

MPIRE , сокращение от MultiProcessing Is Really Easy, представляет собой пакет Python для многопроцессорной обработки. MPIRE работает быстрее в большинстве сценариев, содержит больше функций и, как правило, более удобен для пользователя, чем пакет многопроцессорной обработки по умолчанию. Он сочетает в себе удобную карту, подобную функциям multiprocessing.Pool , с преимуществами использования общих объектов multiprocessing.Process с копированием при записи, а также простым в использовании состоянием работника, информацией о работниках, функциями инициализации и выхода работника, тайм-аутами и Функциональность индикатора выполнения.
Полная документация доступна по адресу https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork )rich виджеты и виджеты блокнота)daemonMPIRE протестирован на Linux, macOS и Windows. Для пользователей Windows и macOS есть несколько незначительных известных предостережений, которые описаны в главе «Устранение неполадок».
Через пип (PyPi):
pip install mpireMPIRE также доступен через conda-forge:
conda install -c conda-forge mpire Предположим, у вас есть трудоемкая функция, которая получает некоторый ввод и возвращает результаты. Подобные простые функции известны как проблемы с ошеломляющим параллельным параллелизмом, функции, которые практически не требуют усилий для превращения в параллельную задачу. Распараллелить простую функцию можно так же просто, как импортировать multiprocessing и использовать класс multiprocessing.Pool :
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE можно использовать почти как замену multiprocessing . Мы используем класс mpire.WorkerPool и вызываем одну из доступных функций map :
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) Различия в коде невелики: нет необходимости изучать совершенно новый синтаксис многопроцессорности, если вы привыкли к «ванильной» multiprocessing . Однако дополнительная доступная функциональность — это то, что отличает MPIRE.
Предположим, мы хотим узнать статус текущей задачи: сколько задач выполнено, через какое время работа будет готова? Это так же просто, как установить для параметра progress_bar значение True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )И он выведет красиво отформатированный индикатор выполнения tqdm.
MPIRE также предлагает панель управления, для которой вам необходимо установить дополнительные зависимости. См. Панель управления для получения дополнительной информации.
Примечание. Общие объекты копирования при записи доступны только для метода запуска fork . Для threading объекты доступны как есть. Для других методов запуска общие объекты копируются один раз для каждого работника, что все же может быть лучше, чем один раз для каждой задачи.
Если у вас есть один или несколько объектов, которые вы хотите разделить между всеми работниками, вы можете использовать опцию копирования при записи shared_objects MPIRE. MPIRE будет передавать эти объекты только один раз для каждого исполнителя без копирования/сериализации. Только когда вы измените объект в рабочей функции, он начнет копировать его для этого рабочего.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )Дополнительные сведения см. в разделе «shared_objects».
Воркеров можно инициализировать с помощью функции worker_init . Вместе с worker_state вы можете загрузить модель, настроить соединение с базой данных и т. д.:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) Аналогичным образом вы можете использовать функцию worker_exit , чтобы позволить MPIRE вызывать функцию всякий раз, когда рабочий процесс завершается. Вы даже можете позволить этой функции выхода возвращать результаты, которые можно будет получить позже. Дополнительную информацию смотрите в разделах worker_init и worker_exit.
Если ваша многопроцессорная установка не работает так, как вы хотите, и вы понятия не имеете, что является причиной этого, существует функция анализа рабочих процессов. Это даст вам представление о вашей настройке, но не будет профилировать выполняемую вами функцию (для этого есть другие библиотеки). Вместо этого он профилирует время запуска работника, время ожидания и рабочее время. Когда предоставляются рабочие функции инициализации и выхода, они также будут рассчитываться по времени.
Возможно, вы отправляете много данных через очередь задач, что приводит к увеличению времени ожидания. В любом случае вы можете включить и получить информацию, используя флаг enable_insights и функцию mpire.WorkerPool.get_insights соответственно:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()Более подробный пример и ожидаемый результат см. в разделе «Информация о работниках».
Таймауты могут быть установлены отдельно для функций target, worker_init и worker_exit . Когда таймаут установлен и достигнут, выдается TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) При использовании threading в качестве метода запуска MPIRE не сможет прерывать определенные функции, такие как time.sleep .
Дополнительные сведения см. в разделе таймауты.
MPIRE тестировался по трем различным критериям: числовые вычисления, вычисления с отслеживанием состояния и дорогостоящая инициализация. Более подробную информацию об этих тестах можно найти в этом сообщении блога. Весь код для этих тестов можно найти в этом проекте.
Короче говоря, основные причины, по которым MPIRE быстрее:
fork , мы можем использовать общие объекты с возможностью копирования при записи, что уменьшает необходимость копирования объектов, которые необходимо использовать совместно с дочерними процессами.На следующем графике показаны средние нормализованные результаты всех трех тестов. Результаты отдельных тестов можно найти в сообщении в блоге. Тесты проводились на машине Linux с 20 ядрами, отключенной гиперпоточностью и 200 ГБ оперативной памяти. Для каждой задачи эксперименты проводились с разным количеством процессов/работников, а результаты усреднялись по 5 запускам.
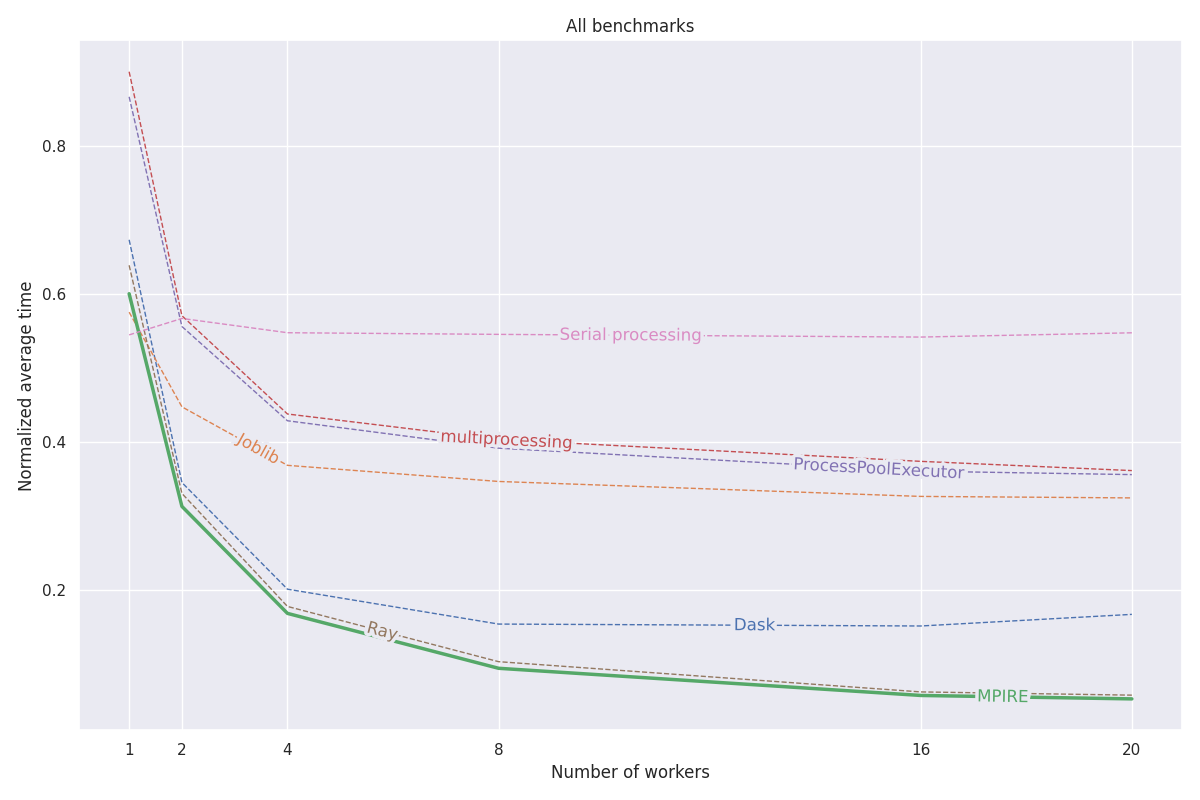
См. полную документацию по адресу https://sybrenjansen.github.io/mpire/ для получения информации обо всех других функциях MPIRE.
Если вы хотите собрать документацию самостоятельно, установите зависимости документации, выполнив:
pip install mpire[docs]или
pip install .[docs]Затем документацию можно собрать, используя Python <= 3.9 и выполнив:
python setup.py build_docs Документацию также можно собрать непосредственно из папки docs . В этом случае MPIRE должен быть установлен и доступен в вашей текущей рабочей среде. Затем выполните:
make html в папке docs .


