Инструмент для расширения тезауруса с использованием методов распространения меток. На основе корпуса текстов и существующего тезауруса он генерирует предложения по расширению существующих наборов синонимов. Этот инструмент был разработан во время магистерской диссертации « Распространение меток для расширения тезауруса налогового права » на кафедре «Разработка программного обеспечения для систем бизнес-информации (sebis)» Мюнхенского технического университета (TUM).
Автореферат диссертации. С ростом цифровизации поиску информации приходится справляться с растущими объемами цифрового контента. Поставщики легального контента вкладывают много денег в создание предметно-ориентированных онтологий, таких как тезаурусы, для получения значительно большего количества соответствующих документов. С 2002 года было разработано множество методов распространения меток, например, для идентификации групп похожих узлов в графах. Распространение меток — это семейство алгоритмов машинного обучения с полуконтролем на основе графов. В этой диссертации мы проверим пригодность методов распространения меток для расширения тезауруса из области налогового законодательства. Граф, на котором происходит распространение меток, представляет собой граф подобия, построенный на основе вложений слов. Мы освещаем процесс от начала до конца и проводим несколько исследований параметров, чтобы понять влияние определенных гиперпараметров на общую производительность. Затем результаты оцениваются в ручных исследованиях и сравниваются с базовым подходом.
Инструмент был реализован с использованием следующей архитектуры каналов и фильтров:
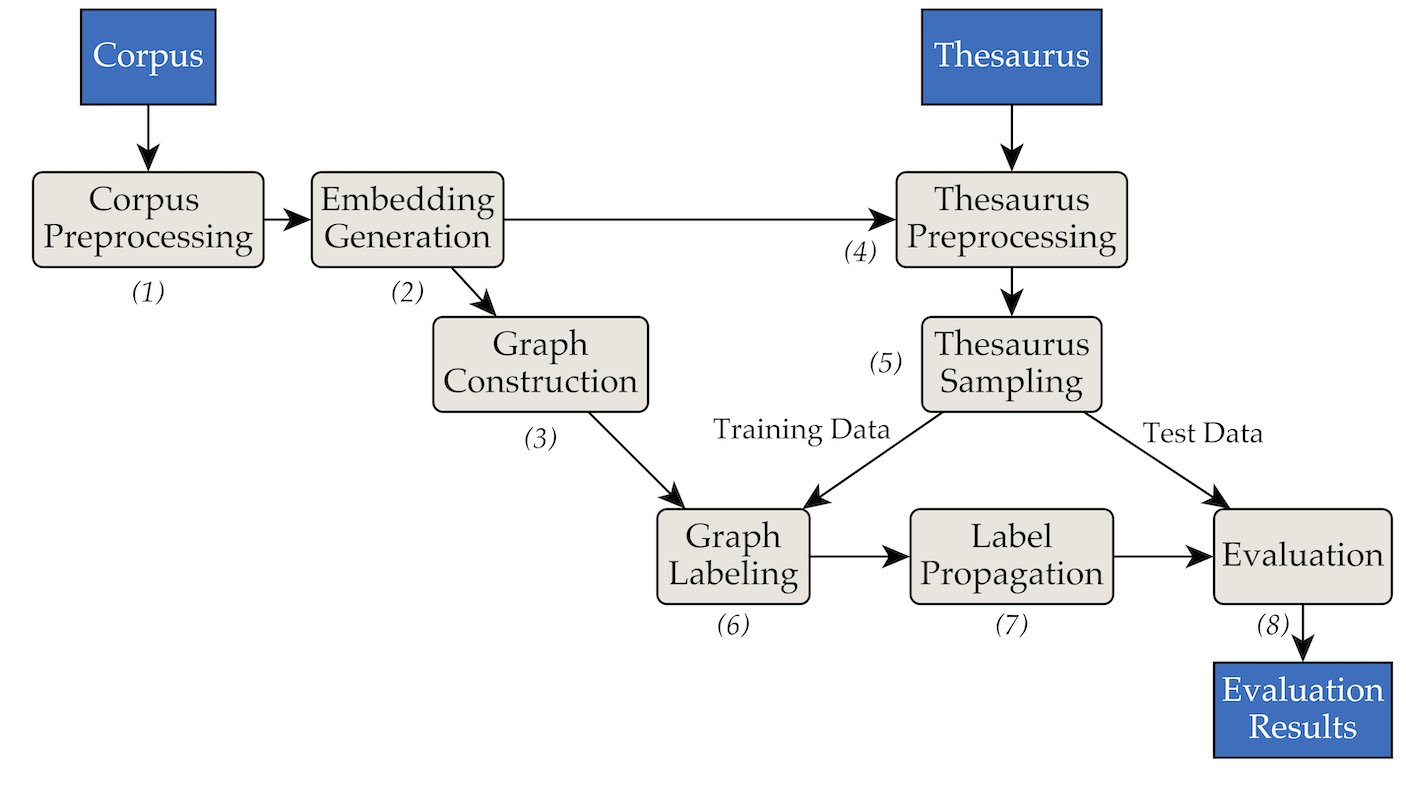
pipenv (Руководство по установке).pipenv install . data/RW40jsons и тезаурус в data/german_relat_pretty-20180605.json . См. Phase1.py и Phase4.py для получения информации об ожидаемых форматах файлов.output/<PHASE_FOLDER>/<DATE> . Наиболее важными являются 08_propagation_evaluation и XX_runs . В 08_propagation_evaluation статистика оценки хранится как stats.json вместе с таблицей, содержащей прогнозы, обучающий и тестовый набор ( main.txt , в других скриптах чаще всего называемый df_evaluation ). В XX_runs хранится журнал запуска. Если через multi_runs.py было запущено несколько прогонов (каждый с разным набором обучения/тестов), объединенная статистика всех отдельных прогонов также сохраняется как all_stats.json . С помощью purew2v_parameter_studies.py можно выполнить базовую линию вектора синсета, которую мы представили в нашей диссертации. Для этого требуется набор вложений слов и одно или несколько разделов обучения/тестирования тезауруса. См. пример sample_commands.md.
В ipynbs мы предоставили несколько образцовых блокнотов Jupyter, которые использовались для создания (а) статистики, (б) диаграмм и (в) файлов Excel для ручных оценок. Вы можете изучить их, запустив pipenv shell , а затем запустив Jupyter с помощью jupyter notebook .
main.py или multi_run.py .

