self instruct
1.0.0
Этот репозиторий содержит код и данные для статьи «Самообучение» — метода согласования предварительно обученных языковых моделей с инструкциями.
Самообучение — это платформа, которая помогает языковым моделям улучшить способность следовать инструкциям на естественном языке. Это достигается за счет использования собственных поколений модели для создания большой коллекции обучающих данных. С помощью самообучения можно улучшить возможности языковых моделей по выполнению инструкций, не полагаясь на обширные ручные аннотации.
В последние годы растет интерес к созданию моделей, которые могут следовать инструкциям на естественном языке для выполнения широкого спектра задач. Эти модели, известные как языковые модели, настроенные на инструкции, продемонстрировали способность обобщать новые задачи. Однако их производительность во многом зависит от качества и количества данных рукописных инструкций, используемых для их обучения, разнообразие и креативность которых могут быть ограничены. Чтобы преодолеть эти ограничения, важно разработать альтернативные подходы для контроля моделей, настроенных на инструкции, и улучшения их возможностей следования инструкциям.
Процесс самообучения — это итеративный алгоритм начальной загрузки, который начинается с начального набора инструкций, написанных вручную, и использует их, чтобы побудить языковую модель генерировать новые инструкции и соответствующие экземпляры ввода-вывода. Затем эти поколения фильтруются для удаления некачественных или похожих, а полученные данные добавляются обратно в пул задач. Этот процесс можно повторять несколько раз, в результате чего образуется большая коллекция обучающих данных, которые можно использовать для точной настройки языковой модели для более эффективного выполнения инструкций.
Вот обзор самообучения:
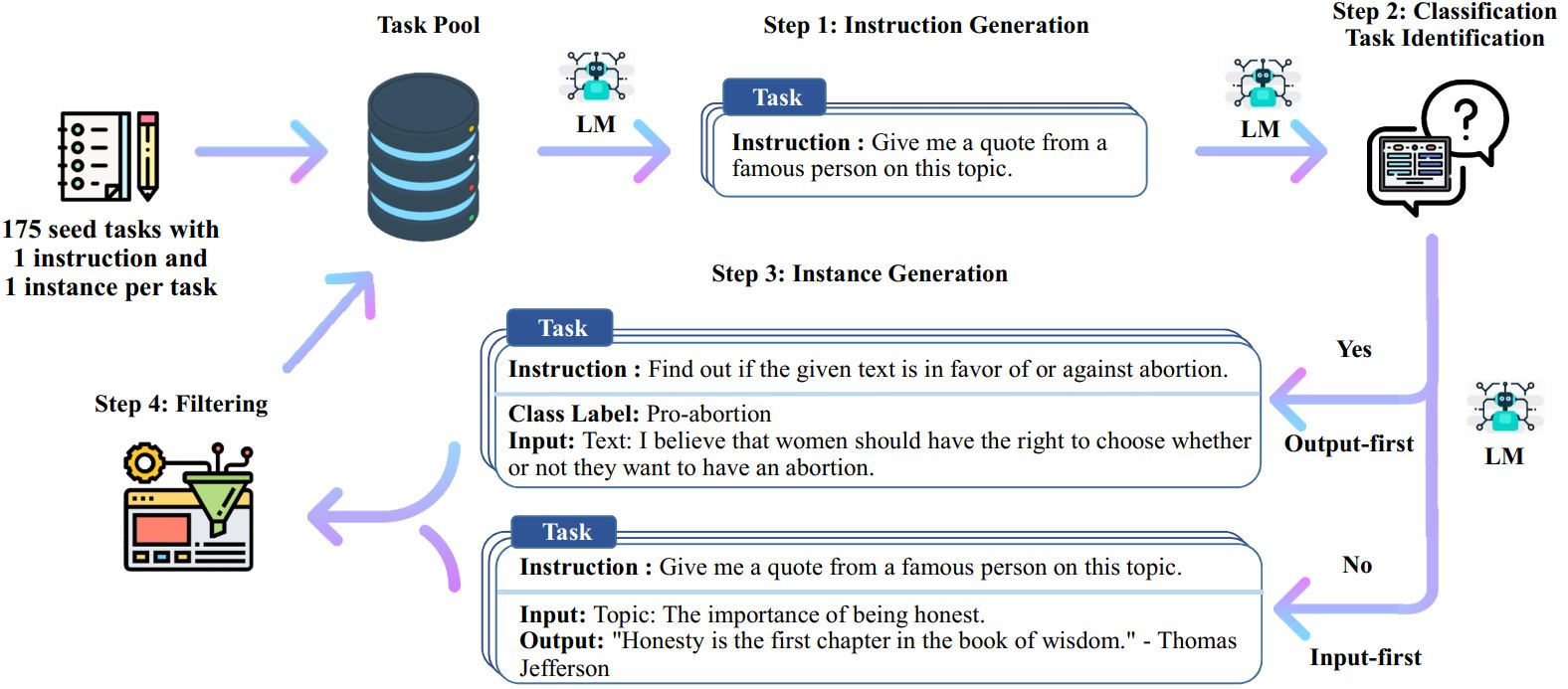
* Эта работа все еще продолжается. Мы можем обновлять код и данные по мере продвижения. Пожалуйста, будьте осторожны с контролем версий.
Мы выпускаем набор данных, содержащий 52 тыс. инструкций в сочетании с 82 тыс. экземпляров входов и выходов. Эти данные инструкций можно использовать для настройки инструкций для языковых моделей и для того, чтобы языковая модель лучше следовала инструкциям. Доступ ко всем данным, сгенерированным моделью, можно получить в data/gpt3-generations/batch_221203/all_instances_82K.jsonl . Эти данные (+ 175 начальных задач), переформатированные в чистый формат тонкой настройки GPT3 (подсказка + завершение), помещаются в data/finetuning/self_instruct_221203 . Вы можете использовать сценарий в ./scripts/finetune_gpt3.sh для точной настройки GPT3 на этих данных.
Примечание . Эти данные генерируются языковой моделью (GPT3) и неизбежно содержат некоторые ошибки или предвзятости. В нашей статье мы проанализировали качество данных по 200 случайным инструкциям и обнаружили, что 46% точек данных могут иметь проблемы. Мы призываем пользователей использовать эти данные с осторожностью и предлагать новые методы для фильтрации или устранения недостатков.
Мы также выпускаем новый набор из 252 написанных экспертами задач и инструкций к ним, основанных на ориентированных на пользователя приложениях (а не на хорошо изученных задачах НЛП). Эти данные используются в разделе самообучения, посвященном оценке человека. Для получения более подробной информации обратитесь к README для оценки человеком.
Чтобы генерировать данные самообучения с использованием ваших собственных начальных задач или других моделей, мы открываем исходный код наших скриптов для всего конвейера здесь. Наш текущий код тестируется только на модели GPT3, доступной через API OpenAI.
Вот скрипты для генерации данных:
# 1. Сгенерировать инструкции из исходных задач./scripts/generate_instructions.sh# 2. Определить, представляет ли инструкция задачу классификации или нет./scripts/is_clf_or_not.sh# 3. Сгенерировать экземпляры для каждой инструкции./scripts/generate_instances. sh# 4. Фильтрация, обработка и переформатирование./scripts/prepare_for_finetuning.sh
Если вы используете структуру или данные самообучения, не стесняйтесь ссылаться на нас.
@misc{selfinstruct, title={Самообучение: согласование языковой модели с самостоятельно сгенерированными инструкциями}, автор={Ван, Ичжун и Корди, Йегане и Мишра, Сваруп и Лю, Алиса и Смит, Ной А. и Хашаби, Дэниел и Хаджиширзи, Ханнане}, журнал = {препринт arXiv arXiv:2212.10560}, год={2022}} 

