EasyOCR
v1.7.2
Готовое к использованию средство оптического распознавания текста с поддержкой более 80 языков и всеми популярными письменностями, включая латынь, китайский, арабский, деванагари, кириллицу и т. д.
Попробуйте демо на нашем сайте
Интегрировано в Huggingface Spaces? с помощью Градио. Попробуйте веб-демо:
24 сентября 2024 г. — версия 1.7.2
Прочитать все примечания к выпуску



Установить с помощью pip
Для последней стабильной версии:
pip install easyocrДля последней версии разработки:
pip install git+https://github.com/JaidedAI/EasyOCR.git Примечание 1. Для Windows сначала установите torch и torchvision, следуя официальным инструкциям здесь https://pytorch.org. На веб-сайте pytorch обязательно выберите нужную версию CUDA. Если вы собираетесь работать только в режиме ЦП, выберите CUDA = None .
Примечание 2. Здесь мы также предоставляем Dockerfile.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )Вывод будет в формате списка, каждый элемент представляет собой ограничивающую рамку, обнаруженный текст и уровень достоверности соответственно.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] Примечание 1: ['ch_sim','en'] — это список языков, которые вы хотите читать. Вы можете передать несколько языков одновременно, но не все языки можно использовать вместе. Английский совместим со всеми языками, а языки, имеющие общие символы, обычно совместимы друг с другом.
Примечание 2. Вместо пути к файлу chinese.jpg вы также можете передать объект изображения OpenCV (массив numpy) или файл изображения в виде байтов. Также допускается URL-адрес необработанного изображения.
Примечание 3. reader = easyocr.Reader(['ch_sim','en']) предназначено для загрузки модели в память. Это займет некоторое время, но его нужно запустить только один раз.
Вы также можете установить detail=0 для более простого вывода.
reader . readtext ( 'chinese.jpg' , detail = 0 )Результат:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]Веса моделей для выбранного языка будут загружены автоматически, или вы можете загрузить их вручную из центра моделей и поместить в папку «~/.EasyOCR/model».
Если у вас нет графического процессора или у вашего графического процессора мало памяти, вы можете запустить модель в режиме только процессора, добавив gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )Для получения дополнительной информации прочтите руководство и документацию по API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=TrueО модели распознавания читайте здесь.
О модели обнаружения (CRAFT) читайте здесь.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )Идея состоит в том, чтобы иметь возможность подключить к EasyOCR любую современную модель. Есть много гениев, пытающихся создать лучшие модели обнаружения/распознавания, но мы здесь не пытаемся быть гениями. Мы просто хотим сделать их произведения быстро доступными для публики... бесплатно. (ну, мы считаем, что большинство гениев хотят, чтобы их работа оказала положительное влияние как можно быстрее и сильнее). Конвейер должен выглядеть примерно так, как показано на диаграмме ниже. Серые слоты — это места для сменных голубых модулей.
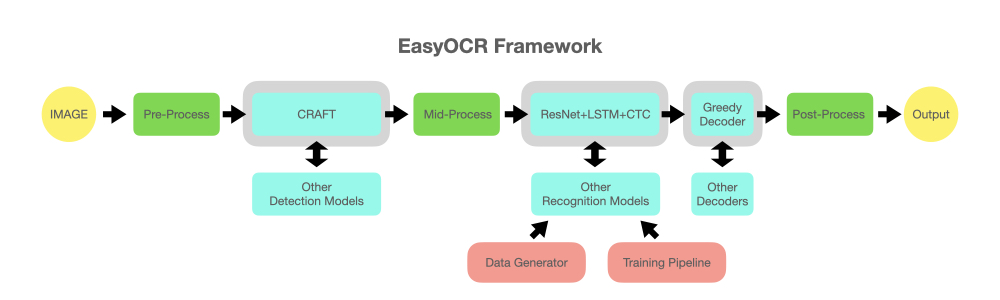
Этот проект основан на исследованиях и коде из нескольких статей и репозиториев с открытым исходным кодом.
Все процессы глубокого обучения основаны на Pytorch. ❤️
При выполнении обнаружения используется алгоритм CRAFT из этого официального репозитория и их статьи (спасибо @YoungminBaek от @clovaai). Мы также используем их предварительно обученную модель. Сценарий обучения предоставлен @gmuffiness.
Модель распознавания — CRNN (бумага). Он состоит из трех основных компонентов: извлечение признаков (в настоящее время мы используем Resnet) и VGG, маркировка последовательностей (LSTM) и декодирование (CTC). Конвейер обучения для выполнения распознавания представляет собой модифицированную версию тестовой среды глубокого распознавания текста. (Спасибо @ku21fan от @clovaai) Этот репозиторий — жемчужина, заслуживающая большего признания.
Код поиска Beam основан на этом репозитории и его блоге. (Спасибо @githubharald)
Синтез данных основан на TextRecognitionDataGenerator. (Спасибо @Belval)
А хорошую информацию о CTC на сайте distill.pub можно прочитать здесь.
Давайте вместе продвинем человечество, сделав ИИ доступным каждому!
3 способа внести свой вклад:
Кодер: Пожалуйста, присылайте PR о небольших ошибках/улучшениях. Для более крупных вопросов обсудите с нами, сначала открыв вопрос. Существует список возможных ошибок/проблем, связанных с улучшениями, с пометкой «PR ДОБРО ПОЖАЛОВАТЬ».
Пользователь: Расскажите нам, какую пользу EasyOCR принесет вам/вашей организации для стимулирования дальнейшего развития. Также публикуйте случаи сбоев в разделе «Проблемы», чтобы улучшить будущие модели.
Технический руководитель/гуру: Если вы нашли эту библиотеку полезной, пожалуйста, распространите информацию! (См. сообщение Янна Лекуна о EasyOCR)
Чтобы запросить новый язык, нам нужно, чтобы вы отправили PR с двумя следующими файлами:
Если в вашем языке есть уникальные элементы (например, 1. Арабский: символы меняют форму при соединении друг с другом + пишут справа налево 2. Тайский: некоторые символы должны быть над линией, а некоторые — под), пожалуйста, сообщите нам об этом. ваших способностей и/или дайте полезные ссылки. Важно позаботиться о деталях, чтобы создать действительно работающую систему.
Наконец, пожалуйста, поймите, что нашим приоритетом будут популярные языки или наборы языков, которые имеют общие символы друг с другом (также сообщите нам, относится ли это к вашему языку). На разработку новой модели у нас уходит как минимум неделя, поэтому вам, возможно, придется подождать выхода новой модели.
См. Список языков в разработке.
Из-за ограниченности ресурсов вопрос старше 6 месяцев будет автоматически закрыт. Пожалуйста, откройте проблему еще раз, если она критическая.
Для поддержки предприятий Jaided AI предлагает полный спектр услуг для пользовательских систем оптического распознавания символов/ИИ, включая внедрение, обучение/тонкую настройку и развертывание. Нажмите здесь, чтобы связаться с нами.


