nmt
1.0.0
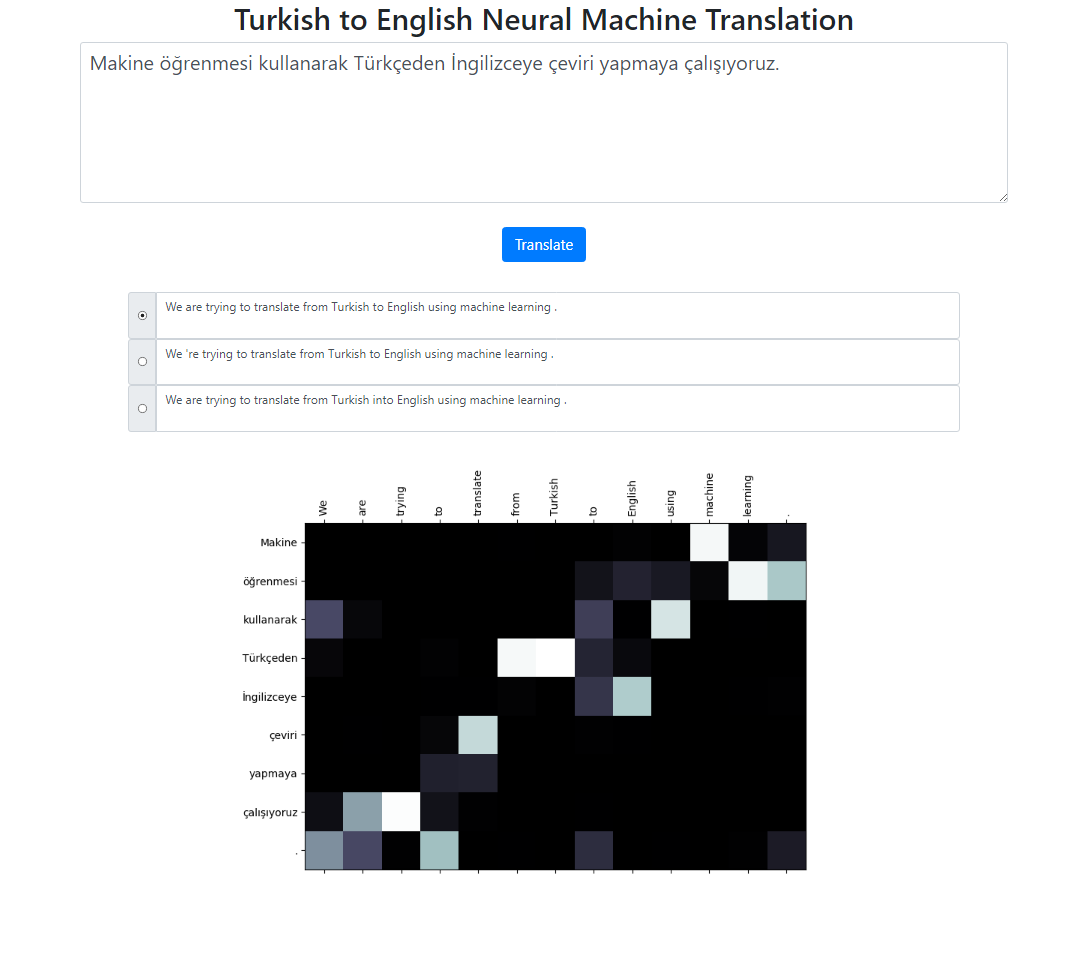
В этом репозитории реализована система нейронного машинного перевода с турецкого на английский с использованием модели Seq2Seq + Global Attention. Существует также приложение Flask, которое можно запустить локально. Вы можете ввести текст, перевести и просмотреть результаты, а также визуализировать внимание. Мы запускаем поиск луча с размером луча 3 в фоновом режиме и возвращаем наиболее вероятные последовательности, отсортированные по их относительному баллу.
Набор данных для этого проекта взят отсюда. Я использовал корпус Татоэба. Я удалил некоторые дубликаты, найденные в данных. Я также предварительно токенизировал набор данных. Окончательную версию можно найти в папке data.
Для токенизации турецких предложений я использовал RegexpTokenizer nltk.
puncts_Exception_apostrope = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_Exception_apostrope}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "Титаник 15 tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Выходные данные: Титаник 15 нис. pazartesi saat 02 : 20 'de battı .# Это свойство разделения на " 02 : 20" отличается от английского токенизатора.# Мы могли бы справиться с такими ситуациями. Но я хотел упростить задачу и посмотреть, # совпадает ли распределение внимания на этих словах с английскими токенами.# Подобные случаи встречаются в основном в датах, как в этом примере: 09.02.2019Для токенизации английских предложений я использовал английскую модель spacy.
en_nlp = spacy.load('en_core_web_sm')text = "Титаник затонул в 02:20 в понедельник, 15 апреля". tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text) ]))# Вывод: Титаник затонул в 02:20 в понедельник, 15 апреля.Предполагается, что турецкие и английские предложения будут находиться в двух разных файлах.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
Пожалуйста, запустите python train.py -h для получения полного списка аргументов.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
Чтобы вычислить синюю оценку уровня корпуса.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
Для локального запуска приложения выполните:
python app.py
Убедитесь, что пути к вашей модели в файле config.py определены правильно.
Файл модели
Словарный файл
Использование подслов (как для турецкого, так и для английского языка)
Различные механизмы внимания (обучение различным параметрам внимания)
Скелетный код для этого проекта взят из Стэнфордского курса НЛП: CS224n.


