
Унифицируйте данные на протяжении всего жизненного цикла машинного обучения с помощью Space — комплексного решения для хранения данных, которое беспрепятственно обрабатывает данные от приема до обучения.
Ключевые особенности:
space.core.schema.types.files ).space.TfFeatures — это встроенный тип поля, предоставляющий сериализаторы для вложенных диктовок массивов numpy на основе TFDS FeaturesDict.Установить:
pip install space-datasetsИли установите из кода:
cd python
pip install .[dev]См. документацию по настройке и производительности.
Создайте набор данных Space с двумя индексными полями ( id , image_name ) (храните в Parquet) и полем записи ( feature ) (храните в ArrayRecord).
В этом примере для поля записи используется простой binary тип. Space поддерживает тип space.TfFeatures , который интегрируется с сериализатором функций TFDS. Более подробную информацию см. в примере TFDS.
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" ) При желании вы можете использовать catalogs для управления наборами данных по именам, а не по местоположениям:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())Добавить, удалить некоторые данные. Каждая мутация генерирует новую версию данных, представленную возрастающим целочисленным идентификатором. Пользователи могут добавлять теги к идентификаторам версий в качестве псевдонимов.
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )Создайте новую ветку и внесите изменения в новую ветку:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
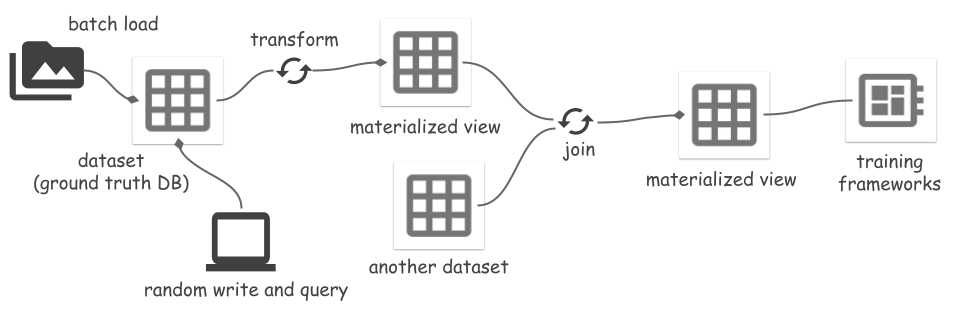
ds . set_current_branch ( "main" )Space поддерживает преобразование набора данных в представление и материализацию представления в файлы. Преобразования включают в себя:
Когда исходный набор данных изменяется, обновление материализованного представления постепенно синхронизирует изменения, что экономит затраты на вычисления и ввод-вывод. Более подробную информацию см. в примере «Сегментировать что угодно». Чтение или обновление представлений должно осуществляться с помощью Ray runner, поскольку они реализованы на основе преобразования Ray.
Материализованное представление mv можно использовать как представление mv.view или набор данных mv.dataset . Первый всегда считывает данные из файлов исходного набора данных и обрабатывает все данные «на лету». Последний напрямую считывает обработанные данные из файлов МВ, пропуская обработку данных.
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()Полный пример см. в примере «Сегментировать что угодно». Создание материализованного представления результата соединения пока не поддерживается.
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])Существует несколько способов интеграции хранилища Space с платформами машинного обучения. Space предоставляет источник данных с произвольным доступом для чтения данных в файлах ArrayRecord:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]Набор данных или представление также можно читать как набор данных Ray:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )Данные в файлах Parquet можно читать как набор данных HuggingFace:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})Список путей ко всем индексным (Parquet) файлам:
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_idПоказать статистическую информацию всех файлов ArrayRecord:
ds . storage . record_manifest () # Accept filter and snapshot_id «Космос» — новый проект, находящийся в активной разработке.
? Текущие задачи:
Это не официально поддерживаемый продукт Google.


