tiny cuda nn
Version 1.6
Это небольшая автономная платформа для обучения и выполнения запросов нейронных сетей. В частности, он содержит молниеносный «полностью объединенный» многослойный перцептрон (технический документ), универсальное хеш-кодирование с несколькими разрешениями (технический документ), а также поддержку различных других входных кодировок, потерь и оптимизаторов.
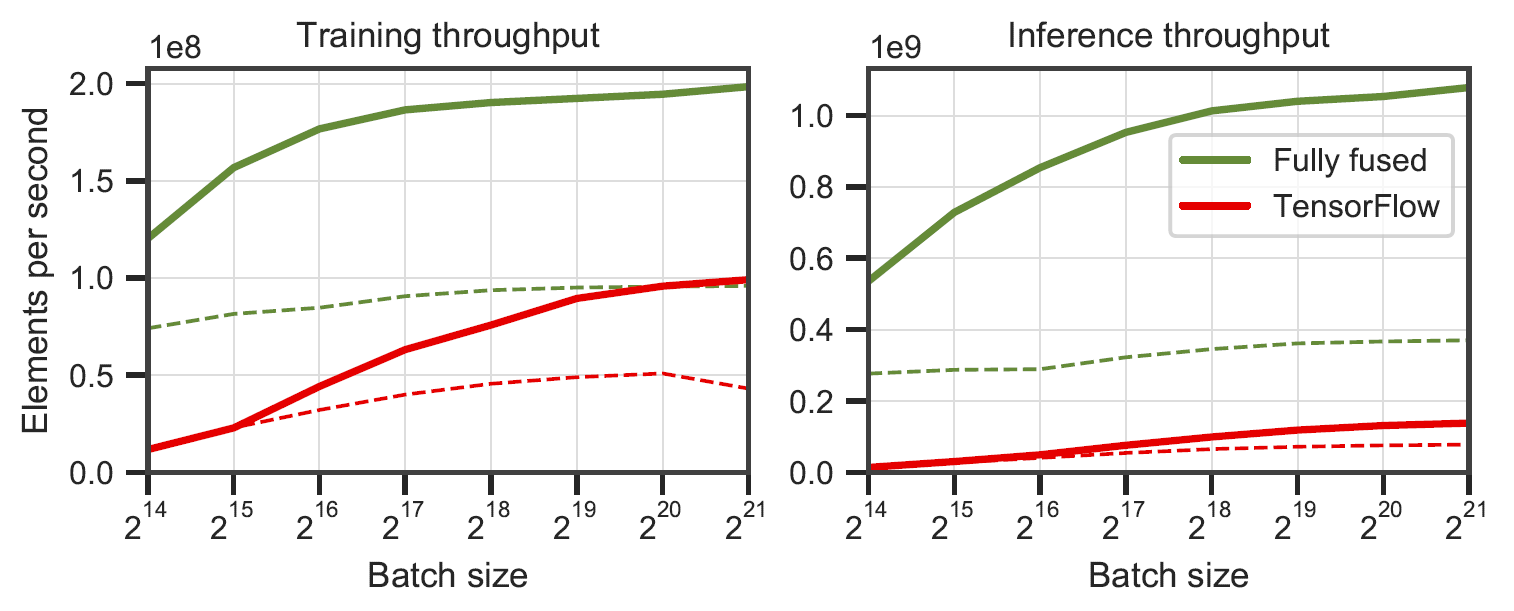 Полностью объединенные сети по сравнению с TensorFlow v2.5.0 с XLA. Измерено на многослойных перцептронах шириной 64 (сплошная линия) и 128 (пунктирная линия) на RTX 3090. Сгенерировано с помощью
Полностью объединенные сети по сравнению с TensorFlow v2.5.0 с XLA. Измерено на многослойных перцептронах шириной 64 (сплошная линия) и 128 (пунктирная линия) на RTX 3090. Сгенерировано с помощью benchmarks/bench_ours.cu и benchmarks/bench_tensorflow.py с использованием data/config_oneblob.json .
Крошечные нейронные сети CUDA имеют простой API C++/CUDA:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);Мы предоставляем пример приложения, в котором изучается функция изображения (x,y) -> (R,G,B) . Его можно запустить через
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonсоздание изображения каждые пару шагов обучения. Каждые 1000 шагов должны занимать чуть больше 1 секунды при конфигурации по умолчанию на RTX 4090.
| 10 шагов | 100 шагов | 1000 шагов | Эталонное изображение |
|---|---|---|---|
 |  |  |  |
n_neurons или вместо этого использовать CutlassMLP (лучшая совместимость, но более медленный).Если вы используете Linux, установите следующие пакеты
sudo apt-get install build-essential git Мы также рекомендуем установить CUDA в /usr/local/ и добавить установку CUDA в ваш PATH. Например, если у вас CUDA 11.4, добавьте следующее в ваш ~/.bashrc
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " Начните с клонирования этого репозитория и всех его подмодулей, используя следующую команду:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnЗатем используйте CMake для сборки проекта: (в Windows это должно быть в командной строке разработчика).
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j Если компиляция по необъяснимым причинам завершается сбоем или занимает больше часа, возможно, вам не хватает памяти. В этом случае попробуйте запустить приведенную выше команду без -j .
tiny-cuda-nn поставляется с расширением PyTorch, которое позволяет использовать быстрые MLP и входные кодировки из контекста Python. Эти привязки могут быть значительно быстрее, чем полные реализации Python; в частности, для хэш-кодирования с несколькими разрешениями.
Тем не менее, накладные расходы Python/PyTorch могут быть значительными, если размер пакета невелик. Например, при размере пакета 64 КБ встроенный пример
mlp_learning_an_imageчерез PyTorch примерно в 2 раза медленнее, чем собственный CUDA. При размере пакета 256 КБ и выше (по умолчанию) производительность намного ближе.
Начните с настройки среды Python 3.X с использованием последней версии PyTorch с поддержкой CUDA. Затем вызовите
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchВ качестве альтернативы, если вы хотите установить из локального клона tiny-cuda-nn , вызовите
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installВ случае успеха вы можете использовать модели tiny-cuda-nn, как показано в следующем примере:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) Пример см. в samples/mlp_learning_an_image_pytorch.py .
Ниже приводится краткое изложение компонентов этой структуры. В документации JSON перечислены параметры конфигурации.
| Сети | ||
|---|---|---|
| Полностью слитый MLP | src/fully_fused_mlp.cu | Молниеносная реализация небольших многослойных персептронов (MLP). |
| КАТЛАСС МЛП | src/cutlass_mlp.cu | MLP основан на процедурах CUTLASS GEMM. Медленнее, чем полностью объединенный, но работает с более крупными сетями и при этом достаточно быстр. |
| Входные кодировки | ||
|---|---|---|
| Композитный | include/tiny-cuda-nn/encodings/composite.h | Позволяет составлять несколько кодировок. Может быть, например, использован для сборки кодировки Neural Radiance Caching [Müller et al. 2021]. |
| Частота | include/tiny-cuda-nn/encodings/frequency.h | NeRF [Mildenhall et al. 2020] позиционное кодирование применяется одинаково ко всем измерениям. |
| Сетка | include/tiny-cuda-nn/encodings/grid.h | Кодирование на основе обучаемых сеток мультиразрешения. Используется для примитивов мгновенной нейронной графики [Müller et al. 2022]. Сетки могут поддерживаться хеш-таблицами, плотным хранилищем или мозаичным хранилищем. |
| Личность | include/tiny-cuda-nn/encodings/identity.h | Оставляет ценности нетронутыми. |
| Одинблоб | include/tiny-cuda-nn/encodings/oneblob.h | Из выборки по важности нейронов [Müller et al. 2019] и варианты нейронного контроля [Müller et al. 2020]. |
| СферическиеГармоники | include/tiny-cuda-nn/encodings/spherical_harmonics.h | Кодирование в частотном пространстве, которое больше подходит для векторов направления, чем для компонентных. |
| ТреугольникВолна | include/tiny-cuda-nn/encodings/triangle_wave.h | Недорогая альтернатива кодировке NeRF. Используется в кэшировании нейронного излучения [Müller et al. 2021]. |
| Потери | ||
|---|---|---|
| Л1 | include/tiny-cuda-nn/losses/l1.h | Стандартная потеря L1. |
| Относительный L1 | include/tiny-cuda-nn/losses/l1.h | Относительные потери L1, нормированные по прогнозу сети. |
| МАПЭ | include/tiny-cuda-nn/losses/mape.h | Средняя абсолютная процентная ошибка (MAPE). То же, что и относительный L1, но нормализованный по цели. |
| СМАПЕ | include/tiny-cuda-nn/losses/smape.h | Симметричная средняя абсолютная процентная ошибка (SMAPE). То же, что и относительный L1, но нормализованный по среднему значению прогноза и цели. |
| Л2 | include/tiny-cuda-nn/losses/l2.h | Стандартная потеря L2. |
| Относительный L2 | include/tiny-cuda-nn/losses/relative_l2.h | Относительные потери L2, нормированные с помощью сетевого прогноза [Lehtinen et al. 2018]. |
| Относительная яркость L2 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | То же, что и выше, но нормализовано по яркости предсказания сети. Применимо только в том случае, если сетевое прогнозирование выполнено в формате RGB. Используется в кэшировании нейронного излучения [Müller et al. 2021]. |
| Перекрестная энтропия | include/tiny-cuda-nn/losses/cross_entropy.h | Стандартная кросс-энтропийная потеря. Применимо только в том случае, если прогноз сети представляет собой PDF-файл. |
| Дисперсия | include/tiny-cuda-nn/losses/variance_is.h | Стандартная потеря дисперсии. Применимо только в том случае, если прогноз сети представляет собой PDF-файл. |
| Оптимизаторы | ||
|---|---|---|
| Адам | include/tiny-cuda-nn/optimizers/adam.h | Реализация Adam [Kingma and Ba 2014], обобщенная на AdaBound [Luo et al. 2019]. |
| Новоград | include/tiny-cuda-nn/optimizers/lookahead.h | Реализация Новограда [Гинзбург и др. 2019]. |
| сингапурский доллар | include/tiny-cuda-nn/optimizers/sgd.h | Стандартный стохастический градиентный спуск (SGD). |
| Шампунь | include/tiny-cuda-nn/optimizers/shampoo.h | Реализация оптимизатора шампуня 2-го порядка [Gupta et al. 2018] с собственными оптимизациями, а также с оптимизациями Анила и др. [2020]. |
| Средний | include/tiny-cuda-nn/optimizers/average.h | Обертывает другой оптимизатор и вычисляет линейное среднее весов за последние N итераций. Среднее значение используется только для вывода (не учитывается при обучении). |
| Пакетированный | include/tiny-cuda-nn/optimizers/batched.h | Обертывает другой оптимизатор, вызывая вложенный оптимизатор каждые N шагов по усредненному градиенту. Имеет тот же эффект, что и увеличение размера пакета, но требует только постоянного объема памяти. |
| Композитный | include/tiny-cuda-nn/optimizers/composite.h | Позволяет использовать несколько оптимизаторов по разным параметрам. |
| ЕМА | include/tiny-cuda-nn/optimizers/average.h | Обертывает другой оптимизатор и вычисляет экспоненциальное скользящее среднее весов. Среднее значение используется только для вывода (не учитывается при обучении). |
| Экспоненциальный распад | include/tiny-cuda-nn/optimizers/exponential_decay.h | Обертывает другой оптимизатор и выполняет кусочно-постоянное экспоненциальное затухание скорости обучения. |
| просмотр вперед | include/tiny-cuda-nn/optimizers/lookahead.h | Обертывает другой оптимизатор, реализующий алгоритм опережающего просмотра [Zhang et al. 2019]. |
Эта платформа лицензируется по 3-пунктной лицензии BSD. Подробности см. в LICENSE.txt .
Если вы используете его в своих исследованиях, мы будем признательны за ссылку через
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}Для деловых запросов посетите наш веб-сайт и отправьте форму: Лицензирование исследований NVIDIA.
Среди прочего, эта структура лежит в основе следующих публикаций:
Примитивы мгновенной нейронной графики с хеш-кодированием с несколькими разрешениями
Томас Мюллер, Алекс Эванс, Кристоф Шид, Александр Келлер
Транзакции ACM для графики ( SIGGRAPH ), июль 2022 г.
Сайт / Бумага / Код / Видео / BibTeX
Извлечение треугольных 3D-моделей, материалов и освещения из изображений
Джейкоб Мункберг, Джон Хассельгрен, Тяньчан Шен, Цзюнь Гао, Вэньчжэн Чен, Алекс Эванс, Томас Мюллер, Санья Фидлер
CVPR (Устный) , июнь 2022 г.
Сайт / Бумага / Видео / BibTeX
Кэширование нейронного излучения в реальном времени для отслеживания пути
Томас Мюллер, Фабрис Руссель, Ян Новак, Александр Келлер
Транзакции ACM для графики ( SIGGRAPH ), август 2021 г.
Бумага / Обсуждение GTC / Видео / Интерактивный просмотр результатов / BibTeX
А также следующее программное обеспечение:
NerfAcc: общий набор инструментов для ускорения NeRF
Жуйлонг Ли, Мэттью Танчик, Анджу Канадзава
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: основа для развития поля нейронного излучения
Мэттью Танчик*, Итан Уэбер*, Ивонн Нг*, Жуйлонг Ли, Брент Йи, Терренс Ван, Александр Кристофферсен, Джейк Остин, Камьяр Салахи, Абхик Ахуджа, Дэвид Макаллистер, Анджу Канадзава
https://github.com/nerfstudio-project/nerfstudio
Пожалуйста, не стесняйтесь делать запрос на включение, если вашей публикации или программного обеспечения нет в списке.
Особая благодарность авторам NRC за полезные обсуждения и Николаусу Биндеру за предоставление части инфраструктуры этой платформы, а также за помощь в использовании TensorCores из CUDA.


