Этот код был построен на основе ранее существовавшей модели глубокого обучения Image to BEV, основанной на документе «Перевод изображений в карты». Этот код был написан с использованием Python 3.7. и прошел обучение на наборе данных nuScenes. Пожалуйста, обратитесь к ReadMe репозитория для получения информации о зависимостях и наборах данных для установки.
Первый шаг — создать папку с именем «translation-images-into-maps-main» и загрузить в нее все файлы. Затем, из-за большого размера файла, с этого Google Диска можно загрузить последние контрольные точки нашего обучения и набор данных mini nuScenes, используемый для проверки. Эти папки следует добавить непосредственно в каталог «translation-images-into-maps-main».
Ниже приведен список необходимых библиотек для этого репозитория:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Чтобы использовать функции этого репозитория, возможно, потребуется изменить следующие аргументы командной строки:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
Что касается обучения модели, эти аргументы командной строки можно изменить:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Наборы данных NuScenes Mini и Full можно найти в следующих местах:
НуСцена Мини:
NuScenes Full США:
Поскольку мини- и полный наборы данных NuScene не имеют одинакового формата ввода изображений (lmdb или png), необходимо внести некоторые изменения в код, чтобы использовать тот или иной формат:
mini на false, чтобы использовать мини-набор данных, а также пути и разделения args в файлах train.py , validation.py и inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Предварительно обученные контрольные точки можно найти здесь:
Контрольные точки должны храниться в /pretrained_models/27_04_23_11_08 из корневого каталога этого репозитория. Если вы хотите загрузить их из другого каталога, измените следующие аргументы:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Для тренировки на сцитах необходимо из корневого каталога запустить следующий скрипт:
sbatch job.script.sh
Чтобы тренироваться локально на процессоре:
python3 train.py
Обязательно адаптируйте сценарий к аргументам командной строки.
Чтобы проверить производительность модели на Scitas:
sbatch job.validate.sh
Чтобы тренироваться локально на процессоре:
python3 validate.py
Обязательно адаптируйте сценарий к аргументам командной строки.
Чтобы сделать вывод по видео о Scitas:
sbatch job.evaluate.sh
Чтобы тренироваться локально на процессоре:
python3 inference.py
Обязательно адаптируйте сценарий к аргументам командной строки, особенно:
--batch-size // 1 for the test videos
--video-name
--video-root
Этот проект был реализован в рамках курса «Глубокое обучение для автономных транспортных средств» CIVIL-459, который преподавал профессор Александр Алахи в EPFL. Нас курировал докторант Юэцзян Лю. Основная цель проекта курса — разработать модель глубокого обучения, которую можно будет использовать на борту системы автопилота Tesla. Что касается нашей группы, мы занимаемся преобразованием изображений монокулярной камеры в вид с высоты птичьего полета. Это можно сделать с помощью семантической сегментации для классификации таких элементов, как автомобили, тротуар, пешеходы и горизонт.
Во время нашего исследования монокулярных изображений для моделей глубокого обучения BEV мы заметили, что информация о пешеходах терялась во время сегментации, что приводило к плохой классификации. Как видно на изображении ниже, при оценке выбранная нами модель достигает в среднем 25,7% IoU (пересечение через объединение) для 14 классов объектов в наборе данных nuScenes. Точность прогнозирования для транспортных средств хорошая (74,5%) и довольно низкая для велосипедов, барьеров и прицепов. Однако точность прогноза для пешеходов (9,5%) слишком низка. Такая низкая точность могла бы привести к несчастным случаям, если бы кто-то перешел дорогу, не находясь на переходе.

Более подробную информацию о нашем исследовании можно найти на Драйве.
Поскольку плохое обнаружение пешеходов казалось самой актуальной проблемой текущей обученной модели, мы стремились повысить точность, изучив более подходящие функции потерь и обучив новую модель на наборе данных nuScenes.
Модель, которую мы построили, была обучена с использованием
Еще одна проблема с
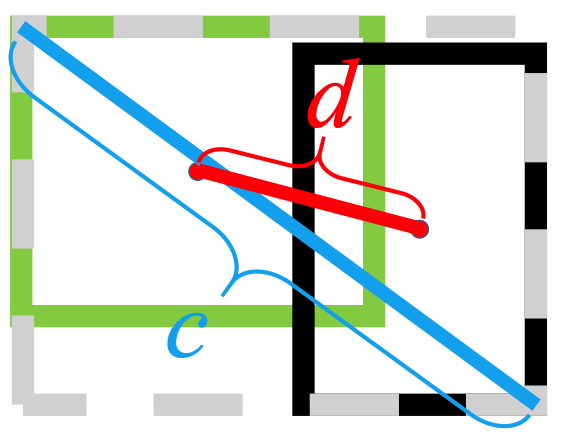
Он использует норму L2 для минимизации расстояния между прогнозируемыми и целевыми полями и сходится намного быстрее, чем

Горизонтальное растяжение

Вертикальное растяжение
Более того, потеря DIOU вводит член регуляризации, который способствует плавной сходимости.
Как можно видеть на следующем изображении,
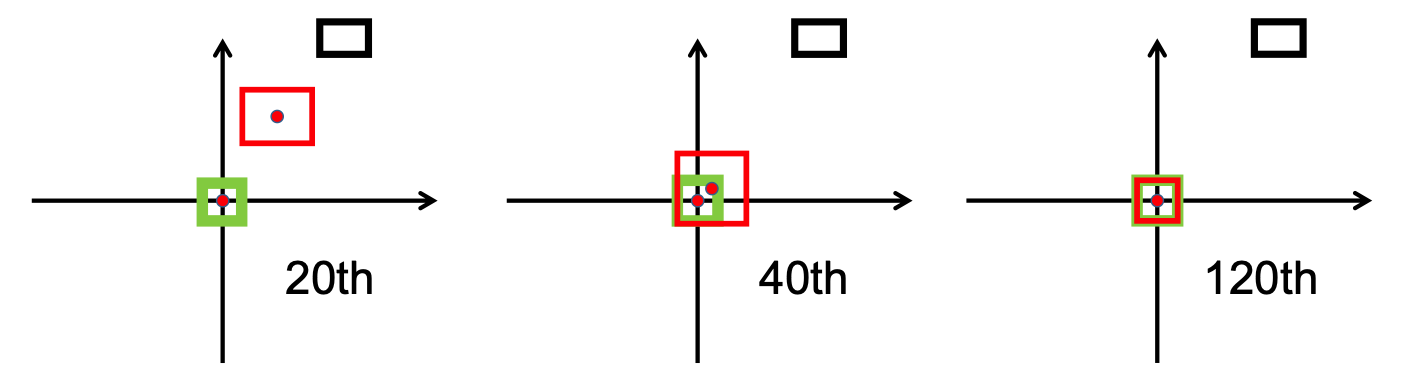
После этапа исследования мы внедрили bbox_overlaps_diou в файле /src/utils.py с помощью
Эта функция затем используется для вычисления многомасштабного compute_multiscale_iou того же файла. Для каждого класса iou ) рассчитывается по размеру пакета. Результатом работы функции является словарь iou_dict содержащий многомасштабные значения.
Затем мы использовали эти значения в train.py , где val-interval . Эти значения также использовались в validation.py , где они использовались для отображения потерь и
Мы обучили модель на наборе данных NuScenes, начиная с предоставленной контрольной checkpoint-008.pth.gz , один раз с
Еще одним вкладом является новый формат визуализации, позволяющий лучше различать классы со всеми соответствующими метками и значениями IoU. Это было реализовано в файле visualization.py .
Наконец, мы работали над реализацией режима, который будет принимать видео .mp4 в качестве входных данных и разлагать их на отдельные кадры изображения. Затем они будут оценены моделью, и мы сможем визуализировать результат сегментации в файле inference.py .
Чтобы иметь предварительное представление о стратегии обучения этой модели, мы сначала решили обучить ее на мини-наборах данных NuScenes. Начиная с checkpoint-008.pth.gz , мы смогли обучить две модели, отличающиеся используемой метрикой IoU (IoU для одной и DIOU для другой). Результаты, полученные на мини-партии NuScenes после 10 эпох обучения, представлены в таблице ниже.

Изучив эти результаты, мы заметили, что класс пешеходов, на котором мы основывали нашу гипотезу, вообще не дал убедительных результатов. Поэтому мы пришли к выводу, что мини-набора данных недостаточно для наших нужд, и решили перенести обучение на полный набор данных на Scitas.
После обучения наших новых моделей (с DIoU или IoU) из checkpoint-008.pth.gz в течение 8 новых эпох мы получили многообещающие результаты. С целью сравнения производительности этих недавно обученных моделей мы выполнили этап проверки мини-набора данных. Визуализация результата для изображения этого набора данных представлена ниже.
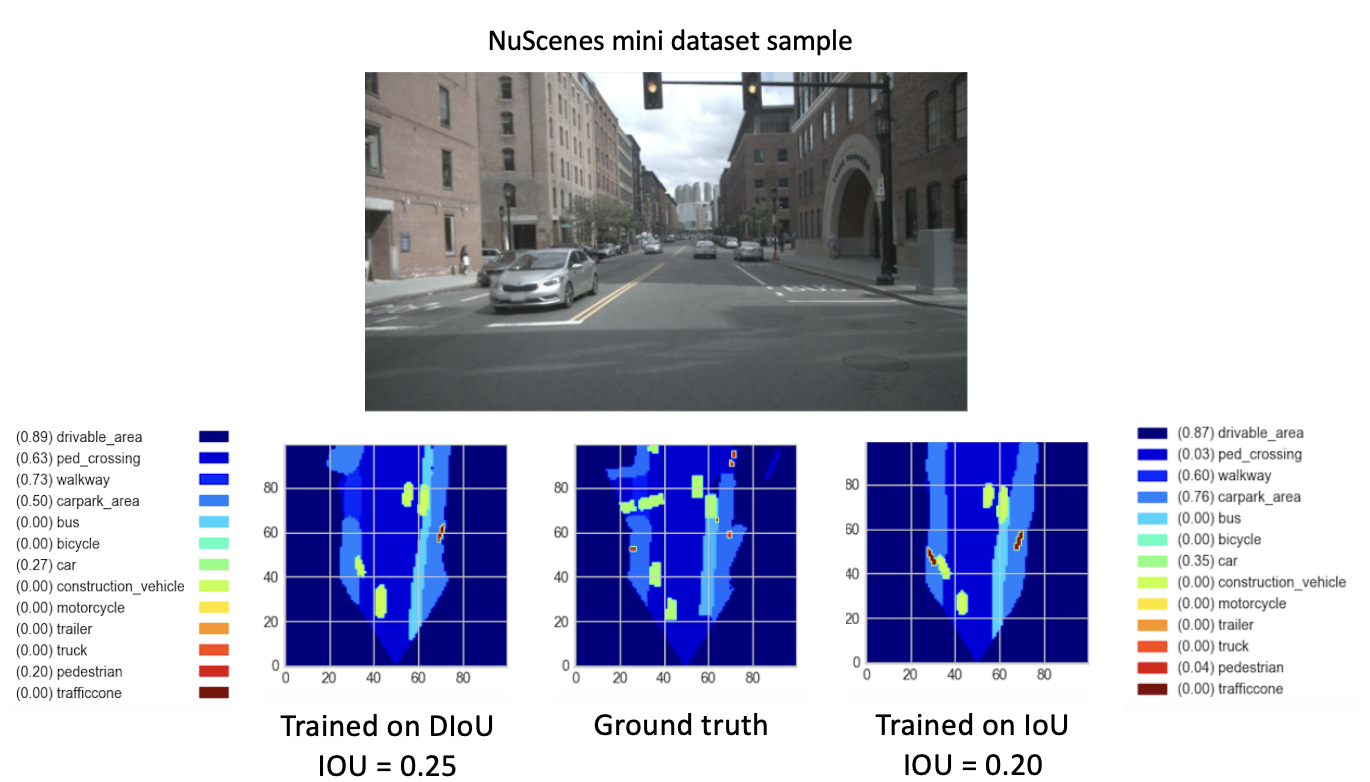
Здесь

Эти результаты, наконец, показывают лучшую производительность
Теперь, когда у нас есть обученная модель, мы можем использовать ее для прогнозирования BEV, используя любые входные изображения или видео. Хотя нашей целью было реализовать наш метод в финальной демонстрации курса, полученные карты с высоты птичьего полета, к сожалению, оказались недостаточно производительными. На рисунке ниже показан результат вывода на одном из предоставленных тестовых видеороликов (см. тестовые видеоролики).

Мы считаем, что такая неэффективность вывода обусловлена следующими параметрами:
Хотя переход из
Один из вариантов — реализовать
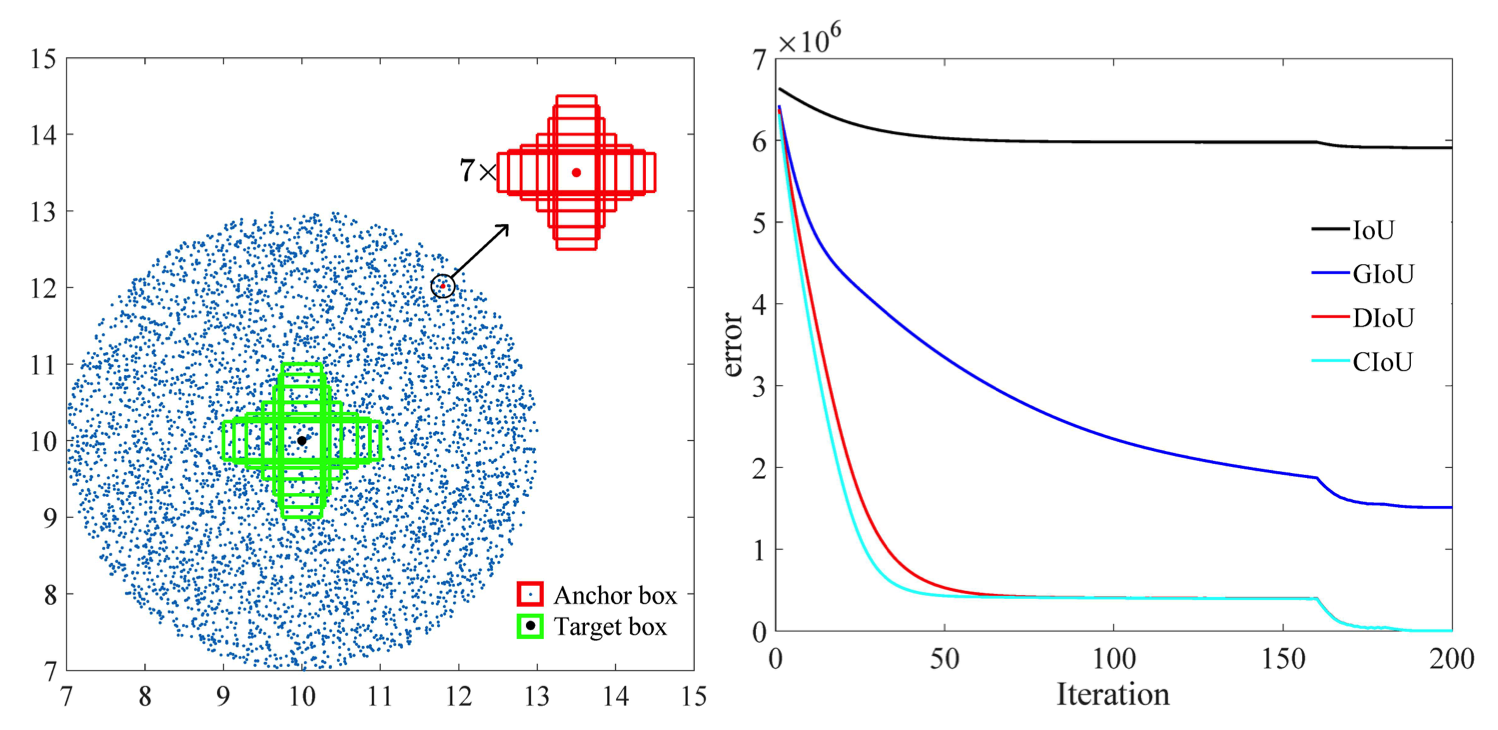
Кроме того, согласно исследованию, проведенному в этой статье [2], ошибка регрессии для CIoU ухудшается быстрее, чем для остальных, и будет сходиться к
Другой вариант — тренироваться на наборах данных с большим количеством людей, чтобы лучше отображать пешеходов и велосипедистов.
Наконец, чтобы по-настоящему подтвердить нашу гипотезу, можно было бы провести проверку на полном наборе данных NuScenes и сравнить пешеходные затраты двух моделей.
[1] Чжаохуэй Чжэн, Пин Ван, Вэй Лю, Цзиньцзэ Ли, Жунгуан Е, Дунвэй Жэнь (2020). Потеря расстояния-IoU: более быстрое и лучшее обучение регрессии ограничивающего прямоугольника https://arxiv.org/pdf/1911.08287.pdf
[2] Чжаохуэй Чжэн, Пин Ван, Дунвэй Жэнь, Вэй Лю, Жунгуан Е, Цинхуа Ху, Ванмэн Цзо (2021). Улучшение геометрических факторов в обучении модели и выводе для обнаружения объектов и сегментации экземпляров https://arxiv.org/pdf/2005.03572.pdf


