Большой языковой модельный курс
? Следуй за мной на X • ? Обнимающее лицо • Блог • ? Практический GNN
Курс LLM разделен на три части:
- ? LLM Fundamentals охватывает основные знания о математике, Python и нейронных сетях.
- ?? LLM Scientist фокусируется на создании наилучших LLM с использованием новейших технологий.
- ? Инженер LLM занимается созданием приложений на основе LLM и их развертыванием.
Для интерактивной версии этого курса я создал двух помощников LLM , которые будут отвечать на вопросы и индивидуально проверять ваши знания:
- ? HuggingChat Assistant : бесплатная версия с использованием Mixtral-8x7B.
- ? ChatGPT Assistant : требуется премиум-аккаунт.
Ноутбуки
Список блокнотов и статей, посвященных большим языковым моделям.
Инструменты
| Блокнот | Описание | Блокнот |
|---|
| ? LLM AutoEval | Автоматически оценивайте свои LLM с помощью RunPod | |
| ? ЛенивыйMergekit | Легко объединяйте модели с помощью MergeKit в один клик. | |
| ? ЛенивыйАксолотль | Точная настройка моделей в облаке с помощью Axolotl в один клик. | |
| ⚡ АвтоКвант | Квантуйте LLM в форматах GGUF, GPTQ, EXL2, AWQ и HQQ одним щелчком мыши. | |
| ? Модель генеалогического древа | Визуализируйте генеалогическое древо объединенных моделей. | |
| Нулевое пространство | Автоматически создавайте интерфейс чата Gradio с помощью бесплатного ZeroGPU. | |
Тонкая настройка
| Блокнот | Описание | Статья | Блокнот |
|---|
| Точная настройка Llama 2 с помощью QLoRA | Пошаговое руководство по контролируемой точной настройке Llama 2 в Google Colab. | Статья | |
| Точная настройка CodeLlama с помощью Axolotl | Полное руководство по современному инструменту для тонкой настройки. | Статья | |
| Точная настройка Мистраля-7б с помощью QLoRA | Руководил доводкой Мистраля-7б в бесплатном Google Colab с TRL. | | |
| Доработка Мистраля-7б с ДПО | Повысьте производительность контролируемых точно настроенных моделей с помощью DPO. | Статья | |
| Точная настройка Llama 3 с помощью ORPO | Дешевле и быстрее доводка в один этап с ОРПО. | Статья | |
| Точная настройка Llama 3.1 с помощью Unsloth | Сверхэффективная контролируемая точная настройка в Google Colab. | Статья | |
Квантование
| Блокнот | Описание | Статья | Блокнот |
|---|
| Введение в квантование | Оптимизация большой языковой модели с использованием 8-битного квантования. | Статья | |
| 4-битное квантование с использованием GPTQ | Квантизируйте свои собственные LLM с открытым исходным кодом, чтобы запускать их на потребительском оборудовании. | Статья | |
| Квантование с помощью GGUF и llama.cpp | Квантизируйте модели Llama 2 с помощью llama.cpp и загрузите версии GGUF в HF Hub. | Статья | |
| ExLlamaV2: самая быстрая библиотека для запуска LLM | Квантуйте и запускайте модели EXL2 и загружайте их в HF Hub. | Статья | |
Другой
| Блокнот | Описание | Статья | Блокнот |
|---|
| Стратегии декодирования в больших языковых моделях | Руководство по генерации текста от поиска луча до отбора проб ядра | Статья | |
| Улучшите ChatGPT с помощью графиков знаний | Дополните ответы ChatGPT диаграммами знаний. | Статья | |
| Объедините LLM с помощью MergeKit | Легко создавайте свои собственные модели без необходимости использования графического процессора! | Статья | |
| Создавайте МО с помощью MergeKit | Объедините нескольких экспертов в один FrankenMoE | Статья | |
| Отмените цензуру любого LLM с аблитерацией | Точная настройка без переобучения | Статья | |
? Основы магистратуры магистратуры
В этом разделе представлены основные знания о математике, Python и нейронных сетях. Возможно, вам не захочется начинать здесь, но обращайтесь к нему по мере необходимости.
Переключить раздел
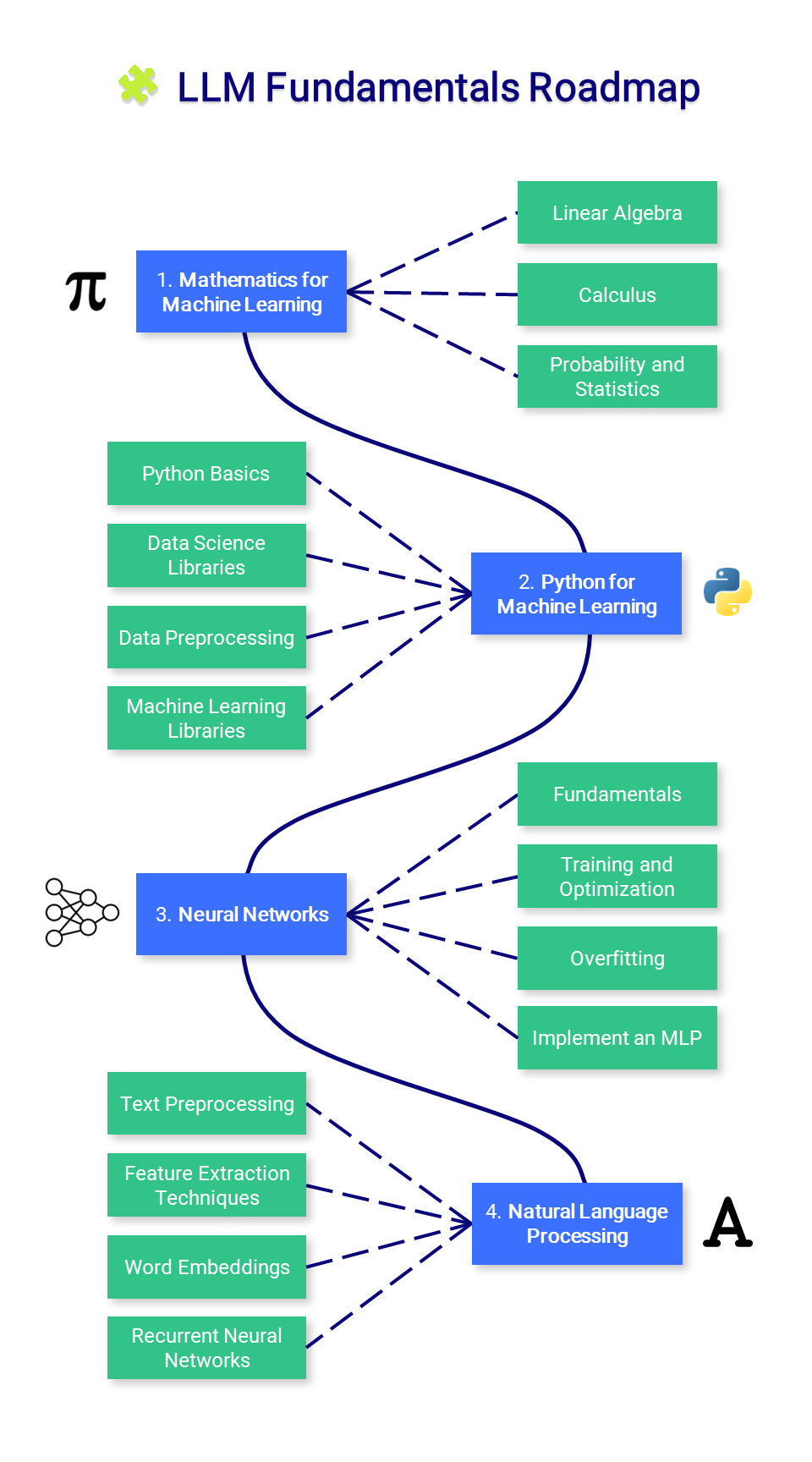
1. Математика для машинного обучения
Прежде чем освоить машинное обучение, важно понять фундаментальные математические концепции, лежащие в основе этих алгоритмов.
- Линейная алгебра : это имеет решающее значение для понимания многих алгоритмов, особенно тех, которые используются в глубоком обучении. Ключевые понятия включают векторы, матрицы, определители, собственные значения и собственные векторы, векторные пространства и линейные преобразования.
- Исчисление . Многие алгоритмы машинного обучения включают оптимизацию непрерывных функций, что требует понимания производных, интегралов, пределов и рядов. Многомерное исчисление и концепция градиентов также важны.
- Вероятность и статистика : они имеют решающее значение для понимания того, как модели учатся на данных и делают прогнозы. Ключевые понятия включают теорию вероятностей, случайные величины, распределения вероятностей, ожидания, дисперсию, ковариацию, корреляцию, проверку гипотез, доверительные интервалы, оценку максимального правдоподобия и байесовский вывод.
Ресурсы:
- 3Blue1Brown — Сущность линейной алгебры: серия видеороликов, которые дают геометрическое представление об этих концепциях.
- StatQuest с Джошем Стармером - Основы статистики: предлагает простые и ясные объяснения многих статистических концепций.
- AP Статистика Интуиция г-жи Аэрин: список статей Medium, в которых представлена интуиция, лежащая в основе каждого распределения вероятностей.
- Иммерсивная линейная алгебра: еще одна визуальная интерпретация линейной алгебры.
- Академия Хана — Линейная алгебра: отлично подходит для начинающих, поскольку объясняет концепции очень интуитивно.
- Академия Хана - Исчисление: интерактивный курс, охватывающий все основы исчисления.
- Академия Хана – Вероятность и статистика: предоставляет материал в простом для понимания формате.
2. Python для машинного обучения
Python — это мощный и гибкий язык программирования, который особенно хорош для машинного обучения благодаря своей читабельности, согласованности и надежной экосистеме библиотек обработки данных.
- Основы Python . Программирование на Python требует хорошего понимания основного синтаксиса, типов данных, обработки ошибок и объектно-ориентированного программирования.
- Библиотеки обработки данных : включает в себя знакомство с NumPy для числовых операций, Pandas для манипулирования и анализа данных, Matplotlib и Seaborn для визуализации данных.
- Предварительная обработка данных . Сюда входит масштабирование и нормализация функций, обработка недостающих данных, обнаружение выбросов, категориальное кодирование данных и разделение данных на обучающие, проверочные и тестовые наборы.
- Библиотеки машинного обучения . Крайне важно знание Scikit-learn, библиотеки, предоставляющей широкий выбор контролируемых и неконтролируемых алгоритмов обучения. Важно понимать, как реализовать такие алгоритмы, как линейная регрессия, логистическая регрессия, деревья решений, случайные леса, k-ближайшие соседи (K-NN) и кластеризация K-средних. Методы уменьшения размерности, такие как PCA и t-SNE, также полезны для визуализации многомерных данных.
Ресурсы:
- Real Python: обширный ресурс со статьями и учебными пособиями как для начинающих, так и для продвинутых пользователей Python.
- freeCodeCamp — Изучите Python: длинное видео, которое дает полное представление обо всех основных концепциях Python.
- Справочник по Python Data Science: бесплатная цифровая книга, которая является отличным ресурсом для изучения pandas, NumPy, Matplotlib и Seaborn.
- freeCodeCamp — Машинное обучение для всех: Практическое введение в различные алгоритмы машинного обучения для начинающих.
- Udacity — Введение в машинное обучение: бесплатный курс, охватывающий PCA и некоторые другие концепции машинного обучения.
3. Нейронные сети
Нейронные сети являются фундаментальной частью многих моделей машинного обучения, особенно в области глубокого обучения. Для их эффективного использования необходимо полное понимание их конструкции и механики.
- Основы : сюда входит понимание структуры нейронной сети, такой как слои, веса, смещения и функции активации (сигмовидная, танх, ReLU и т. д.).
- Обучение и оптимизация : ознакомьтесь с обратным распространением ошибки и различными типами функций потерь, такими как среднеквадратическая ошибка (MSE) и перекрестная энтропия. Изучите различные алгоритмы оптимизации, такие как градиентный спуск, стохастический градиентный спуск, RMSprop и Adam.
- Переобучение . Поймите концепцию переоснащения (когда модель хорошо работает на обучающих данных, но плохо на невидимых данных) и изучите различные методы регуляризации (отсев, регуляризация L1/L2, ранняя остановка, увеличение данных), чтобы предотвратить это.
- Внедрение многоуровневого персептрона (MLP) . Создайте MLP, также известную как полностью подключенная сеть, с помощью PyTorch.
Ресурсы:
- 3Blue1Brown. Но что такое нейронная сеть? В этом видео интуитивно понятное объяснение нейронных сетей и их внутренней работы.
- freeCodeCamp — ускоренный курс глубокого обучения. В этом видео эффективно представлены все наиболее важные концепции глубокого обучения.
- Fast.ai — Практическое глубокое обучение: бесплатный курс, предназначенный для людей с опытом программирования, которые хотят узнать о глубоком обучении.
- Патрик Лебер — Учебные пособия по PyTorch: серия видеороликов для начинающих, желающих узнать о PyTorch.
4. Обработка естественного языка (НЛП)
НЛП — это увлекательная отрасль искусственного интеллекта, которая устраняет разрыв между человеческим языком и машинным пониманием. От простой обработки текста до понимания лингвистических нюансов, НЛП играет решающую роль во многих приложениях, таких как перевод, анализ настроений, чат-боты и многое другое.
- Предварительная обработка текста : изучите различные этапы предварительной обработки текста, такие как токенизация (разделение текста на слова или предложения), стемминг (приведение слов к их корневой форме), лемматизация (аналогично стеммингу, но с учетом контекста), удаление стоп-слов и т. д.
- Методы извлечения функций : познакомьтесь с методами преобразования текстовых данных в формат, понятный алгоритмам машинного обучения. Ключевые методы включают «мешок слов» (BoW), частоту терминов, обратную частоте документов (TF-IDF) и n-граммы.
- Встраивание слов : Встраивание слов — это тип представления слов, который позволяет словам со схожим значением иметь схожие представления. Ключевые методы включают Word2Vec, GloVe и FastText.
- Рекуррентные нейронные сети (RNN) : понимание работы RNN, типа нейронной сети, предназначенной для работы с последовательностями данных. Изучите LSTM и GRU — два варианта RNN, способные изучать долгосрочные зависимости.
Ресурсы:
- RealPython — НЛП с SpaCy в Python: исчерпывающее руководство по библиотеке spaCy для задач НЛП в Python.
- Kaggle — Руководство по НЛП: несколько блокнотов и ресурсов для практического объяснения НЛП на Python.
- Джей Аламмар — Иллюстрация Word2Vec: хороший справочник для понимания знаменитой архитектуры Word2Vec.
- Джейк Тэ — PyTorch RNN с нуля: практичная и простая реализация моделей RNN, LSTM и GRU в PyTorch.
- Блог колы — Понимание сетей LSTM: более теоретическая статья о сети LSTM.
?? Ученый-магистр права
В этом разделе курса основное внимание уделяется изучению того, как создавать наилучшие LLM, используя новейшие методы.
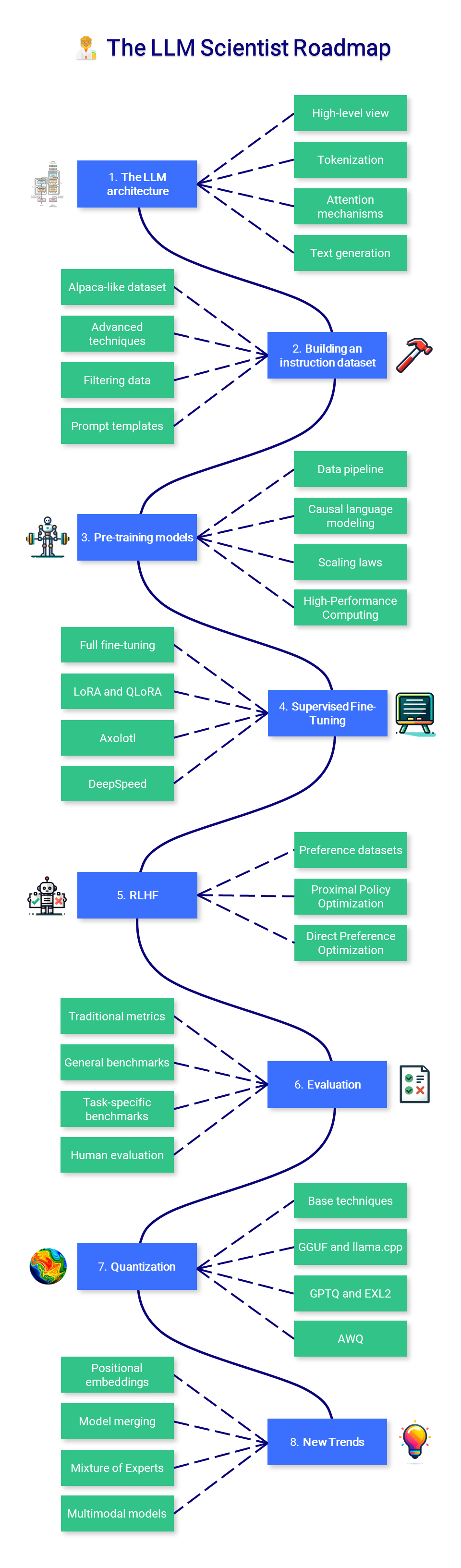
1. Архитектура LLM
Хотя глубокие знания об архитектуре Transformer не требуются, важно хорошо понимать его входы (токены) и выходы (логиты). Ванильный механизм внимания — еще один важный компонент, который необходимо освоить, поскольку позже будут представлены его улучшенные версии.
- Общий вид : еще раз рассмотрим архитектуру преобразователя кодировщика-декодера, а точнее, архитектуру GPT только для декодера, которая используется в каждом современном LLM.
- Токенизация . Узнайте, как преобразовать необработанные текстовые данные в формат, понятный модели, что включает в себя разделение текста на токены (обычно слова или подслова).
- Механизмы внимания . Поймите теорию, лежащую в основе механизмов внимания, включая самовнимание и внимание масштабированного скалярного произведения, что позволяет модели сосредотачиваться на различных частях входных данных при получении результата.
- Генерация текста : узнайте о различных способах, которыми модель может генерировать выходные последовательности. Общие стратегии включают жадное декодирование, поиск луча, выборку top-k и выборку ядра.
Ссылки :
- «Иллюстрированный трансформер» Джея Аламмара: визуальное и интуитивное объяснение модели трансформера.
- «Иллюстрированная GPT-2» Джея Аламмара: что еще более важно, чем предыдущая статья, она сосредоточена на архитектуре GPT, которая очень похожа на архитектуру Llama.
- Визуальное введение в Трансформеры от 3Blue1Brown: Простое и понятное визуальное введение в Трансформеры.
- Визуализация LLM от Брендана Байкрофта: невероятная 3D-визуализация того, что происходит внутри LLM.
- nanoGPT от Андрея Карпати: двухчасовое видео на YouTube, посвященное повторной реализации GPT с нуля (для программистов).
- Внимание? Внимание! Автор: Лилиан Венг: Представьте потребность во внимании более формально.
- Стратегии декодирования в LLM: предоставьте код и визуальное представление о различных стратегиях декодирования для генерации текста.
2. Создание набора данных инструкций
Хотя найти необработанные данные в Википедии и других веб-сайтах легко, собрать пары инструкций и ответов в реальных условиях сложно. Как и в традиционном машинном обучении, качество набора данных будет напрямую влиять на качество модели, поэтому оно может быть наиболее важным компонентом в процессе тонкой настройки.
- Набор данных, похожий на альпаку : генерируйте синтетические данные с нуля с помощью OpenAI API (GPT). Вы можете указать начальные значения и системные подсказки для создания разнообразного набора данных.
- Передовые методы : узнайте, как улучшить существующие наборы данных с помощью Evol-Instruct, как генерировать высококачественные синтетические данные, как в статьях Orca и phi-1.
- Фильтрация данных : традиционные методы, включающие регулярные выражения, удаление почти дубликатов, сосредоточение внимания на ответах с большим количеством токенов и т. д.
- Шаблоны подсказок . Не существует стандартного способа форматирования инструкций и ответов, поэтому важно знать о различных шаблонах чатов, таких как ChatML, Alpaca и т. д.
Ссылки :
- Подготовка набора данных для настройки инструкций Томаса Капелла: исследование наборов данных Alpaca и Alpaca-GPT4 и способы их форматирования.
- Создание набора данных клинических инструкций Солано Тодескини: руководство по созданию синтетического набора данных инструкций с использованием GPT-4.
- GPT 3.5 для классификации новостей от Кшитиза Сахай: используйте GPT 3.5 для создания набора данных инструкций для точной настройки Llama 2 для классификации новостей.
- Создание набора данных для тонкой настройки LLM: блокнот, содержащий несколько методов фильтрации набора данных и загрузки результатов.
- Шаблон чата от Мэтью Кэрригана: страница Hugging Face о шаблонах подсказок
3. Модели предварительного обучения
Предварительное обучение — очень длительный и дорогостоящий процесс, поэтому в данном курсе это не является целью. Хорошо иметь некоторое представление о том, что происходит во время предварительной тренировки, но практический опыт не требуется.
- Конвейер данных : предварительное обучение требует огромных наборов данных (например, Llama 2 был обучен на 2 триллионах токенов), которые необходимо отфильтровать, токенизировать и сопоставить с заранее определенным словарем.
- Причинное языковое моделирование : изучите разницу между причинным и маскированным языковым моделированием, а также функцию потерь, используемую в этом случае. Для эффективной предварительной подготовки узнайте больше о Megatron-LM или gpt-neox.
- Законы масштабирования . Законы масштабирования описывают ожидаемую производительность модели на основе размера модели, размера набора данных и объема вычислений, используемых для обучения.
- Высокопроизводительные вычисления : здесь это выходит за рамки, но дополнительные знания о HPC имеют фундаментальное значение, если вы планируете создать свой собственный LLM с нуля (аппаратное обеспечение, распределенная рабочая нагрузка и т. д.).
Ссылки :
- LLMDataHub от Джунхао Чжао: тщательно подобранный список наборов данных для предварительного обучения, точной настройки и RLHF.
- Обучение модели причинного языка с нуля с помощью Hugging Face: предварительно обучите модель GPT-2 с нуля, используя библиотеку преобразователей.
- TinyLlama от Чжана и др.: ознакомьтесь с этим проектом, чтобы получить хорошее представление о том, как обучается модель ламы с нуля.
- Причинное моделирование языка с помощью Hugging Face: объясните разницу между причинным и маскированным языковым моделированием, а также способы быстрой точной настройки модели DistilGPT-2.
- Дикие последствия шиншиллы от ностальгебраиста: обсудите законы масштабирования и объясните, что они значат для студентов магистратуры в целом.
- BLOOM от BigScience: страница с описанием того, как была построена модель BLOOM, с большим количеством полезной информации о инженерной части и возникших проблемах.
- Журнал OPT-175 от Meta: журналы исследований, показывающие, что пошло не так, а что — правильно. Полезно, если вы планируете предварительно обучить очень большую языковую модель (в данном случае 175B параметров).
- LLM 360: платформа для LLM с открытым исходным кодом с кодом обучения и подготовки данных, данными, метриками и моделями.
4. Контролируемая точная настройка
Предварительно обученные модели обучаются только задаче прогнозирования следующего токена, поэтому они не являются полезными помощниками. SFT позволяет настроить их так, чтобы они реагировали на инструкции. Более того, он позволяет вам точно настроить вашу модель на любых данных (частных, не видимых GPT-4 и т. д.) и использовать ее без необходимости платить за API, такой как OpenAI.
- Полная точная настройка . Полная точная настройка подразумевает обучение всех параметров модели. Это неэффективный метод, но он дает немного лучшие результаты.
- LoRA : метод с эффективным использованием параметров (PEFT), основанный на адаптерах низкого ранга. Вместо обучения всех параметров мы обучаем только эти адаптеры.
- QLoRA : еще один PEFT на основе LoRA, который также квантует веса модели в 4 бита и вводит страничные оптимизаторы для управления скачками памяти. Объедините его с Unsloth, чтобы эффективно использовать его на бесплатном ноутбуке Colab.
- Axolotl : удобный и мощный инструмент тонкой настройки, который используется во многих современных моделях с открытым исходным кодом.
- DeepSpeed : Эффективное предварительное обучение и тонкая настройка LLM для настроек с несколькими графическими процессорами и несколькими узлами (реализовано в Axolotl).
Ссылки :
- Учебное пособие по LLM для новичков от Alpin: обзор основных концепций и параметров, которые следует учитывать при точной настройке LLM.
- Идеи LoRA от Себастьяна Рашки: Практические советы о LoRA и о том, как выбрать лучшие параметры.
- Точная настройка вашей собственной модели Llama 2: практическое руководство о том, как точно настроить модель Llama 2 с использованием библиотек Hugging Face.
- Заполнение больших языковых моделей Бенджамина Мари: Лучшие практики по дополнению обучающих примеров для причинных LLM
- Руководство для начинающих по тонкой настройке LLM: руководство по точной настройке модели CodeLlama с помощью Axolotl.
5. Согласование предпочтений
После контролируемой тонкой настройки RLHF представляет собой шаг, используемый для согласования ответов LLM с человеческими ожиданиями. Идея состоит в том, чтобы изучить предпочтения на основе человеческой (или искусственной) обратной связи, которую можно использовать для уменьшения предвзятости, цензуры моделей или заставить их действовать более полезным образом. Он более сложен, чем SFT, и его часто считают необязательным.
- Наборы данных предпочтений . Эти наборы данных обычно содержат несколько ответов с определенным ранжированием, что затрудняет их создание, чем наборы данных инструкций.
- Оптимизация проксимальной политики . Этот алгоритм использует модель вознаграждения, которая предсказывает, имеет ли данный текст высокий рейтинг среди людей. Этот прогноз затем используется для оптимизации модели SFT со штрафом, основанным на расхождении KL.
- Прямая оптимизация предпочтений : DPO упрощает процесс, переосмысливая его как задачу классификации. Он использует эталонную модель вместо модели вознаграждения (обучение не требуется) и требует только одного гиперпараметра, что делает его более стабильным и эффективным.
Ссылки :
- Distilabel от Argilla: отличный инструмент для создания собственных наборов данных. Он был специально разработан для наборов данных предпочтений, но также может выполнять SFT.
- Введение в обучение LLM с использованием RLHF Аюша Тхакура: объясните, почему RLHF желателен для уменьшения предвзятости и повышения производительности в LLM.
- Иллюстрация RLHF от Hugging Face: введение в RLHF с обучением модели вознаграждения и тонкой настройкой с помощью обучения с подкреплением.
- Настройка предпочтений LLM с помощью Hugging Face: сравнение алгоритмов DPO, IPO и KTO для выравнивания предпочтений.
- Обучение LLM: RLHF и его альтернативы, Себастьян Рашка: Обзор процесса RLHF и альтернатив, таких как RLAIF.
- Тонкая настройка Мистраль-7б с помощью ДПО: Учебное пособие по точной настройке модели Мистраль-7б с помощью ДПО и воспроизведению NeuralHermes-2.5.
6. Оценка
Оценка LLM — недооцененная часть процесса, требующая много времени и умеренно надежная. Ваша последующая задача должна определять, что вы хотите оценить, но всегда помните закон Гудхарта: «Когда показатель становится целью, он перестает быть хорошим показателем».
- Традиционные метрики . Такие метрики, как недоумение и оценка BLEU, не так популярны, как раньше, потому что в большинстве контекстов они ошибочны. По-прежнему важно понимать их и то, когда их можно применять.
- Общие критерии : на основе системы оценки языковой модели таблица лидеров Open LLM является основным эталоном для LLM общего назначения (например, ChatGPT). Существуют и другие популярные тесты, такие как BigBench, MT-Bench и т. д.
- Контрольные показатели для конкретных задач . Такие задачи, как обобщение, перевод и ответы на вопросы, имеют специальные тесты, метрики и даже поддомены (медицинские, финансовые и т. д.), такие как PubMedQA для ответов на биомедицинские вопросы.
- Человеческая оценка . Наиболее надежной оценкой является степень принятия пользователями или сравнения, сделанные людьми. Регистрация отзывов пользователей в дополнение к отслеживанию чата (например, с помощью LangSmith) помогает выявить потенциальные области для улучшения.
Ссылки :
- Недоумение моделей фиксированной длины от Hugging Face: обзор недоумения с кодом для его реализации с помощью библиотеки преобразователей.
- BLEU на свой страх и риск Рэйчел Тэтман: Обзор оценки BLEU и ее многочисленных проблем с примерами.
- Обзор оценки LLM, проведенный Чангом и др.: Всеобъемлющий документ о том, что оценивать, где оценивать и как оценивать.
- Таблица лидеров Chatbot Arena от lmsys: рейтинг LLM общего назначения по Эло, основанный на сравнениях, проведенных людьми.
7. Квантование
Квантование — это процесс преобразования весов (и активаций) модели с использованием более низкой точности. Например, веса, хранящиеся в 16 битах, можно преобразовать в 4-битное представление. Этот метод становится все более важным для снижения затрат на вычисления и память, связанных с LLM.
- Базовые методы : изучите различные уровни точности (FP32, FP16, INT8 и т. д.) и способы выполнения простого квантования с использованием методов абсмакс и нулевой точки.
- GGUF и llama.cpp : изначально предназначенные для работы на процессорах, llama.cpp и формат GGUF стали наиболее популярными инструментами для запуска LLM на оборудовании потребительского уровня.
- GPTQ и EXL2 : GPTQ и, в частности, формат EXL2 обеспечивают невероятную скорость, но могут работать только на графических процессорах. Для квантования моделей также требуется много времени.
- AWQ : этот новый формат более точен, чем GPTQ (меньшая сложность), но использует гораздо больше видеопамяти и не обязательно быстрее.
Ссылки :
- Введение в квантование: обзор квантования, абсмаксного квантования и квантования с нулевой точкой, а также LLM.int8() с кодом.
- Квантизация моделей Llama с помощью llama.cpp: руководство по квантованию модели Llama 2 с использованием llama.cpp и формата GGUF.
- 4-битное квантование LLM с помощью GPTQ: руководство по квантованию LLM с использованием алгоритма GPTQ с AutoGPTQ.
- ExLlamaV2: самая быстрая библиотека для запуска LLM: руководство по квантованию модели Mistral с использованием формата EXL2 и запуску ее с библиотекой ExLlamaV2.
- Понимание квантования веса с учетом активации от FriendliAI: обзор метода AWQ и его преимуществ.
8. Новые тенденции
- Позиционные внедрения : узнайте, как LLM кодируют позиции, особенно схемы относительного позиционного кодирования, такие как RoPE. Внедрите YaRN (умножает матрицу внимания на температурный коэффициент) или ALiBi (штраф за внимание на основе расстояния между маркерами), чтобы увеличить длину контекста.
- Объединение моделей . Объединение обученных моделей стало популярным способом создания производительных моделей без какой-либо тонкой настройки. Популярная библиотека mergekit реализует самые популярные методы слияния, такие как SLERP, DARE и TIES.
- Смесь экспертов : Mixtral повторно популяризировала архитектуру MoE благодаря ее превосходной производительности. Параллельно в сообществе OSS появился своего рода FrankenMoE в результате слияния таких моделей, как Phixtral, который является более дешевым и производительным вариантом.
- Мультимодальные модели . Эти модели (такие как CLIP, Stable Diffusion или LLaVA) обрабатывают несколько типов входных данных (текст, изображения, аудио и т. д.) с единым пространством для встраивания, которое открывает мощные приложения, такие как преобразование текста в изображение.
Ссылки :
- Расширение RoPE от EleutherAI: статья, в которой обобщаются различные методы кодирования положения.
- Понимание YaRN, Раджат Чавла: Введение в YaRN.
- Объединение LLM с помощью mergekit: руководство по объединению моделей с помощью mergekit.
- Смесь экспертов, объясненная «Обнимающим лицом»: исчерпывающее руководство о МО и о том, как они работают.
- Большие мультимодальные модели Чипа Хьюена: обзор мультимодальных систем и недавней истории этой области.
? LLM-инженер
В этом разделе курса основное внимание уделяется изучению того, как создавать приложения на основе LLM, которые можно использовать в производстве, с упором на расширение моделей и их развертывание.
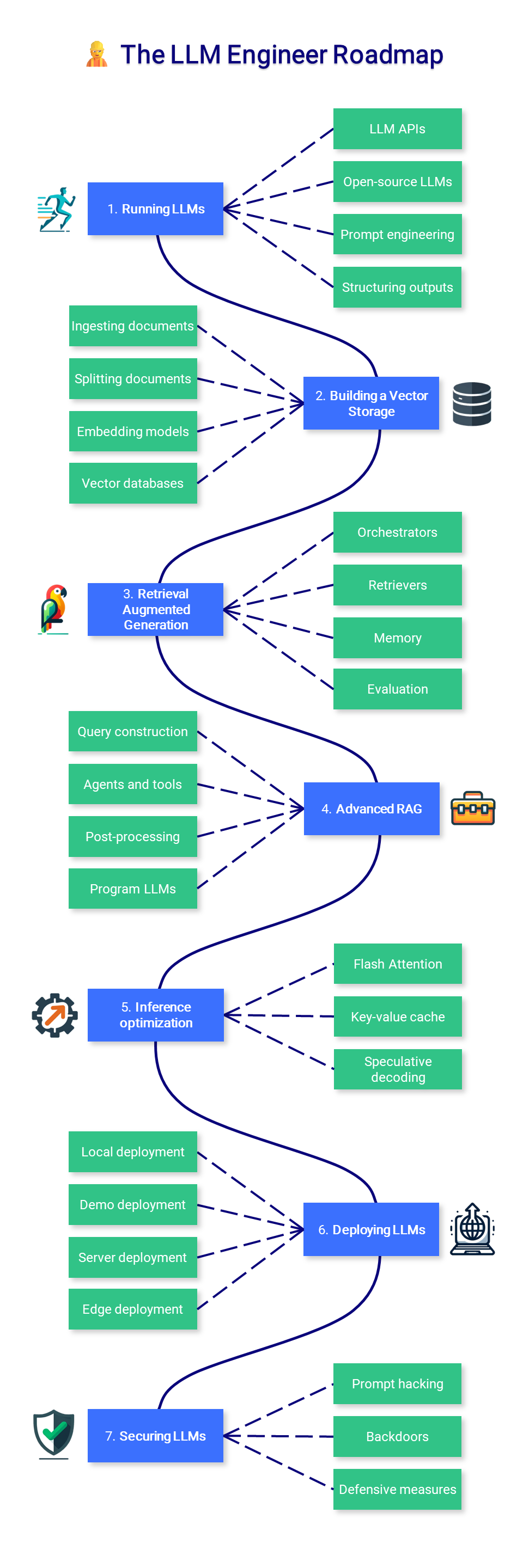
1. Проведение программ LLM
Запуск LLM может быть затруднен из-за высоких требований к оборудованию. В зависимости от вашего варианта использования вы можете просто использовать модель через API (например, GPT-4) или запустить ее локально. В любом случае дополнительные методы подсказок и указаний могут улучшить или ограничить результаты ваших приложений.
- API-интерфейсы LLM : API — это удобный способ развертывания LLM. Это пространство разделено между частными LLM (OpenAI, Google, Anthropic, Cohere и т. д.) и LLM с открытым исходным кодом (OpenRouter, Hugging Face, Together AI и т. д.).
- LLM с открытым исходным кодом : Hugging Face Hub — отличное место для поиска LLM. Вы можете запустить некоторые из них напрямую в Hugging Face Spaces или загрузить и запустить их локально в таких приложениях, как LM Studio, или через интерфейс командной строки с помощью llama.cpp или Ollama.
- Быстрое проектирование . Общие методы включают в себя подсказки с нулевым шагом, подсказки с несколькими действиями, цепочку мыслей и ReAct. Они лучше работают с более крупными моделями, но могут быть адаптированы и для меньших.
- Структурирование выходных данных . Многие задачи требуют структурированных выходных данных, например строгого шаблона или формата JSON. Такие библиотеки, как LMQL, Outlines, Guidance и т. д., можно использовать для управления созданием и соблюдения заданной структуры.
Ссылки :
- Запустите LLM локально с помощью LM Studio от Ниши Арья: Краткое руководство по использованию LM Studio.
- Руководство по быстрому проектированию от DAIR.AI: Исчерпывающий список методов быстрого проектирования с примерами.
- Outlines – Quickstart: список методов управляемого создания, доступных в Outlines.
- LMQL — Обзор: Введение в язык LMQL.
2. Создание векторного хранилища
Создание векторного хранилища — это первый шаг к построению конвейера дополненной генерации (RAG). Документы загружаются, разделяются, и соответствующие фрагменты используются для создания векторных представлений (вложений), которые сохраняются для будущего использования во время вывода.
- Загрузка документов . Загрузчики документов — это удобные оболочки, которые могут обрабатывать множество форматов: PDF, JSON, HTML, Markdown и т. д. Они также могут напрямую извлекать данные из некоторых баз данных и API (GitHub, Reddit, Google Drive и т. д.).
- Разделение документов . Разделители текста разбивают документы на более мелкие, семантически значимые фрагменты. Вместо разделения текста после n символов часто лучше разделить его по заголовку или рекурсивно с некоторыми дополнительными метаданными.
- Внедрение моделей . Внедрение моделей преобразует текст в векторные представления. Это позволяет глубже и детальнее понимать язык, что необходимо для выполнения семантического поиска.
- Базы данных векторов : Базы данных векторов (такие как Chroma, Pinecone, Milvus, FAISS, Annoy и т. д.) предназначены для хранения векторов внедрения. Они позволяют эффективно извлекать данные, которые «наиболее похожи» на запрос, основанный на сходстве векторов.
Ссылки :
- LangChain — Разделители текста: список различных разделителей текста, реализованных в LangChain.
- Библиотека Sentence Transformers: популярная библиотека для встраивания моделей.
- Таблица лидеров MTEB: таблица лидеров для встраивания моделей.
- Топ-5 векторных баз данных Моэза Али: сравнение лучших и самых популярных векторных баз данных.
3. Поисковая дополненная генерация
С помощью RAG студенты LLM извлекают контекстуальные документы из базы данных, чтобы повысить точность своих ответов. RAG — популярный способ пополнить знания модели без какой-либо тонкой настройки.
- Оркестраторы : Оркестраторы (такие как LangChain, LlamaIndex, FastRAG и т. д.) — это популярные платформы для подключения ваших LLM к инструментам, базам данных, памяти и т. д. и расширения их возможностей.
- Поисковые системы : инструкции пользователя не оптимизированы для поиска. Для их перефразирования/расширения и повышения производительности можно применять различные методы (например, многозапросный поиск, HyDE и т. д.).
- Память : чтобы запомнить предыдущие инструкции и ответы, LLM и чат-боты, такие как ChatGPT, добавляют эту историю в свое контекстное окно. Этот буфер можно улучшить с помощью суммирования (например, используя меньший LLM), векторного хранилища + RAG и т. д.
- Оценка : нам необходимо оценить как поиск документа (точность контекста и отзыв), так и этапы генерации (достоверность и релевантность ответа). Его можно упростить с помощью инструментов Ragas и DeepEval.
Ссылки :
- Llammaindex — Концепции высокого уровня: основные концепции, которые следует знать при построении конвейеров RAG.
- Сосновая шишка — Аугментация поиска: Обзор процесса аугментации поиска.
- LangChain — вопросы и ответы с RAG: пошаговое руководство по созданию типичного конвейера RAG.
- LangChain — Типы памяти: список различных типов памяти с соответствующим использованием.
- Конвейер RAG — метрики: обзор основных показателей, используемых для оценки конвейеров RAG.
4. Продвинутая тряпка
Реальные приложения могут требовать сложных конвейеров, включая базы данных SQL или графов, а также автоматический выбор соответствующих инструментов и API. Эти передовые методы могут улучшить базовое решение и предоставить дополнительные функции.
- Построение запроса . Структурированные данные, хранящиеся в традиционных базах данных, требуют определенного языка запросов, такого как SQL, Cypher, метаданные и т. д. Мы можем напрямую преобразовать пользовательскую инструкцию в запрос для доступа к данным с помощью построения запроса.
- Агенты и инструменты . Агенты дополняют LLM, автоматически выбирая наиболее подходящие инструменты для предоставления ответа. Эти инструменты могут быть такими же простыми, как использование Google или Википедии, или более сложными, например, интерпретатор Python или Jira.
- Постобработка : последний этап обработки входных данных, поступающих в LLM. Это повышает актуальность и разнообразие документов, полученных с помощью повторного ранжирования, объединения RAG и классификации.
- Программы LLM : такие платформы, как DSPy, позволяют оптимизировать подсказки и веса на основе автоматических оценок программным способом.
Ссылки :
- LangChain — Построение запросов: сообщение в блоге о различных типах построения запросов.
- LangChain — SQL: руководство по взаимодействию с базами данных SQL с помощью LLM, включая преобразование текста в SQL и дополнительный агент SQL.
- Сосновая шишка - Агенты LLM: Знакомство с агентами и инструментами разных типов.
- Автономные агенты на базе LLM, Лилиан Венг: Более теоретическая статья об агентах LLM.
- LangChain — RAG OpenAI: обзор стратегий RAG, используемых OpenAI, включая постобработку.
- DSPy за 8 шагов: Общее руководство по DSPy, знакомящее с модулями, сигнатурами и оптимизаторами.
5. Оптимизация вывода
Генерация текста — дорогостоящий процесс, требующий дорогостоящего оборудования. Помимо квантования, были предложены различные методы для максимизации пропускной способности и снижения затрат на вывод.
- Flash Attention : оптимизация механизма внимания для преобразования его сложности из квадратичной в линейную, ускоряя как обучение, так и вывод.
- Кэш «ключ-значение» . Познакомьтесь с кешем «ключ-значение» и улучшениями, представленными в функциях «Внимание к множественным запросам» (MQA) и «Внимание к групповым запросам» (GQA).
- Спекулятивное декодирование . Используйте небольшую модель для создания черновиков, которые затем проверяются более крупной моделью, чтобы ускорить генерацию текста.
Ссылки :
- Вывод на основе графического процессора с помощью объятия лица: объясните, как оптимизировать вывод на графических процессорах.
- Вывод LLM от Databricks: лучшие практики оптимизации вывода LLM в производстве.
- Оптимизация LLM для скорости и памяти путем объятия лица: объясните три основных метода оптимизации скорости и памяти, а именно квантование, мгновенное внимание и архитектурные инновации.
- Assisted Generation by Hugging Face: версия спекулятивного декодирования HF, это интересный пост в блоге о том, как он работает с кодом для его реализации.
6. Развертывание LLM
Масштабное развертывание LLM — это инженерный подвиг, для которого может потребоваться несколько кластеров графических процессоров. В других сценариях создание демо-версий и локальных приложений может быть гораздо проще.
- Локальное развертывание . Конфиденциальность — важное преимущество LLM с открытым исходным кодом перед частными. Локальные серверы LLM (LM Studio, Ollama, oobabooga, kobold.cpp и т. д.) используют это преимущество для поддержки локальных приложений.
- Демонстрационное развертывание . Такие платформы, как Gradio и Streamlit, полезны для создания прототипов приложений и обмена демонстрационными версиями. Вы также можете легко разместить их в Интернете, например, используя обнимающие места для лица.
- Развертывание сервера : развертывание LLMS в масштабе требует облака (см. Также Skypilot) или в инфраструктуре на объекте и часто используют оптимизированные структуры генерации текста, такие как TGI, VLLM и т. Д.
- Развертывание Edge : в ограниченных средах высокопроизводительные рамки, такие как MLC LLM и MNN-LLM, могут развернуть LLM в веб-браузерах, Android и iOS.
Ссылки :
- Streamlit - Создайте базовое приложение LLM: Учебное пособие, чтобы сделать базовое приложение, похожее на CHATGPT, используя Streamlit.
- HF LLM Контейнер с выводом: развернуть LLMS на Amazon SageMaker, используя контейнер с выводом Huging Face.
- Блог Philschmid от Philipp Schmid: Коллекция высококачественных статей о развертывании LLM с использованием Amazon Sagemaker.
- Оптимизация латентности Хэмел Хусейн: сравнение TGI, VLLM, CTRANSLATE2 и MLC с точки зрения пропускной способности и задержки.
7. ЗАЩИТА LLMS
В дополнение к традиционным проблемам безопасности, связанным с программным обеспечением, LLM имеют уникальные недостатки из -за того, как они обучены и побуждаются.
- Быстрый взлом : различные методы, связанные с быстрой техникой, включая быстрое впрыск (дополнительная инструкция по ужесточению ответа модели), утечка данных/приглашение (извлечь свои первоначальные данные/подсказку) и джейлбрейк (ремесло подсказки для обхода функций безопасности).
- Backdoors : векторы атаки могут нацелиться на самим учебные данные, отравляя учебные данные (например, с ложной информацией) или создавая бэкдоры (секретные триггеры, чтобы изменить поведение модели во время вывода).
- Оборонительные меры : Лучший способ защитить ваши приложения LLM - это проверить их от этих уязвимостей (например, использование красной команды и проверок, таких как Гарак) и наблюдать за ними в производстве (с такими рамками, как Langfuse).
Ссылки :
- Owasp LLM Top 10 от Hego Wiki: Список 10 самых критических уязвимостей, наблюдаемых в приложениях LLM.
- Обратный инъекционный учебник Джозефа Теккера: короткий гид, посвященный быстрому впрыскиванию для инженеров.
- LLM Security от @llm_sec: обширный список ресурсов, связанных с безопасностью LLM.
- Red Teaming LLMS от Microsoft: Руководство о том, как выполнить Red Teaming с LLMS.
Благодарности
Эта дорожная карта была вдохновлена превосходной дорожной картой Devops от Милана Милановича и Романо Рота.
Особая благодарность:
- Томас Телен за мотивацию меня создать дорожную карту
- Андре Фраде за его вклад и обзор первого проекта
- Dino Dunn за предоставление ресурсов о безопасности LLM
- Магдалена Кун за улучшение части «человеческой оценки»
- Одовердоз за предложение видео 3BLUE1Brown о трансформаторах
Отказ от ответственности: я не связан с какими -либо источниками, перечисленными здесь.


