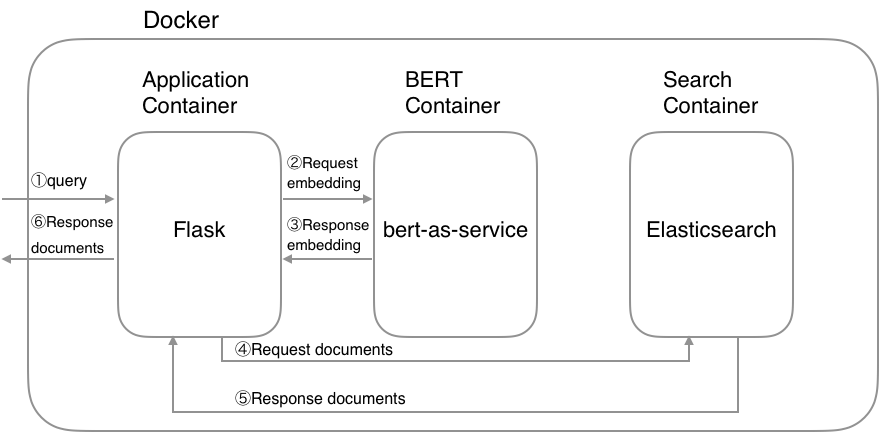
bertsearch
1.0.0
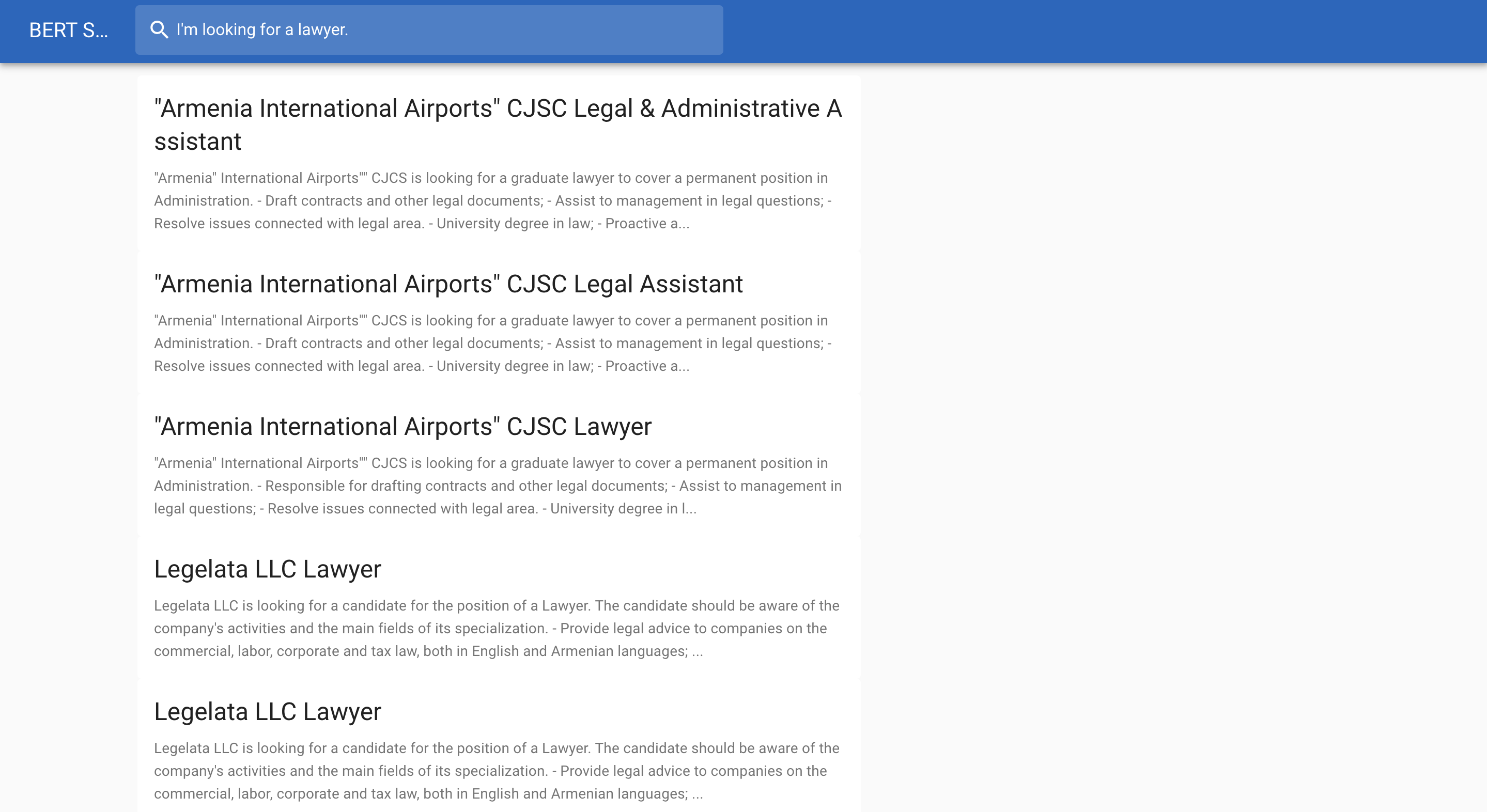
Ниже приведен пример поиска работы:
| База BERT, без корпуса | 12 слоев, 768 скрытых, 12 головок, 110M параметров |
| BERT-Большой, без корпуса | 24 слоя, 1024 скрытых, 16 головок, 340M параметров |
| BERT-База, в корпусе | 12 слоев, 768 скрытых, 12 головок, 110M параметров |
| BERT-Большой, в корпусе | 24 слоя, 1024 скрытых, 16 головок, 340M параметров |
| BERT-Base, многоязычный корпус (новый) | 104 языка, 12 слоев, 768 скрытых, 12 голов, 110M параметров. |
| BERT-Base, многоязычный корпус (старый) | 102 языка, 12 слоев, 768 скрытых, 12 голов, 110M параметров. |
| BERT-база, китайский | Китайский упрощенный и традиционный, 12 слоев, 768 скрытых, 12 головок, 110M параметров |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipВам необходимо установить предварительно обученную модель BERT и имя индекса Elasticsearch в качестве переменных среды:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up ВНИМАНИЕ . Если возможно, назначьте большой объем памяти (более 8GB ) для конфигурации памяти Docker, поскольку контейнеру BERT требуется большой объем памяти.
Вы можете использовать API создания индекса, чтобы добавить новый индекс в кластер Elasticsearch. При создании индекса вы можете указать следующее:
Например, если вы хотите создать индекс jobsearch с полями title , text и text_vector , вы можете создать индекс с помощью следующей команды:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} ВНИМАНИЕ . Значение dims text_vector должно совпадать с размером предварительно обученной модели BERT.
Создав индекс, вы готовы индексировать какой-либо документ. Суть здесь в том, чтобы преобразовать ваш документ в вектор с помощью BERT. Результирующий вектор сохраняется в поле text_vector . Давайте преобразуем ваши данные в документ JSON:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "После завершения сценария вы можете получить документ JSON следующего вида:
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...После преобразования данных в JSON вы можете добавить документ JSON в указанный индекс и сделать его доступным для поиска.
$ python example/index_documents.pyПерейдите по адресу http://127.0.0.1:5000.


