Ян Цзоу, Чонхон Чжон, Лата Пемула, Дунцин Чжан, Онкар Дабир.
В этом репозитории содержатся ресурсы для нашей статьи ECCV-2022 «Самоконтролируемая предварительная тренировка по выявлению различий для обнаружения аномалий и сегментации». В настоящее время мы выпускаем набор данных Visual Anomaly (VisA).
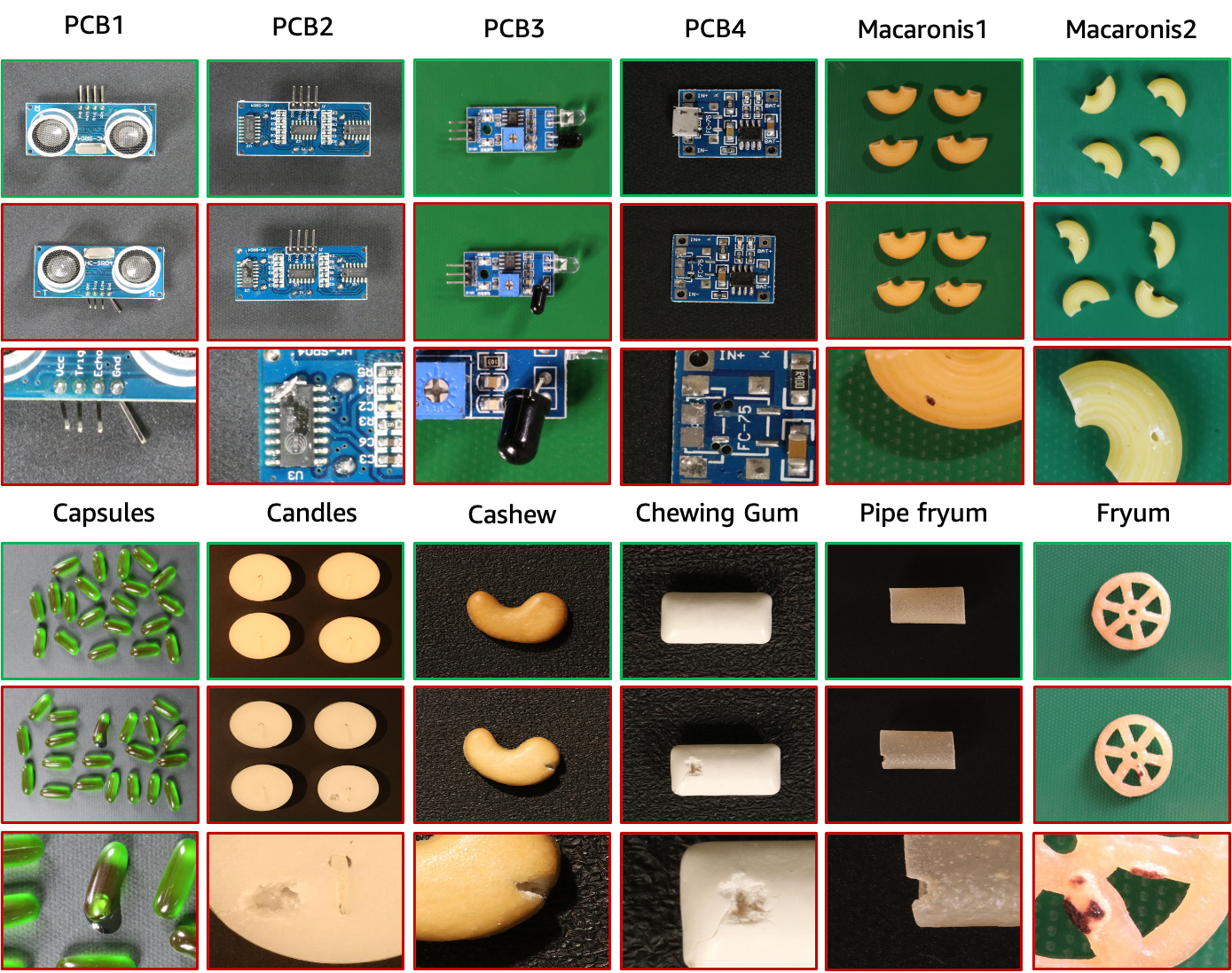
Набор данных VisA содержит 12 подмножеств, соответствующих 12 различным объектам, как показано на рисунке выше. Имеется 10 821 изображение с 9 621 нормальным и 1 200 аномальным образцами. Четыре подмножества — это разные типы печатных плат (PCB) с относительно сложной структурой, содержащей транзисторы, конденсаторы, микросхемы и т. д. Для случая нескольких экземпляров в представлении мы собираем четыре подмножества: Капсулы, Свечи, Макароны1 и Макароны2. Экземпляры в «Капсулах» и «Макаронах2» во многом различаются локациями и позами. Более того, мы собираем четыре подмножества, включая Кешью, Жевательную резинку, Фрюм и Пайп-фрюм, где объекты примерно выровнены. Аномальные изображения содержат различные дефекты, в том числе поверхностные дефекты, такие как царапины, вмятины, цветные пятна или трещины, а также структурные дефекты, такие как неправильное расположение или отсутствие деталей.
| Объект | # нормальных образцов | # образцов аномалий | # классы аномалий | тип объекта |
|---|---|---|---|---|
| печатная плата1 | 1004 | 100 | 4 | Сложная структура |
| печатная плата2 | 1001 | 100 | 4 | Сложная структура |
| печатная плата3 | 1006 | 100 | 4 | Сложная структура |
| печатная плата4 | 1005 | 100 | 7 | Сложная структура |
| Капсулы | 602 | 100 | 5 | Несколько экземпляров |
| Свечи | 1000 | 100 | 8 | Несколько экземпляров |
| Макароны1 | 1000 | 100 | 7 | Несколько экземпляров |
| Макароны2 | 1000 | 100 | 7 | Несколько экземпляров |
| Кешью | 500 | 100 | 9 | Один экземпляр |
| Жевательная резинка | 503 | 100 | 6 | Один экземпляр |
| Фрюм | 500 | 100 | 8 | Один экземпляр |
| Трубка фрюм | 500 | 100 | 9 | Один экземпляр |
Мы размещаем набор данных VisA в AWS S3, и вы можете загрузить его по этому URL-адресу.
Дерево данных загруженных данных выглядит следующим образом.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv предоставляет метку уровня изображения и маску аннотации уровня пикселя для каждого изображения. Функции карты id2class для многоклассовых масок можно найти в ./utils/id2class.py. Здесь маски для обычных изображений не сохраняются для экономии места.
Чтобы подготовить настройки 1-класса, 2-класса-highshot и 2-class-fewshot, описанные в исходной статье, мы используем ./utils/prepare_data.py для реорганизации данных после файлов разделения данных в «./split_csv/». . Мы приводим пример командной строки для подготовки к установке 1-го класса следующим образом.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
Дерево данных реорганизованной установки 1-го класса выглядит следующим образом.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...В частности, реорганизованные данные для настройки 1-го класса соответствуют дереву данных MVTec-AD. Для каждого объекта данные имеют три папки:
Обратите внимание, что многоклассовые маски сегментации истинной истины в исходном наборе данных переиндексируются в двоичные маски, где 0 указывает на нормальность, а 255 указывает на аномалию.
Кроме того, настройки из двух классов можно подготовить аналогичным образом, изменив аргументы готовых_данных.py.
Чтобы вычислить показатели классификации и сегментации, обратитесь к ./utils/metrics.py. Обратите внимание, что при вычислении метрик локализации мы учитываем обычные выборки. Это отличается от некоторых других работ, игнорирующих обычные образцы локализации.
Пожалуйста, процитируйте следующую статью, если этот набор данных поможет вашему проекту:
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}Данные публикуются под лицензией CC BY 4.0.


