Этот репозиторий содержит код PyTorch для Motif, обучающий ИИ-агентов NetHack с функциями вознаграждения, полученными на основе предпочтений LLM.
Мотив: внутренняя мотивация, основанная на обратной связи с искусственным интеллектом.
Мартин Клиссаров* и Пьерлука Д'Оро*, Шагун Содхани, Роберта Райляну, Пьер-Люк Бэкон, Паскаль Винсент, Эми Чжан и Микаэль Хенафф
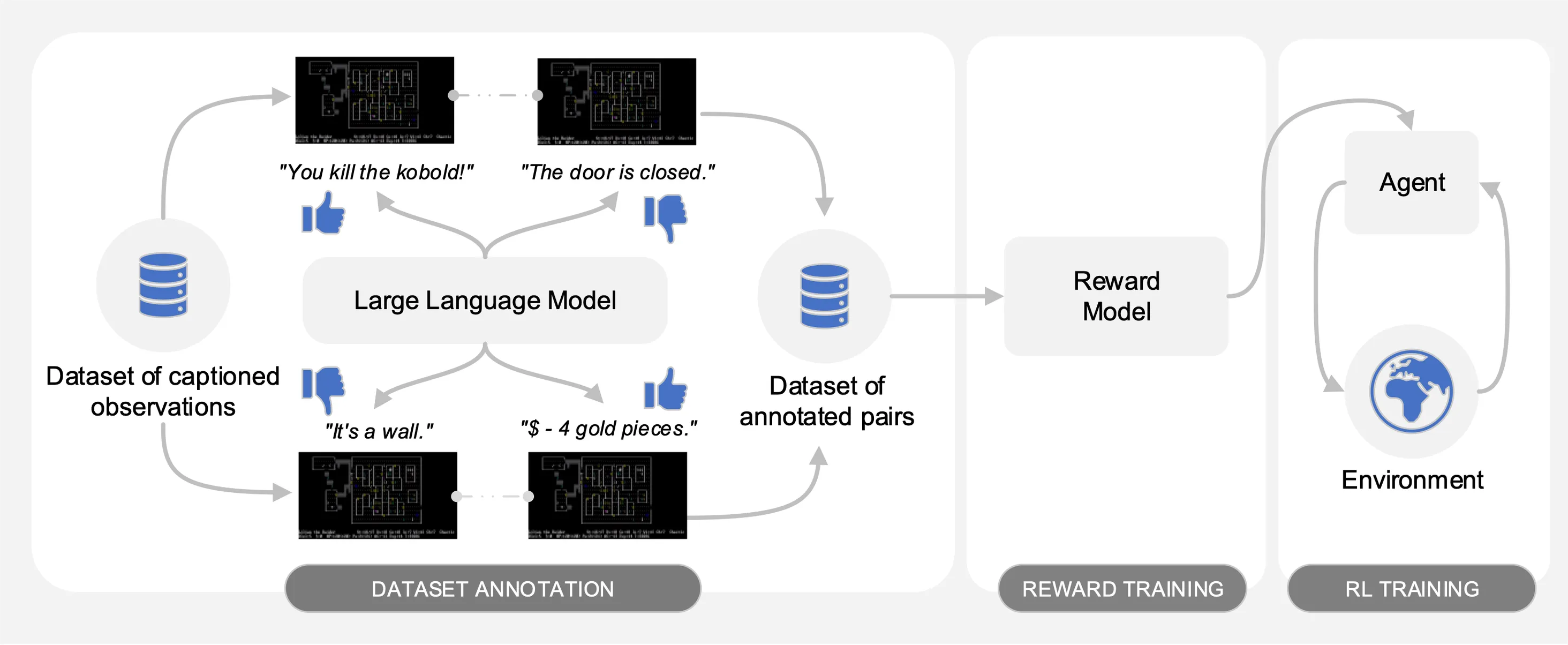
Motif выявляет предпочтения модели большого языка (LLM) для пар наблюдений с субтитрами из набора данных о взаимодействиях, собранных на NetHack. Он автоматически преобразует здравый смысл LLM в функцию вознаграждения, которая используется для обучения агентов обучению с подкреплением.
Для облегчения сравнения мы предоставляем обучающие кривые в файле Pickle motif_results.pkl , содержащем словарь с задачами в качестве ключей. Для каждой задачи мы предоставляем список временных шагов и средней доходности для Motif и базовых показателей для нескольких начальных значений.
Как показано на следующем рисунке, Motif состоит из трех этапов:
Мы подробно описываем каждый из этапов, предоставляя необходимые наборы данных, команды и необработанные результаты для воспроизведения экспериментов, описанных в статье.
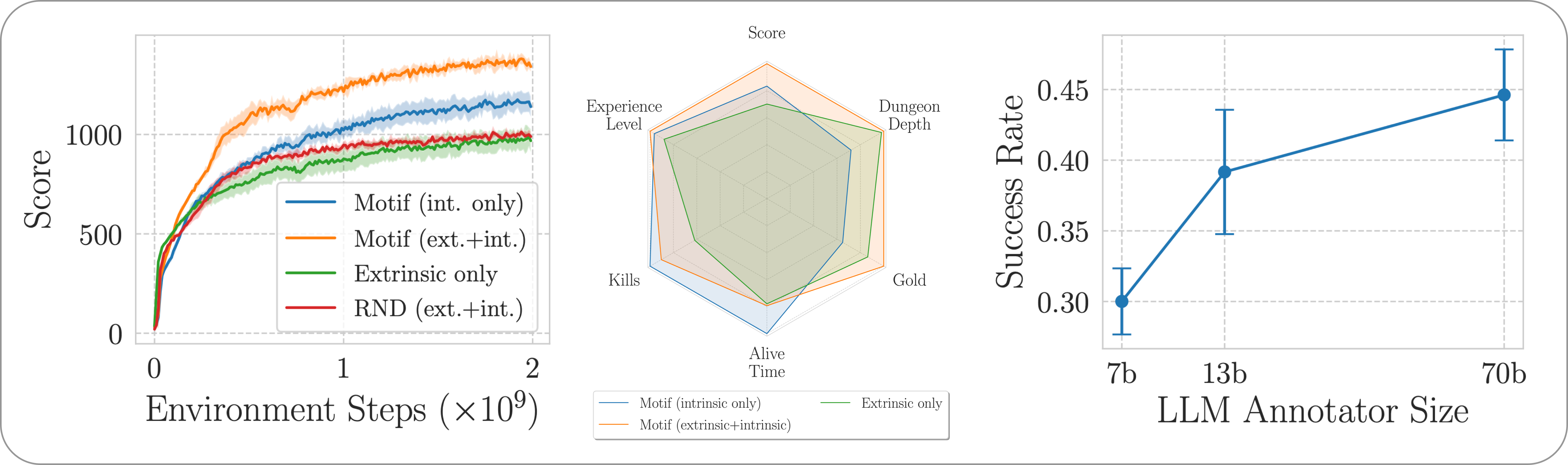
Мы оцениваем производительность Motif в сложной, открытой и процедурно генерируемой игре NetHack с помощью среды обучения NetHack. Мы исследуем, как Motif в основном генерирует интуитивно понятное поведение, ориентированное на человека, которым можно легко управлять посредством быстрых модификаций, а также его свойств масштабирования.

Чтобы установить необходимые зависимости для всего конвейера, просто запустите pip install -r requirements.txt .
На первом этапе мы используем набор данных пар наблюдений с подписями (т. е. сообщениями из игры), собранных агентами, обученными с помощью обучения с подкреплением, чтобы максимизировать оценку игры. Мы предоставляем набор данных в этом репозитории. Мы сохраняем различные части в каталоге motif_dataset_zipped , который можно разархивировать с помощью следующей команды.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
Предоставляемый нами набор данных содержит набор предпочтений, заданных моделями Llama 2, содержащихся в каталоге preference/ , с использованием различных подсказок, описанных в статье. Имена файлов .npy , содержащих аннотации, следуют шаблону llama{size}b_msg_{instruction}_{version} , где size — это размер LLM из набора {7,13,70} , instruction — это инструкция, введенная в подсказка, передаваемая LLM из набора {defaultgoal, zeroknowledge, combat, gold, stairs} , version — это версия шаблона подсказки, которая будет использоваться из набора {default, reworded} . Здесь мы приводим сводку доступных аннотаций:
| Аннотация | Вариант использования из статьи |
|---|---|
llama70b_msg_defaultgoal_default | Основные эксперименты |
llama70b_msg_combat_default | Ориентируясь на поведение «Убийцы монстров» |
llama70b_msg_gold_default | Ориентируясь на поведение «Коллекционера золота» |
llama70b_msg_stairs_default | Ориентируясь на поведение Descender |
llama7b_msg_defaultgoal_default | Масштабирующий эксперимент |
llama13b_msg_defaultgoal_default | Масштабирующий эксперимент |
llama70b_msg_zeroknowledge_default | Оперативный эксперимент с нулевым разглашением |
llama70b_msg_defaultgoal_reworded | Подскажите эксперимент по перефразированию |
Для создания аннотаций мы используем vLLM и чат-версию Llama 2. Если вы хотите создавать свои собственные аннотации с помощью Llama 2 или воспроизвести наш процесс аннотирования, убедитесь, что у вас есть возможность загрузить модель, следуя официальным инструкциям (это можно сделать получение доступа к весам моделей может занять несколько дней).
Сценарий аннотаций предполагает, что набор данных будет аннотирован по разным частям с использованием аргумента n-annotation-chunks . Это позволяет создать процесс, который можно распараллелить в зависимости от доступности ресурсов и который устойчив к перезапускам/вытеснению. Чтобы запустить один фрагмент (т. е. обработать весь набор данных) и добавить аннотацию с использованием шаблона приглашения по умолчанию и спецификации задачи, выполните следующую команду.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
Обратите внимание, что поведение по умолчанию возобновляет процесс аннотирования путем добавления аннотаций в файл, определяющий конфигурацию, если иное не указано с помощью флага --ignore-existing . Имя файла «.npy», созданного для аннотаций, также можно выбрать вручную с помощью флага --custom-annotator-string . Аннотировать можно с помощью --llm-size 7 и --llm-size 13 используя один графический процессор с 32 ГБ памяти. Вы можете аннотировать, используя --llm-size 70 с узлом с 8 графическими процессорами. Здесь мы приводим приблизительные оценки времени аннотирования для графических процессоров NVIDIA V100s 32G для набора данных из 100 тысяч пар, что должно быть в состоянии примерно воспроизвести большинство наших результатов (полученных с 500 тысячами пар).
| Модель | Ресурсы для аннотирования |
|---|---|
| Лама 2 7б | ~32 часа графического процессора |
| Лама 2 13б | ~40 часов графического процессора |
| Лама 2 70б | ~72 графических часа |
На втором этапе мы преобразуем предпочтения LLM в функцию вознаграждения посредством перекрестной энтропии. Чтобы запустить обучение с вознаграждением с гиперпараметрами по умолчанию, используйте следующую команду.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
Функция вознаграждения будет обучена с помощью аннотаций annotator , которые расположены в --dataset_dir . Полученная функция затем будет сохранена в train_dir в подпапке --experiment .
Наконец, мы обучаем агента полученным функциям вознаграждения посредством обучения с подкреплением. Чтобы обучить агента задаче NetHackScore-v1 с гиперпараметрами по умолчанию, используемыми для экспериментов по комбинированию внутренних и внешних вознаграждений, вы можете использовать следующую команду.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
Чтобы изменить задачу, просто измените аргумент --root_env . В следующей таблице явно указаны значения, необходимые для соответствия экспериментам, представленным в статье. Задача NetHackScore-v1 изучается со значением extrinsic_reward , равным 0.1 , тогда как все остальные задачи принимают значение 10.0 , чтобы стимулировать агента к достижению цели.
| Среда | root_env |
|---|---|
| счет | NetHackScore-v1 |
| лестница | NetHackStaircase-v1 |
| лестница (уровень 3) | NetHackStaircaseLvl3-v1 |
| лестница (уровень 4) | NetHackStaircaseLvl4-v1 |
| оракул | NetHackOracle-v1 |
| оракул-трезвый | NetHackOracleSober-v1 |
Кроме того, если вы хотите обучать агентов, используя только внутреннее вознаграждение, поступающее от LLM, но не вознаграждение из окружающей среды, просто установите --extrinsic_reward 0.0 . В экспериментах, ориентированных только на вознаграждение, мы завершаем эпизод только в том случае, если агент умирает, а не когда агент достигает цели. Эти измененные среды перечислены в следующей таблице.
| Среда | root_env |
|---|---|
| лестница (уровень 3) – только внутренняя | NetHackStaircaseLvl3Continual-v1 |
| лестница (уровень 4) – только внутренняя | NetHackStaircaseLvl4Continual-v1 |
Мы дополнительно предоставляем скрипт для визуализации ваших обученных RL-агентов. Это может дать важную информацию о его поведении, а также сгенерирует основные сообщения для каждого эпизода, что может помочь понять, для чего он пытается оптимизироваться. Вам просто нужно запустить следующую команду.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
Если вы опираетесь на нашу работу или считаете ее полезной, пожалуйста, цитируйте ее, используя следующий бибтекс.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Большая часть Motif лицензируется по лицензии CC-BY-NC, однако части проекта доступны по отдельным условиям лицензии: sample-factory лицензируется по лицензии MIT.


