hands on llms
1.0.0
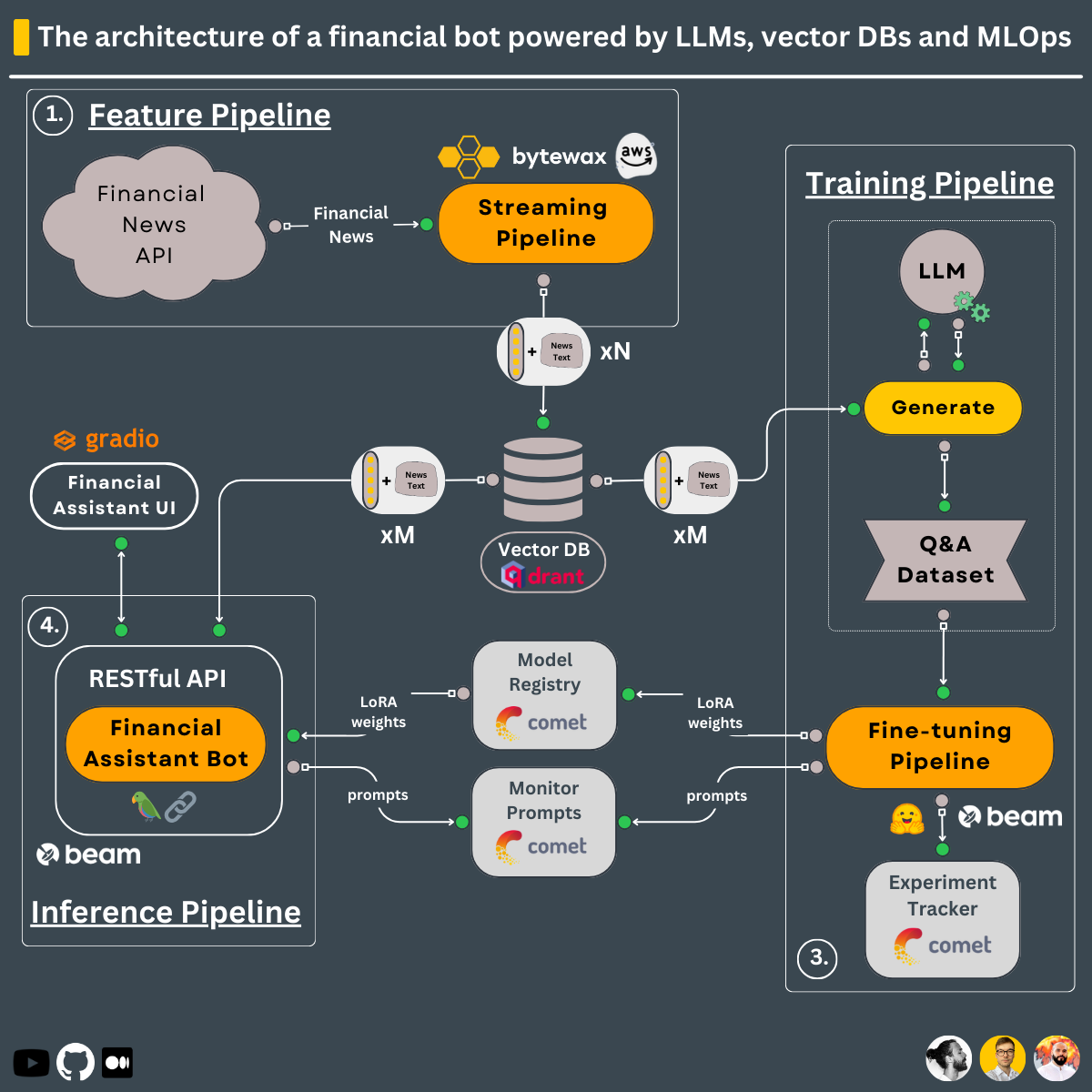
Используя трехконвейерную конструкцию, это то, что вы научитесь строить в этом курсе ↓
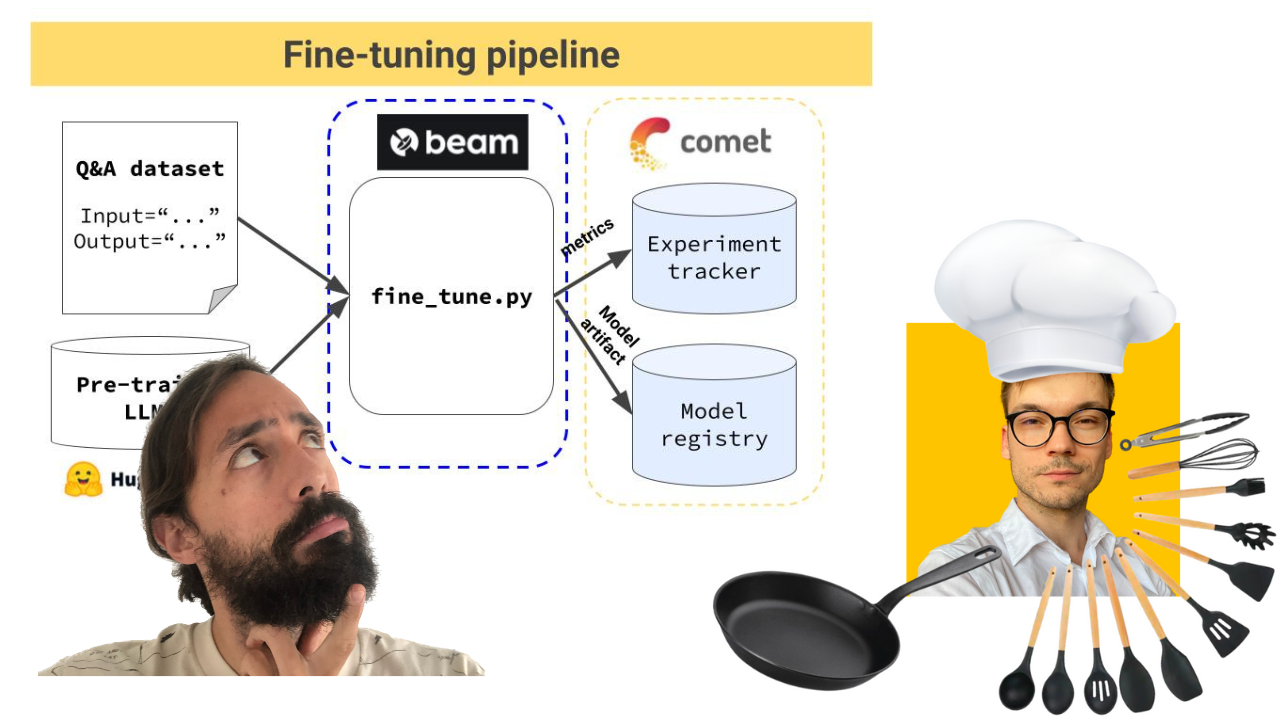
Тренинговый конвейер, который:
Конвейер обучения развертывается с использованием Beam в качестве бессерверной инфраструктуры графического процессора.
-> Находится в каталоге modules/training_pipeline .
Примечание. Не волнуйтесь, если у вас нет минимальных требований к оборудованию. Мы покажем вам, как развернуть конвейер обучения в бессерверной инфраструктуре Beam и обучать LLM там.
Конвейер функций в реальном времени, который:
Конвейер потоковой передачи автоматически развертывается на компьютере AWS EC2 с помощью конвейера CI/CD, встроенного в действия GitHub.
-> Находится в каталоге modules/streaming_pipeline .
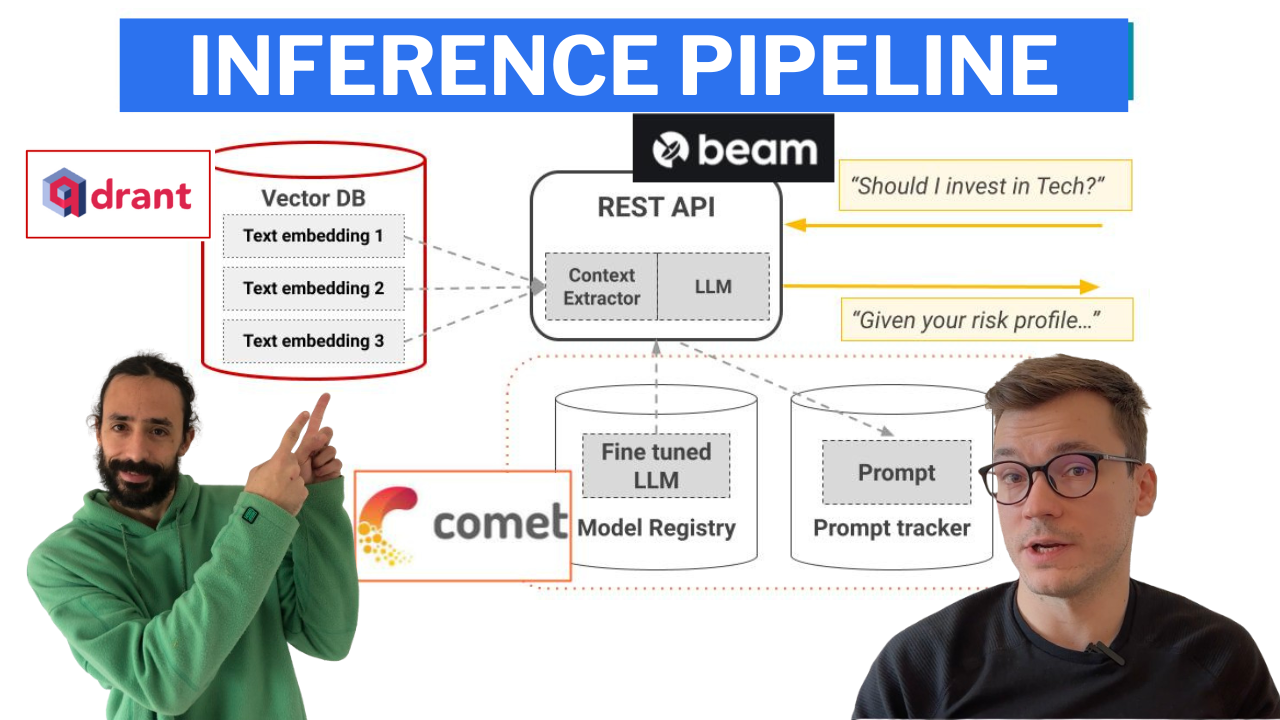
Конвейер вывода, использующий LangChain для создания цепочки, которая:
Конвейер вывода развертывается с использованием Beam в качестве бессерверной инфраструктуры графического процессора и RESTful API. Кроме того, для демонстрационных целей он заключен в пользовательский интерфейс, реализованный в Gradio.
-> Находится в каталоге modules/financial_bot .
Примечание. Не волнуйтесь, если у вас нет минимальных требований к оборудованию. Мы покажем вам, как развернуть конвейер вывода в бессерверной инфраструктуре Beam и вызвать LLM оттуда.
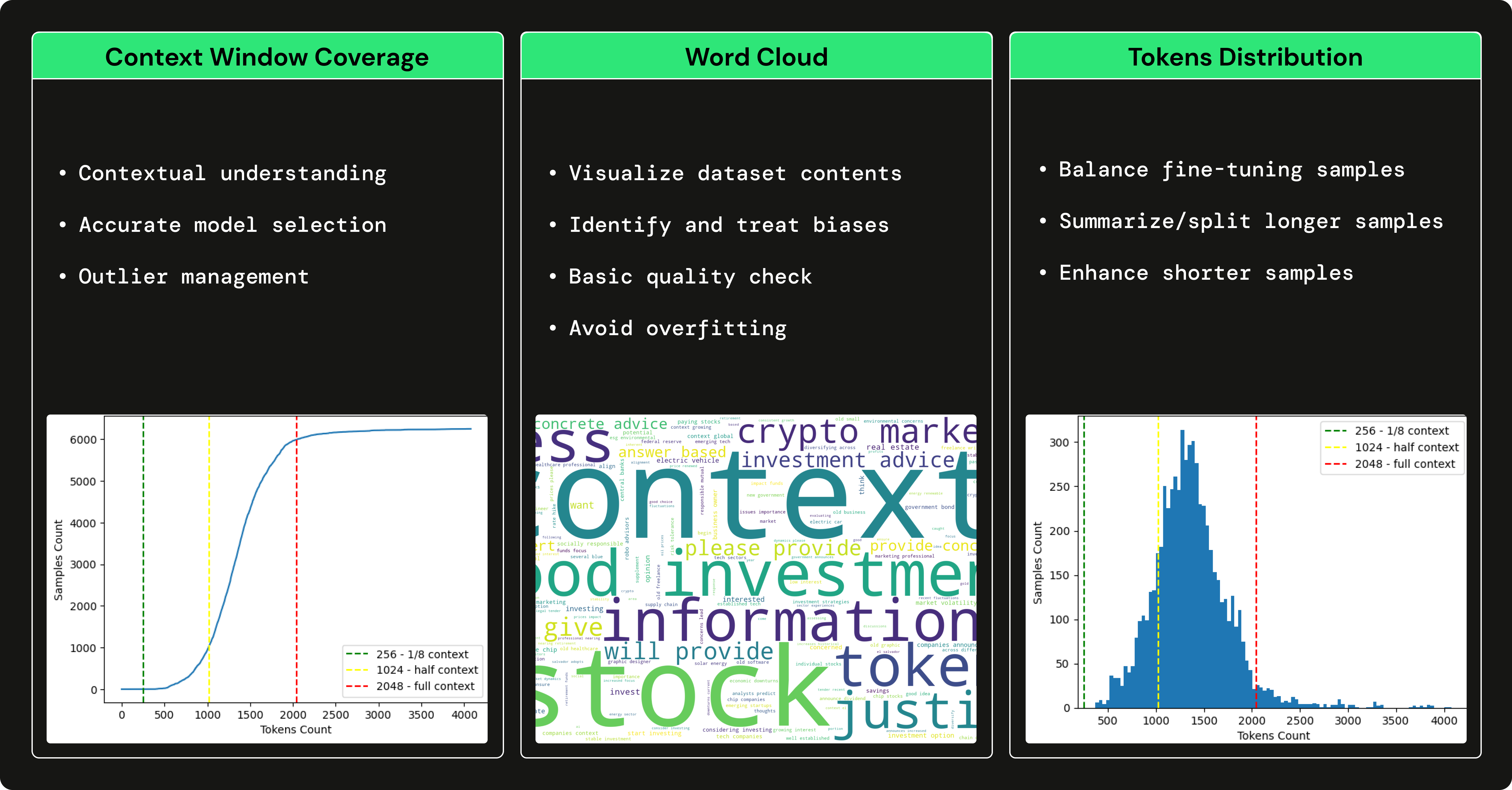
Мы использовали GPT3.5 для создания набора финансовых данных вопросов и ответов, чтобы настроить нашу LLM с открытым исходным кодом, чтобы она специализировалась на использовании финансовых терминов и ответах на финансовые вопросы. Использование большого LLM, такого как GPT3.5 для создания набора данных, который обучает меньший LLM (например, Falcon 7B), называется точной настройкой с помощью дистилляции .
→ Чтобы понять, как мы создали набор финансовых данных вопросов и ответов, прочтите эту статью, написанную Пау Лабартой.
→ Чтобы увидеть полный анализ набора финансовых данных вопросов и ответов, ознакомьтесь с подразделом dataset_anaанализ курса, написанного Александру Развантом.
Прежде чем погрузиться в модули, вам необходимо настроить для курса пару дополнительных внешних инструментов.
ПРИМЕЧАНИЕ. Вы можете настроить их по ходу работы для каждого модуля, поскольку в каждом модуле мы укажем вам то, что вам нужно.
financial news data source
Следуйте этому документу, чтобы показать вам, как создать БЕСПЛАТНУЮ учетную запись и сгенерировать ключи API, которые вам понадобятся в рамках этого курса.
Примечание. 1 подключение для передачи данных Alpaca БЕСПЛАТНО.
serverless vector DB
Перейдите в Qdrant и создайте БЕСПЛАТНУЮ учетную запись.
После этого следуйте этому документу о том, как сгенерировать ключи API, которые вам понадобятся в рамках этого курса.
Примечание. Мы будем использовать только бесплатный план Qdrant.
serverless ML platform
Перейдите на Comet ML и создайте БЕСПЛАТНУЮ учетную запись.
После этого следуйте этому руководству, чтобы создать КЛЮЧ API и новый проект, который вам понадобится в рамках курса.
Примечание. Мы будем использовать только бесплатный план Comet ML.
serverless GPU compute | training & inference pipelines
Перейдите в Beam и создайте БЕСПЛАТНУЮ учетную запись.
После этого вы должны следовать их руководству по установке, чтобы установить интерфейс командной строки и настроить его с использованием своих учетных данных Beam.
Чтобы узнать больше о Beam, ознакомьтесь с вводным руководством.
Примечание. У вас есть около 10 бесплатных вычислительных часов. После этого вы платите только за то, чем пользуетесь. Если у вас графический процессор Nvidia >8 ГБ видеопамяти и вы не хотите развертывать конвейеры обучения и вывода, использование Beam не является обязательным.
При использовании Poetry у нас возникли проблемы с поиском интерфейса командной строки Beam внутри виртуальной среды Poetry. Чтобы исправить это, после установки Beam мы создаем символическую ссылку, указывающую на двоичные файлы Poetry, следующим образом:
export COURSE_MODULE_PATH= < your-course-module-path > # e.g., modules/training_pipeline
cd $COURSE_MODULE_PATH
export POETRY_ENV_PATH= $( dirname $( dirname $( poetry run which python ) ) )
ln -s /usr/local/bin/beam ${POETRY_ENV_PATH} /bin/beam cloud compute | feature pipeline
Перейдите в AWS, создайте учетную запись и создайте пару учетных данных.
После этого загрузите и установите AWS CLI v2.11.22 и настройте его, используя свои учетные данные.
Примечание. Вы платите только за то, чем пользуетесь. Вы развернете только виртуальную машину EC2 t2.small , стоимость которой составляет всего ~$0.023 в час. Если вы не хотите развертывать конвейер функций, использование AWS не является обязательным.
Каждый модуль имеет свои зависимости и скрипты. В производственной установке у каждого модуля будет свой репозиторий, но в данном случае в целях обучения мы поместили все в одно место:
Таким образом, проверьте README для каждого модуля отдельно, чтобы узнать, как его установить и использовать:
Мы настоятельно рекомендуем вам клонировать этот репозиторий и повторить все, что мы сделали, чтобы получить максимальную отдачу от этого курса.
В видеолекциях, статьях и документации README каждого модуля вы найдете пошаговые инструкции.
Приятного обучения!
Код GitHub (выпущенный по лицензии MIT) и видеолекции (выпущенные на YouTube) совершенно бесплатны. Всегда будет.
Уроки Medium публикуются на платной стене Medium. Если они у вас уже есть, то они бесплатны. В противном случае вам придется платить ежемесячную плату в размере 5 долларов за чтение статей.
Если во время курса у вас возникнут какие-либо вопросы или проблемы, мы рекомендуем вам создать задачу в этом репозитории, где вы сможете подробно объяснить все, что вам нужно.
В противном случае вы также можете связаться с преподавателями в LinkedIn:
Нажмите здесь, чтобы посмотреть видео?

Нажмите здесь, чтобы посмотреть видео?
Нажмите здесь, чтобы посмотреть видео?

Нажмите здесь, чтобы посмотреть видео?

Нажмите здесь, чтобы посмотреть видео?
To understand the entire code step-by-step, check out our articles ↓
Этот курс представляет собой проект с открытым исходным кодом, выпущенный под лицензией MIT. Таким образом, пока вы распространяете нашу ЛИЦЕНЗИЮ и признаете нашу работу, вы можете безопасно клонировать или разветвлять этот проект и использовать его в качестве источника вдохновения для чего угодно (например, университетских проектов, проектов для получения степени колледжа и т. д.).
 | Пау Лабарта Баджо | Старший инженер ML и MLOps Главный преподаватель. Парень из видеоуроков. Твиттер/Х Ютуб Информационный бюллетень о реальном мире машинного обучения Реальный сайт машинного обучения |
 | Александру Развант | Старший инженер по машинному обучению Второй повар. Инженер за кадром. Нейра Липс |
 | Пол Юстин | Старший инженер ML и MLOps Главный повар. Ребята, которые случайно заглядывают на видеоуроки. Твиттер/Х Расшифровка информационного бюллетеня по машинному обучению Персональный сайт | Центр машинного обучения и MLOps |


