LVBench
1.0.0
[Страница проекта] [ arXiv Paper] [Набор данных][? Таблица лидеров][? Таблица лидеров Huggingface]
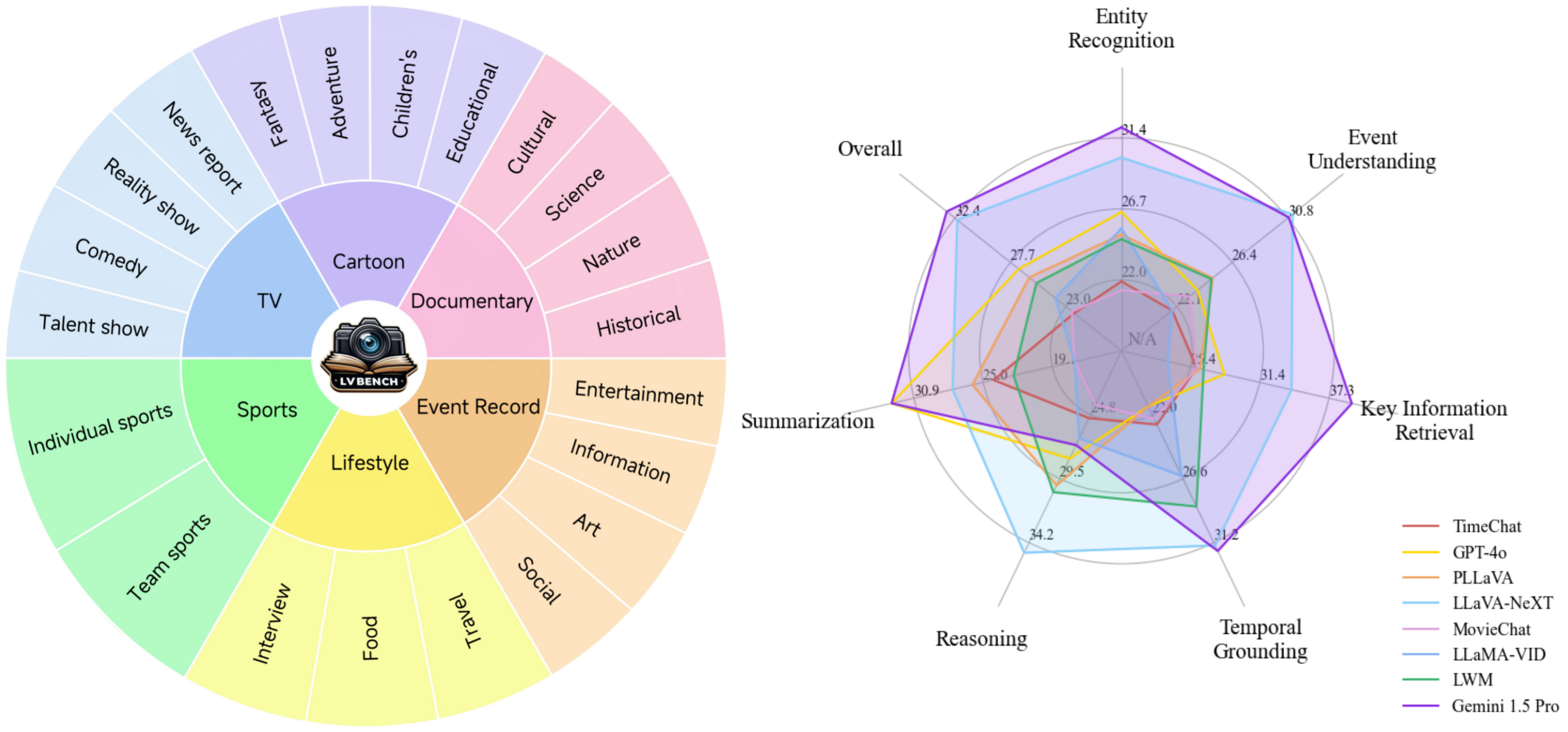
LVBench — это тест, предназначенный для оценки и расширения возможностей мультимодальных моделей в понимании и извлечении информации из длинных видеороликов продолжительностью до двух часов.
2024.08.2 Мы настраиваем таблицу лидеров LVBench на Huggingface Spaces! Проверьте таблицу лидеров.
2024.06.11 Мы выпустили LVBench, новый тест для понимания длинных видео!
LVBench — это тест, предназначенный для оценки возможностей моделей в понимании длинных видеороликов. Мы собрали обширные длинные видеоданные из общедоступных источников, аннотированные вручную и с помощью модели. Наш эталонный тест обеспечивает надежную основу для тестирования моделей в расширенных временных контекстах, обеспечивая высококачественную оценку за счет тщательного человеческого аннотирования и многоступенчатого контроля качества.
Основные возможности : шесть основных возможностей для понимания длинных видео, позволяющих создавать сложные и сложные вопросы для всесторонней оценки модели.
Разнообразные данные : разнообразный диапазон длинных видеоданных, в среднем в пять раз длиннее, чем самые длинные существующие наборы данных, охватывающие различные категории.
Высококачественные аннотации : надежный эталон с тщательными человеческими аннотациями и многоступенчатыми процессами контроля качества.

Наш набор данных находится под лицензией CC-BY-NC-SA-4.0.
LVBench используется только для академических исследований. Коммерческое использование в любой форме запрещено. Мы не владеем авторскими правами на любые необработанные видеофайлы.
Если в LVBench обнаружено какое-либо нарушение прав, свяжитесь с [email protected] или напрямую сообщите о проблеме, и мы немедленно удалим ее.
Сначала установите video2dataset:
pip установить video2dataset pip удалить трансформатор-двигатель
Затем вам следует скачать video_info.meta.jsonl с Huggingface и поместить его в каталог data .
Каждая запись в файле video_info.meta.jsonl имеет ключевое поле, соответствующее идентификатору видео YouTube. Пользователи могут загрузить соответствующее видео, используя этот идентификатор. Кроме того, пользователи могут использовать для загрузки предоставленный нами сценарий загрузки, download.sh:
CD-скрипты bash скачать.sh
После выполнения видеофайлы будут сохранены в каталоге script/videos .
пип установить -e .
(Примечание: если вы хотите быстро выполнить оценку, вы можете использовать scripts/construct_random_answers.py для подготовки файла случайных ответов.)
CD-скрипты python test_acc.py
После выполнения вы получите файл результатов оценки result.json в каталоге scripts . Вы можете отправить результаты в таблицу лидеров.
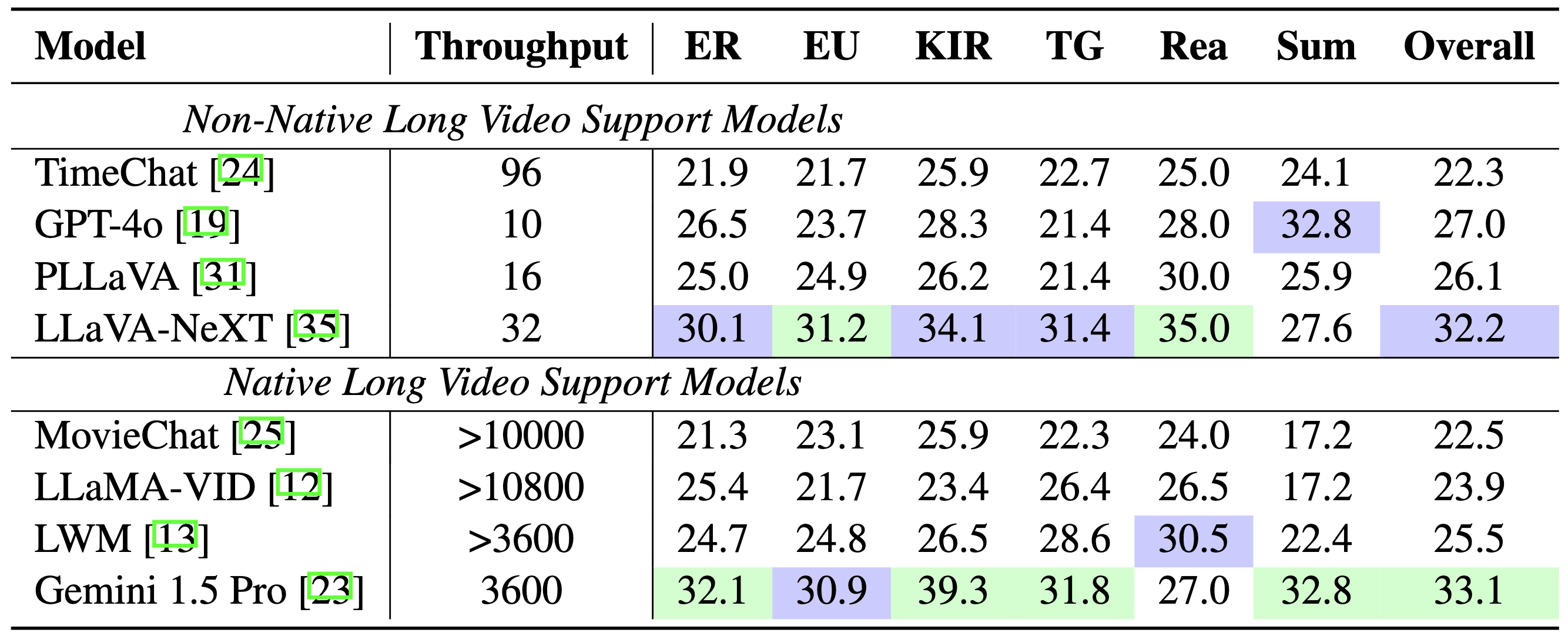
Сравнение моделей:
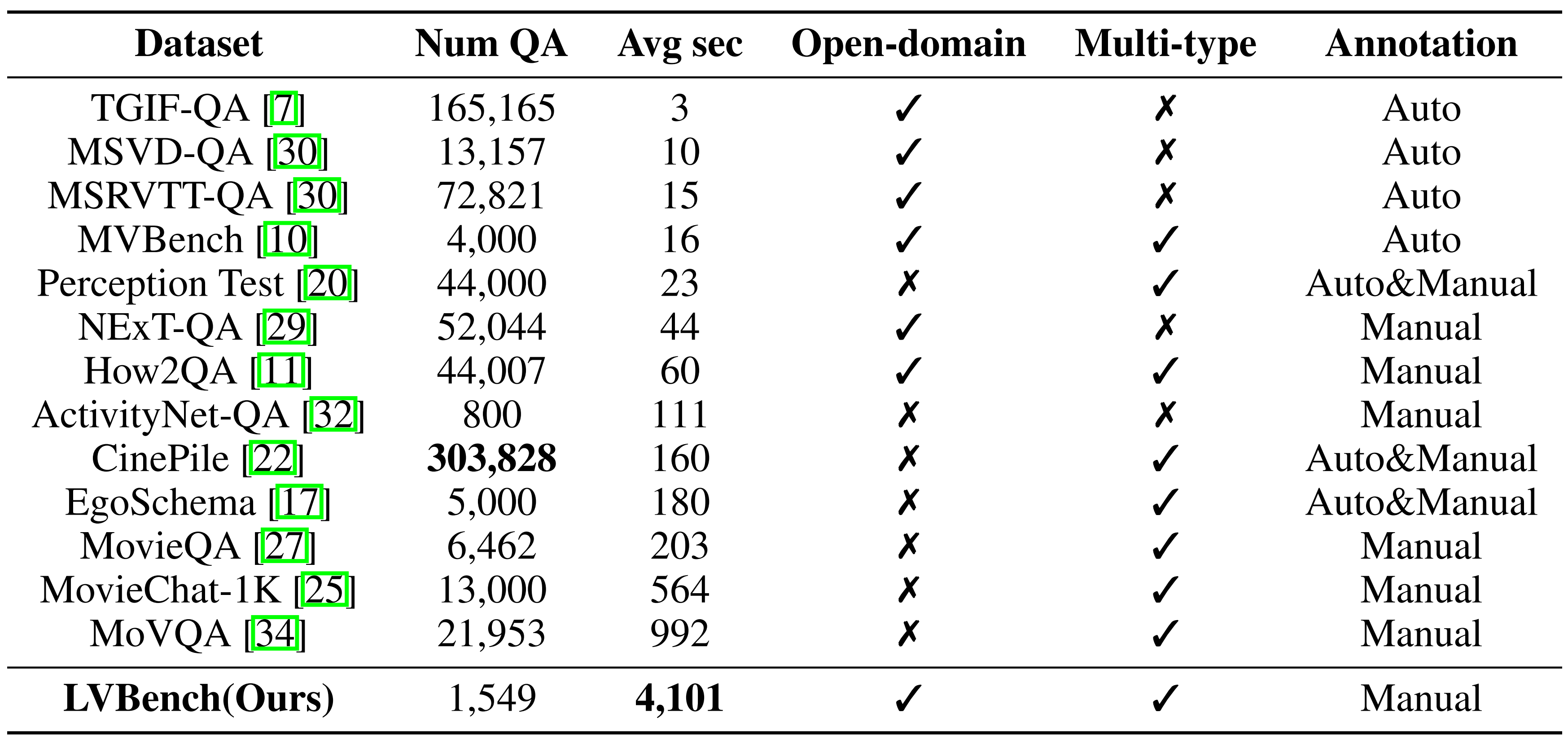
Сравнительное сравнение:
Модель против человека:

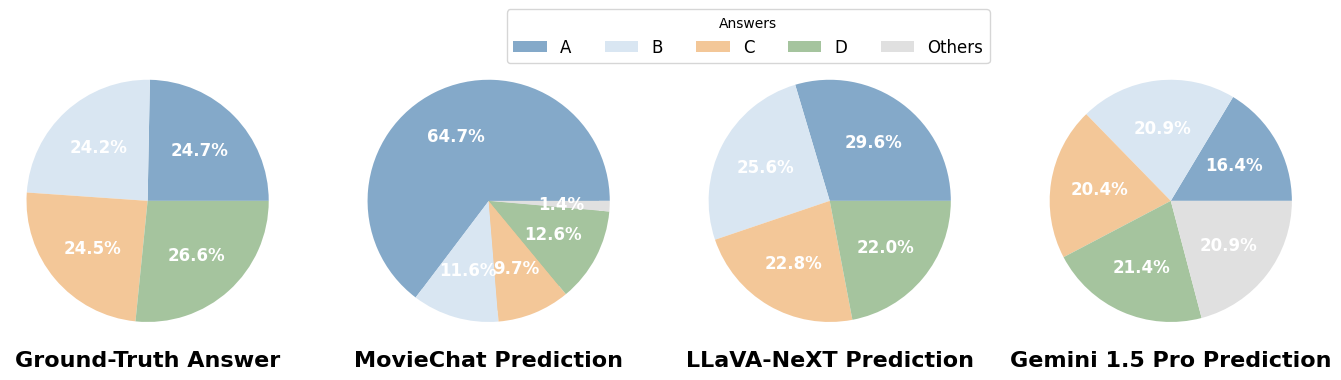
Распределение ответов:
Если вы найдете нашу работу полезной для вашего исследования, пожалуйста, рассмотрите возможность цитирования нашей работы.
@misc{wang2024lvbench, title={LVBench: тест понимания чрезвычайно длинных видео},
author={Вэйхан Ван и Цзехай Хэ и Вэньи Хун и Йен Чэн и Сяохань Чжан и Цзи Ци и Шиюй Хуан и Бинь Сюй и Юсяо Дун и Мин Дин и Цзе Тан}, год={2024}, eprint={2406.08035}, archivePrefix ={arXiv}, PrimaryClass={cs.CV}} 

