующим образом заменены во время выполнения:
{chat_user_prompt_last_one} : Последнее сообщение в разговоре, без тегов шаблона приглашения.{templated_user_prompt_last_one} : последнее сообщение в разговоре, завернутое в соответствующие теги шаблона приглашения пользователя/помощника.{chat_system_prompt} : Системная подсказка отправлена с передней части. Часто содержит карту персонажа и другую важную информацию.{templated_system_prompt} : Системная подсказка с передней части, завернутая в соответствующий тег шаблона системного шаблона.{agent#Output} : # заменяется номером, который вы хотите. Каждый узел генерирует вывод агента. Первый узел всегда {agent2Output} , и каждый последующий узел увеличивает 1 {agent1Output}{category_colon_descriptions} : вытаскивает категории и описания из вашего файла Routing JSON.{categoriesSeparatedByOr} : тянет имена категории, разделенные "или".[TextChunk] : специальная переменная, уникальная для параллельного процессора, вероятно, не часто используется.Примечание. Для более глубокого понимания того, как работают воспоминания, см. В разделе «Понимание воспоминаний»
Этот узел будет привлекать к нему количество воспоминаний (или последних сообщений, если не присутствует в обсуждении) и добавит между ними пользовательский разделитель. Поэтому, если у вас есть файл памяти с 3 воспоминаниями, и выберите разделитель « n ---------- n», то вы можете получить следующее:
This is the first memory
---------
This is the second memory
---------
This is the third memory
Объединение этого узла с кратким изложением чата может позволить LLM получить не только суммированную разбивку всего разговора в целом, но и список всех воспоминаний, из которых были построены резюме, которая может содержать более подробную и детальную информацию о это. Отправка оба из них вместе с последними 15-20 сообщениями может создать впечатление постоянной и постоянной памяти всего чата до самых последних сообщений. Специальная помощь, чтобы создать хорошие подсказки для создания воспоминаний, может помочь обеспечить захватываемые детали, о которых вы заботитесь, в то время как менее актуальные детали игнорируются.
Этот узел не будет генерировать новые воспоминания; Это так, чтобы блокировки рабочего процесса можно было соблюдать, если вы используете их на многокомпетентной настройке. В настоящее время лучший способ создать воспоминания - это узел FullChatsummary.


