

Новый робот в городе: СО-100.

Мы только что добавили новое руководство о том, как построить более доступного робота по цене 110 долларов за руку!
Научите его новым навыкам, показав ему несколько движений с помощью ноутбука.
Затем наблюдайте, как ваш самодельный робот действует автономно?
Перейдите по ссылке на полное руководство по SO-100.
LeRobot: современный искусственный интеллект для реальной робототехники
? LeRobot стремится предоставлять модели, наборы данных и инструменты для реальной робототехники в PyTorch. Цель состоит в том, чтобы снизить барьер для входа в робототехнику, чтобы каждый мог внести свой вклад и получить выгоду от обмена наборами данных и предварительно обученными моделями.
? LeRobot содержит самые современные подходы, которые, как было показано, могут быть перенесены в реальный мир с упором на имитационное обучение и обучение с подкреплением.
? LeRobot уже предоставляет набор предварительно обученных моделей, наборы данных с демонстрациями, собранными людьми, и среды моделирования, позволяющие начать работу без сборки робота. В ближайшие недели планируется добавить все больше и больше поддержки реальной робототехники для самых доступных и способных роботов.
? LeRobot размещает предварительно обученные модели и наборы данных на странице сообщества Hugging Face:huggingface.co/lerobot.
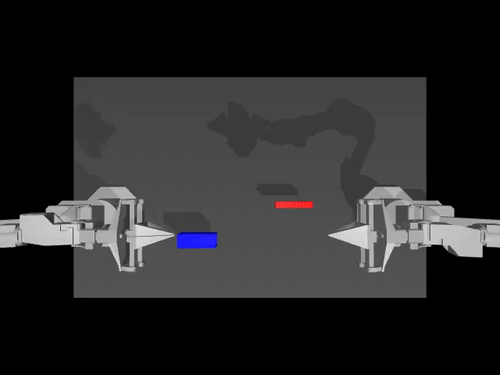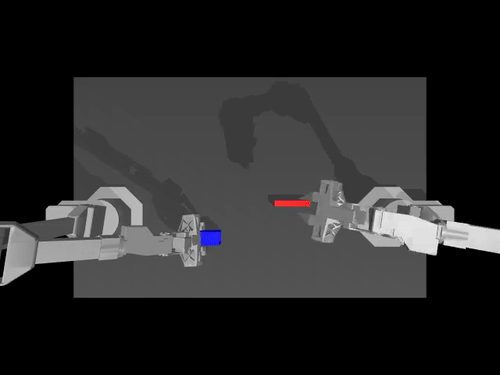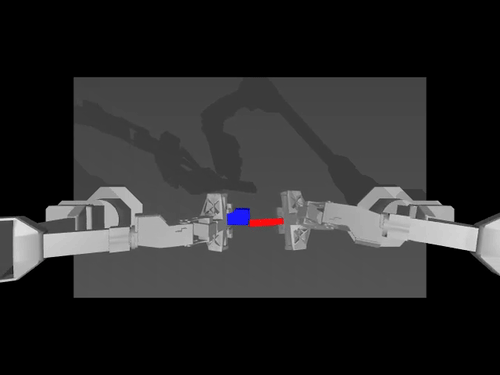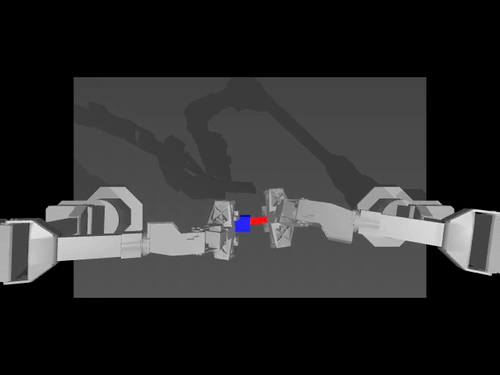 |  |  |
| Политика ACT в отношении среды ALOHA | Политика TDMPC в среде SimXArm | Политика распространения в среде PushT |
Загрузите наш исходный код:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Создайте виртуальную среду с помощью Python 3.10 и активируйте ее, например, с помощью miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotУстановить ? ЛеРобот:
pip install -e .ПРИМЕЧАНИЕ. В зависимости от вашей платформы, если на этом этапе вы обнаружите какие-либо ошибки сборки, вам может потребоваться установить
cmakeиbuild-essentialдля сборки некоторых наших зависимостей. В Linux:sudo apt-get install cmake build-essential
Для моделирования ? LeRobot поставляется с спортивными средами, которые можно установить в качестве дополнительных принадлежностей:
Например, установить? LeRobot с aloha и pusht, используйте:
pip install -e " .[aloha, pusht] "Чтобы использовать веса и смещения для отслеживания экспериментов, войдите в систему с помощью
wandb login(примечание: вам также необходимо будет включить WandB в конфигурации. См. ниже.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Ознакомьтесь с примером 1, который иллюстрирует, как использовать наш класс набора данных, который автоматически загружает данные из концентратора Hugging Face.
Вы также можете локально визуализировать эпизоды из набора данных в хабе, выполнив наш скрипт из командной строки:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 или из набора данных в локальной папке с корневой переменной среды DATA_DIR (в следующем случае набор данных будет искаться в ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 Он откроет rerun.io и отобразит потоки камеры, состояния и действия робота, вот так:
Наш скрипт также может визуализировать наборы данных, хранящиеся на удаленном сервере. Дополнительные инструкции см. в разделе python lerobot/scripts/visualize_dataset.py --help .
LeRobotDataset Набор данных в формате LeRobotDataset очень прост в использовании. Его можно загрузить из репозитория в хабе Hugging Face или из локальной папки, например, с помощью dataset = LeRobotDataset("lerobot/aloha_static_coffee") и можно индексировать, как любой другой набор данных Hugging Face и PyTorch. Например, dataset[0] извлечет один временной кадр из набора данных, содержащего наблюдения и действие в виде тензоров PyTorch, готовых к передаче в модель.
Особенность LeRobotDataset заключается в том, что вместо получения одного кадра по его индексу мы можем получить несколько кадров на основе их временных отношений с индексированным кадром, установив delta_timestamps в список относительных времен по отношению к индексированному кадру. Например, с помощью delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} можно получить по заданному индексу 4 кадра: 3 «предыдущие» кадра 1 секунду, 0,5 секунды и 0,2 секунды до индексированного кадра и сам индексированный кадр (соответствует записи 0). См. пример 1_load_lerobot_dataset.py для получения более подробной информации о delta_timestamps .
Формат LeRobotDataset использует несколько способов сериализации данных, которые могут быть полезны для понимания, если вы планируете более тесно работать с этим форматом. Мы попытались создать гибкий, но простой формат набора данных, который охватывал бы большинство типов функций и особенностей, присутствующих в обучении с подкреплением и робототехнике, в симуляции и в реальном мире, с упором на камеры и состояния роботов, но легко расширяемый на другие типы сенсорных функций. входные данные, если они могут быть представлены тензором.
Вот важные детали и организация внутренней структуры типичного LeRobotDataset , созданного с помощью dataset = LeRobotDataset("lerobot/aloha_static_coffee") . Точные характеристики будут меняться от набора данных к набору данных, но не основные аспекты:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
LeRobotDataset сериализуется с использованием нескольких распространенных форматов файлов для каждой из его частей, а именно:
safetensor .safetensor Набор данных можно легко загрузить/выгрузить из хаба HuggingFace. Чтобы работать с локальным набором данных, вы можете установить переменную среды DATA_DIR для корневой папки набора данных, как показано в приведенном выше разделе, посвященном визуализации набора данных.
Ознакомьтесь с примером 2, который иллюстрирует, как загрузить предварительно обученную политику из хаба Hugging Face и запустить оценку в соответствующей среде.
Мы также предоставляем более функциональный сценарий для распараллеливания оценки в нескольких средах во время одного и того же развертывания. Вот пример предварительно обученной модели, размещенной на lerobot/diffusion_pusht:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10Примечание. После обучения собственной политики вы можете повторно оценить контрольные точки с помощью:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model Дополнительные инструкции см. в разделе python lerobot/scripts/eval.py --help .
Ознакомьтесь с примером 3, который иллюстрирует, как обучать модель с использованием нашей основной библиотеки Python, и примером 4, который показывает, как использовать наш сценарий обучения из командной строки.
В общем, вы можете использовать наш скрипт обучения, чтобы легко обучить любую политику. Вот пример обучения политики ACT на траекториях, собранных людьми в среде моделирования Aloha для задачи вставки:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human Каталог эксперимента создается автоматически и отображается желтым цветом в вашем терминале. Это выглядит как outputs/train/2024-05-05/20-21-12_aloha_act_default . Вы можете вручную указать каталог эксперимента, добавив этот аргумент в команду Python train.py :
hydra.run.dir=your/new/experiment/dir В каталоге эксперимента будет папка с названием checkpoints , которая будет иметь следующую структуру:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step Чтобы возобновить обучение с контрольной точки, вы можете добавить их в команду Python train.py :
hydra.run.dir=your/original/experiment/dir resume=trueОн загрузит предварительно обученную модель, состояния оптимизатора и планировщика для обучения. Для получения дополнительной информации см. наше руководство по возобновлению обучения здесь.
Чтобы использовать wandb для регистрации кривых обучения и оценки, убедитесь, что вы запустили wandb login в качестве однократного этапа настройки. Затем, при запуске приведенной выше команды обучения, включите WandB в конфигурации, добавив:
wandb.enable=trueСсылка на журналы wandb для запуска также будет отображаться желтым цветом в вашем терминале. Вот пример того, как они выглядят в вашем браузере. Также проверьте здесь объяснение некоторых часто используемых показателей в журналах.

Примечание. В целях эффективности во время обучения каждая контрольная точка оценивается по небольшому количеству эпизодов. Вы можете использовать eval.n_episodes=500 для оценки большего количества эпизодов, чем по умолчанию. Или после обучения вы можете переоценить свои лучшие контрольные точки в других эпизодах или изменить настройки оценки. Дополнительные инструкции см. в разделе python lerobot/scripts/eval.py --help .
Мы организовали наши файлы конфигурации (находятся в разделе lerobot/configs ) таким образом, чтобы они воспроизводили результаты SOTA для данного варианта модели в своих соответствующих оригинальных работах. Просто запуск:
python lerobot/scripts/train.py policy=diffusion env=pushtвоспроизводит результаты SOTA для политики распространения в задаче PushT.
Предварительно обученные политики, а также подробную информацию о воспроизведении можно найти в разделе «Модели» на https://huggingface.co/lerobot.
Если вы хотите внести свой вклад? ЛеРобот, пожалуйста, ознакомьтесь с нашим руководством по вкладам.
Чтобы добавить набор данных в хаб, вам необходимо войти в систему, используя токен доступа для записи, который можно сгенерировать в настройках Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential Затем укажите папку с необработанным набором данных (например, data/aloha_static_pingpong_test_raw ) и отправьте свой набор данных в хаб с помощью:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 Дополнительные инструкции см. в разделе python lerobot/scripts/push_dataset_to_hub.py --help .
Если ваш формат набора данных не поддерживается, реализуйте свой собственный в lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py скопировав примеры, такие как pusht_zarr, umi_zarr, aloha_hdf5 или xarm_pkl.
После обучения политики вы можете загрузить ее в хаб Hugging Face, используя идентификатор хаба, который выглядит как ${hf_user}/${repo_name} (например, lerobot/diffusion_pusht).
Сначала вам нужно найти папку контрольных точек, расположенную внутри каталога вашего эксперимента (например, outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). Внутри него есть каталог pretrained_model который должен содержать:
config.json : сериализованная версия конфигурации политики (после конфигурации класса данных политики).model.safetensors : набор параметров torch.nn.Module , сохраненных в формате Hugging Face Safetensors.config.yaml : консолидированная конфигурация обучения Hydra, содержащая конфигурации политики, среды и набора данных. Конфигурация политики должна точно соответствовать config.json . Конфигурация среды полезна для всех, кто хочет оценить вашу политику. Конфигурация набора данных служит просто документальным подтверждением воспроизводимости.Чтобы загрузить их в хаб, выполните следующее:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelСм. eval.py, где приведен пример того, как другие люди могут использовать вашу политику.
Пример фрагмента кода для профилирования оценки политики:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function Если хотите, можете процитировать эту работу с помощью:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}Кроме того, если вы используете какую-либо конкретную политическую архитектуру, предварительно обученные модели или наборы данных, рекомендуется указать первоначальных авторов работы, как они указаны ниже:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

