QuillGPT
1.0.0

QuillGPT — это реализация блока декодера GPT, основанная на архитектуре из статьи «Внимание — это все, что вам нужно» Васвани и др. ал. реализовано в PyTorch. Кроме того, этот репозиторий содержит две предварительно обученные модели — Shakespearean GPT и Harpoon GPT — вместе с их обученными весами. Для упрощения экспериментирования и развертывания предусмотрена площадка Streamlit Playground для интерактивного изучения этих моделей и микросервис FastAPI, реализованный с помощью контейнеризации Docker для масштабируемого развертывания. Вы также найдете скрипты Python для обучения новых моделей GPT и выполнения на их основе выводов, а также блокноты, демонстрирующие обученные модели. Для облегчения кодирования и декодирования текста реализован простой токенизатор. Изучите QuillGPT, чтобы использовать эти инструменты и улучшить свои проекты по обработке естественного языка!
В этот репозиторий включены две предварительно обученные модели и веса.
| Особенность | Шекспировский GPT | Гарпун ГПТ |
|---|---|---|
| Параметры | 10,7 млн. | 226 М |
| Веса | Веса | Веса |
| Конфигурация модели | Конфигурация | Конфигурация |
| Данные обучения | Текст из пьес Шекспира (input.txt) | Случайный текст из книг (corpus.txt) |
| Тип встраивания | Встраивание символов | Встраивание символов |
| Учебный блокнот | Блокнот | Блокнот |
| Аппаратное обеспечение | NVIDIA Т4 | NVIDIA А100 |
| Потеря обучения и проверки | 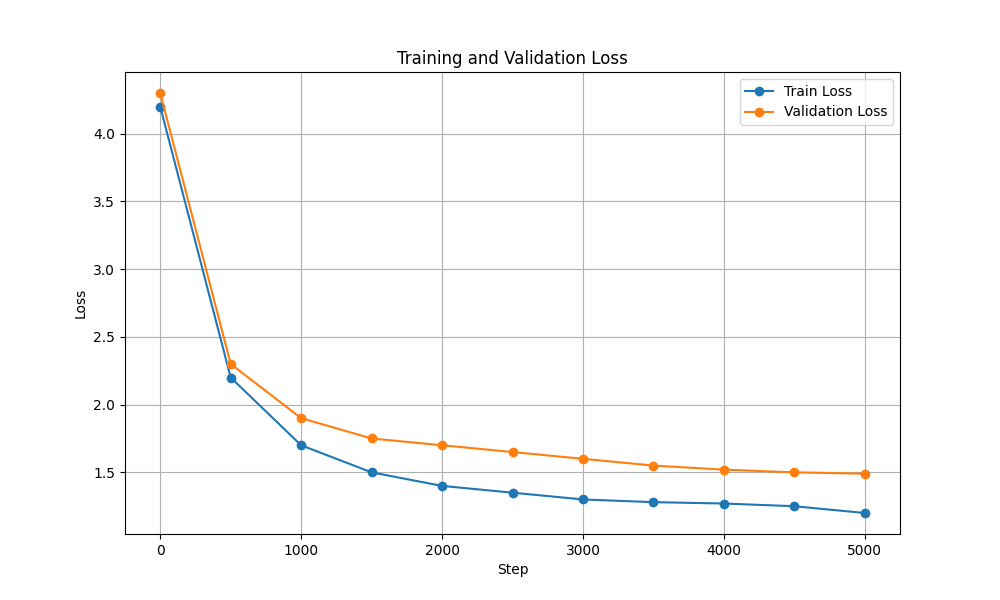 | 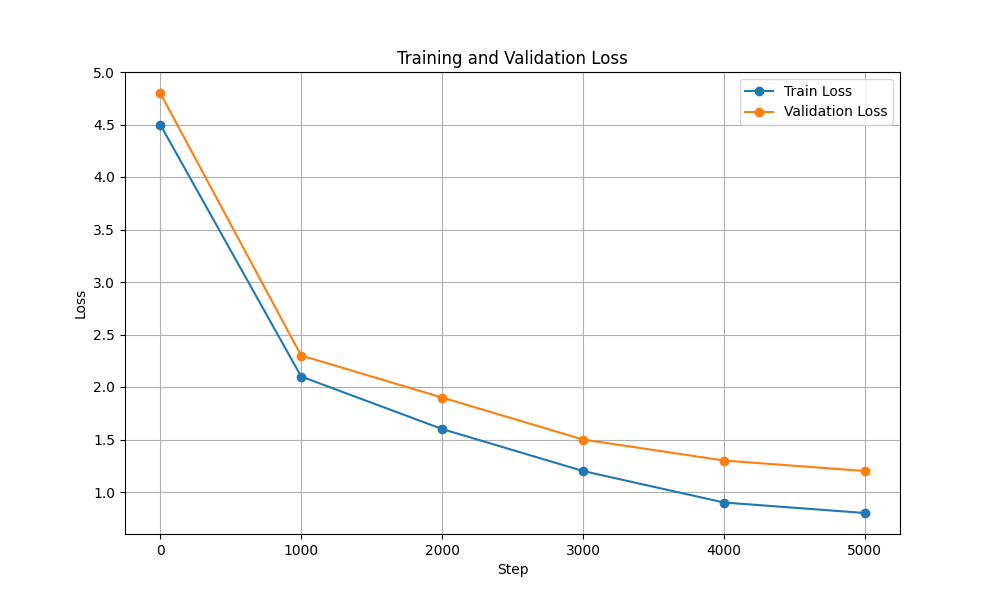 |
Чтобы запустить сценарии обучения и вывода, выполните следующие действия:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtПрежде чем продолжить, обязательно загрузите гири для Harpoon GPT отсюда!
Он размещен в облачном сервисе Streamlit. Вы можете посетить его по ссылке здесь.
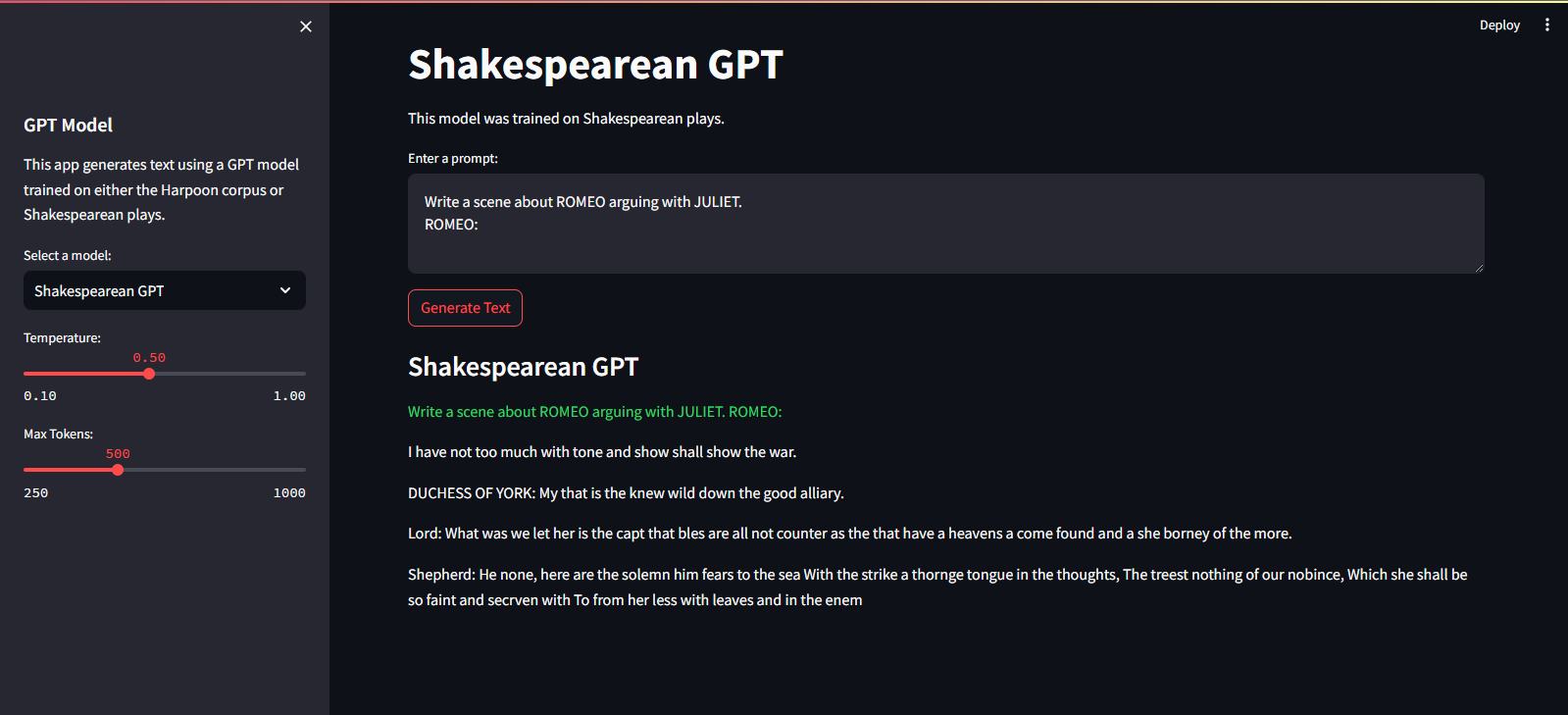
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devЧтобы обучить модель GPT, выполните следующие действия:
Подготовьте данные. Поместите все текстовые данные в один файл .txt и сохраните его.
Напишите конфигурации трансформатора и сохраните файл.
Например: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
Обучите модель с помощью scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (Вы можете изменить config_path , data_path и output_dir в соответствии с вашими требованиями.)
output_dir указанном в команде.После обучения вы можете использовать обученную модель GPT для генерации текста. Вот пример использования обученной модели для вывода:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 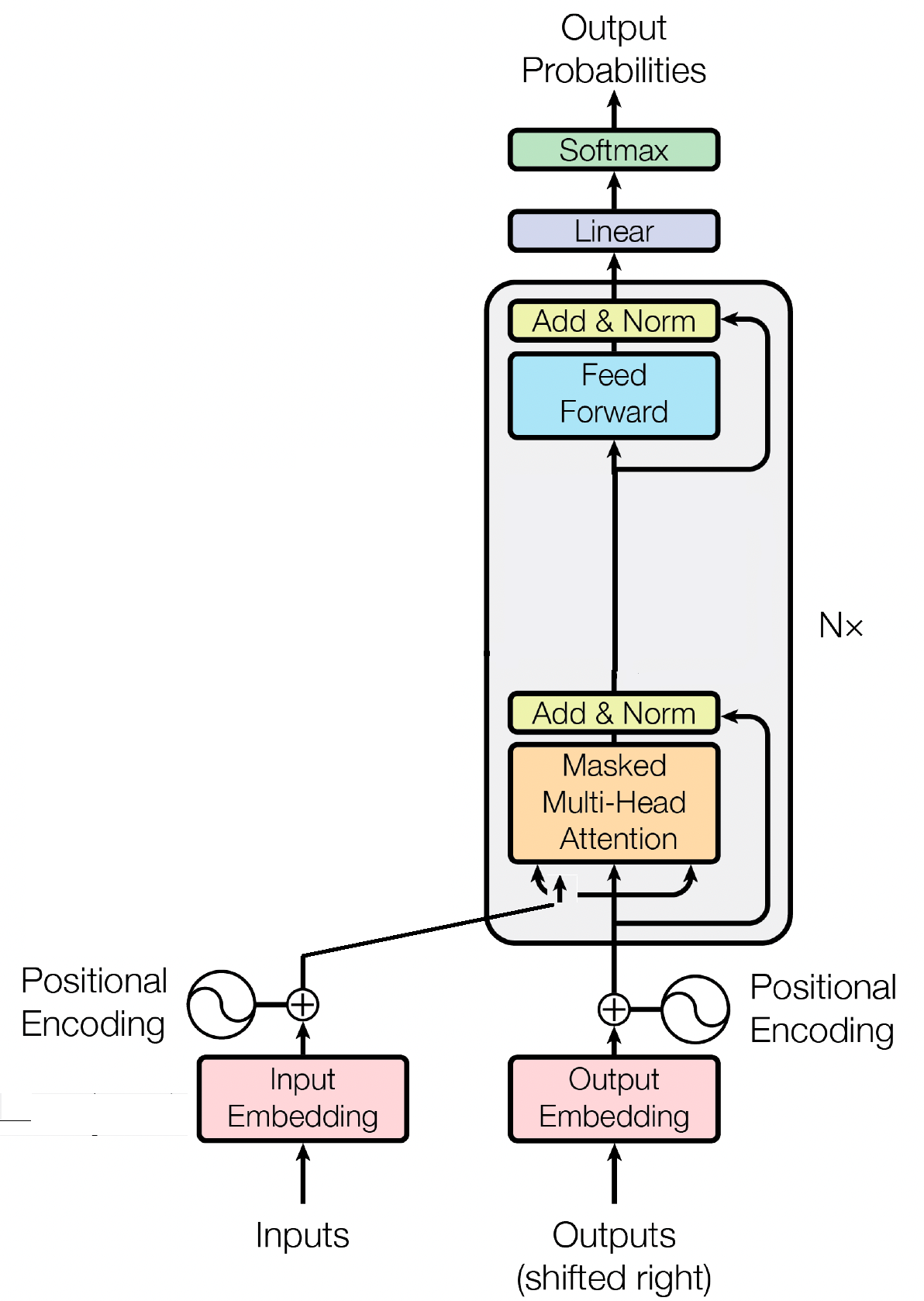
Блок декодера является важнейшим компонентом модели GPT (Генераторный предварительно обученный преобразователь), именно здесь GPT фактически генерирует текст. Он использует механизм самообслуживания для обработки входных последовательностей и генерации последовательных результатов. Каждый блок декодера состоит из нескольких слоев, включая уровни самообслуживания, нейронные сети прямой связи и нормализацию слоев. Слои самообслуживания позволяют модели взвешивать важность разных слов в последовательности, фиксируя контекст и зависимости независимо от их положения. Это позволяет модели GPT генерировать контекстно релевантный текст.
Встраивание входных данных играет решающую роль в моделях на основе преобразователей, таких как GPT, преобразуя входные токены в значимые числовые представления. Эти внедрения служат исходными данными для модели, собирая семантическую информацию о словах в последовательности. Этот процесс включает в себя отображение каждого токена во входной последовательности в многомерное векторное пространство, где похожие токены расположены ближе друг к другу. Это позволяет модели понимать взаимосвязи между разными словами и эффективно учиться на входных данных. Входные внедрения затем передаются в последующие уровни модели для дальнейшей обработки.
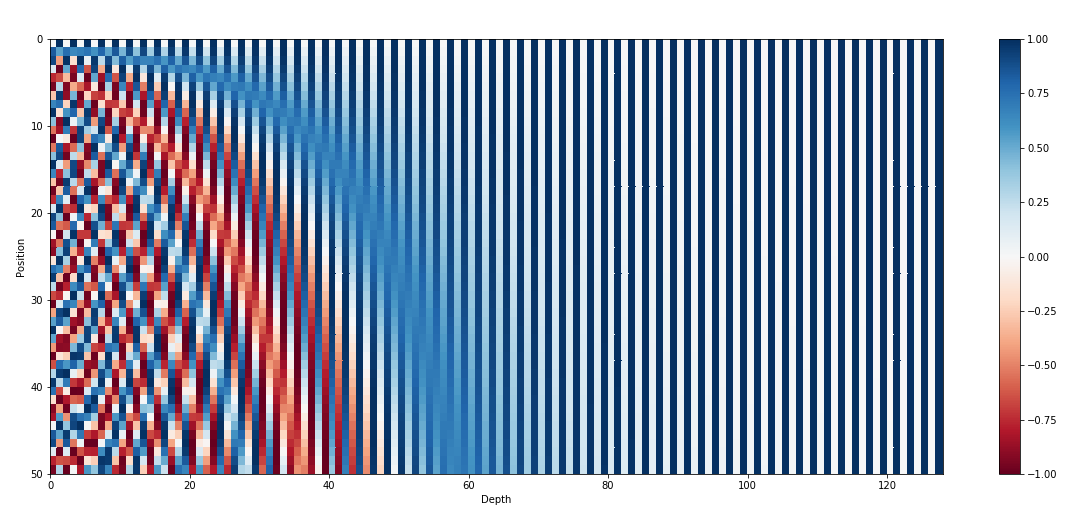
Помимо входных внедрений, позиционные внедрения являются еще одним важным компонентом архитектур преобразователей, таких как GPT. Поскольку преобразователям не хватает внутренней информации о порядке токенов в последовательности, вводятся позиционные вложения, чтобы предоставить модели позиционную информацию. Эти внедрения кодируют положение каждого токена в последовательности, позволяя модели различать токены на основе их позиций. Благодаря включению позиционных вложений преобразователи, такие как GPT, могут эффективно улавливать последовательный характер данных и генерировать последовательные выходные данные, которые поддерживают правильный порядок слов в сгенерированном тексте.

Самообслуживание, фундаментальный механизм в моделях на основе преобразователей, таких как GPT, действует путем присвоения оценок важности различным словам в последовательности. Этот процесс включает в себя три ключевых шага: вычисление показателей внимания, применение softmax для получения весов внимания и, наконец, объединение этих весов с входными представлениями для создания контекстно-информированных представлений. По своей сути самовнимание позволяет модели больше сосредоточиться на релевантных словах, уменьшив при этом внимание к менее важным, способствуя эффективному изучению контекстных зависимостей во входных данных. Этот механизм имеет решающее значение для выявления долгосрочных зависимостей и контекстуальных нюансов, позволяя моделям преобразователей генерировать длинные последовательности текста.
Массачусетский технологический институт © Шриранг Махаджан
Не стесняйтесь отправлять запросы на включение, создавайте проблемы или распространяйте информацию!
Поддержите меня, просто отметив этот репозиторий звездочкой!


