Изучая криптографию, я нашел видео Академии Хана, которое усилило мой интерес к недостаткам печально известного шифра Цезаря.
Всякий раз, когда вы пишете длинное письмо или электронное письмо на английском языке, вы непреднамеренно оставляете отпечаток пальца; если вы просканируете написанное вами сообщение и посчитаете частоту появления каждой буквы, вы обнаружите довольно последовательную закономерность. «e», скорее всего, будет самой повторяющейся буквой во всем сообщении. Чтобы проверить это, я взял случайную басню из Интернета, и результат, который я получил, был тем, чего и следовало от нее ожидать. «Е» действительно была самой популярной буквой. Этот факт справедлив для любого достаточно длинного сообщения.
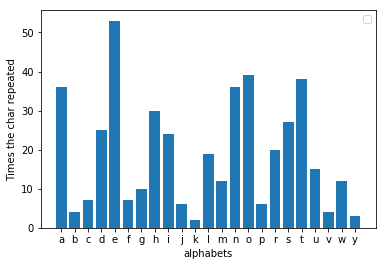
Недостаток, который обнаружил Аль-Кинди, заключался в том, что при анализе частоты зашифрованного сообщения теперь чаще всего повторяется другая буква. Если вы проверите, насколько буква сдвинута от трех, вы сможете найти значение, на которое заменяется сообщение. Например, если «h» — самая популярная буква в зашифрованном сообщении, то сдвиг, скорее всего, будет равен трем. Теперь, обратив сдвиг, мы могли легко получить исходное сообщение. В decoder.py когда вы передаете ему зашифрованный файл, он расшифровывает сообщение и печатает его. Я зашифровал ту же басню, сместив алфавиты на три буквы, и оказалось, что «h» действительно здесь самая популярная буква.
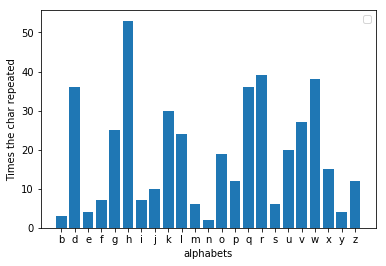
Чтобы воспроизвести результаты моего шифрования и исследовать его с другими сообщениями, помимо Python у вас должен быть установлен matplotlib.
pip install matplotlibПомните : декодер работает по принципу лингвистики и статистики, поэтому чем длиннее сообщение, тем точнее результат.
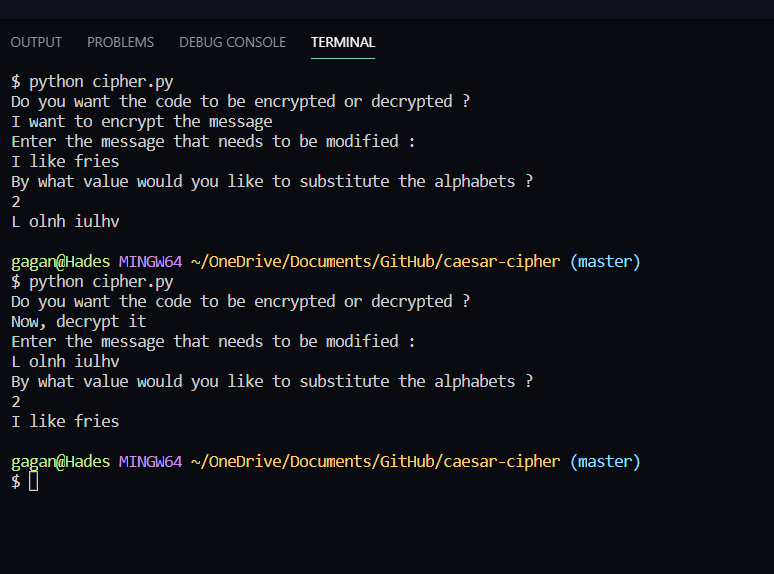
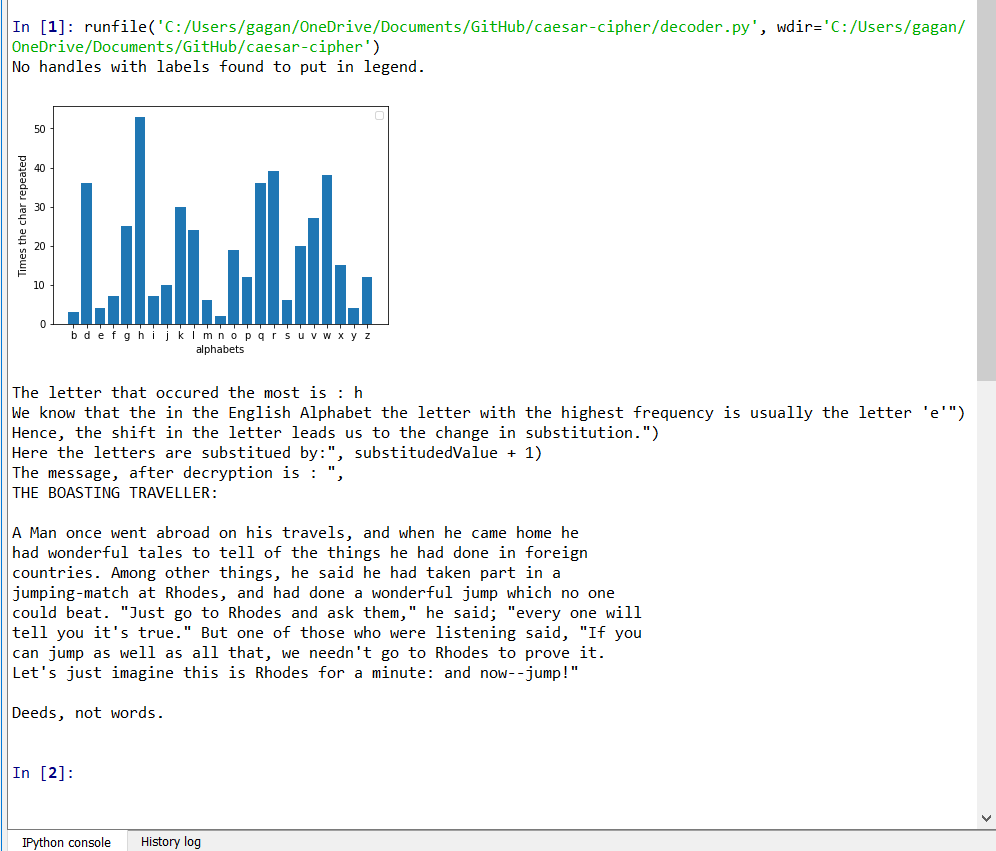
Гаган Девагири © MIT


