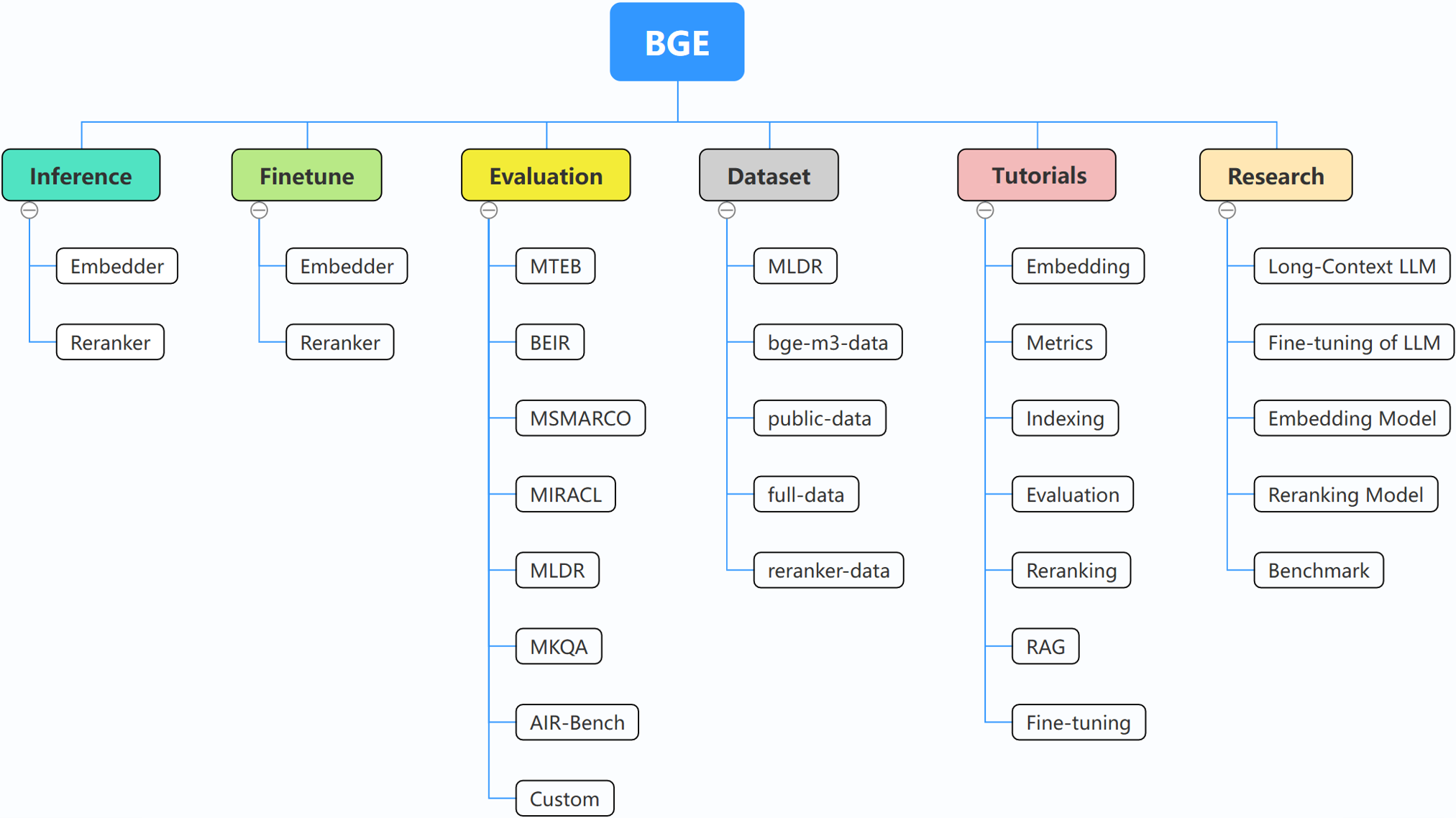
FlagEmbedding
1.3.2


Новости | Установка | Быстрый старт | Сообщество | Проекты | Список моделей | Участник | Цитирование | Лицензия
английский | 中文
BGE (BAAI General Embedding) специализируется на LLM с возможностью поиска и в настоящее время включает следующие проекты:
29.10.2024: ? Мы создали группу WeChat для BGE. Отсканируйте QR-код, чтобы присоединиться к групповому чату! Чтобы получать информацию о наших обновлениях и новых выпусках из первых рук, а также иметь какие-либо вопросы или идеи, присоединяйтесь к нам прямо сейчас!

22.10.2024: Мы выпускаем еще одну интересную модель: OmniGen, которая представляет собой единую модель генерации изображений, поддерживающую различные задачи. OmniGen может выполнять сложные задачи по созданию изображений без необходимости использования дополнительных плагинов, таких как ControlNet, IP-адаптер, или вспомогательных моделей, таких как распознавание позы и распознавание лиц.
10.09.2024: Представляем MemoRAG , шаг вперед к RAG 2.0 в дополнение к обнаружению знаний на основе памяти (репозиторий: https://github.com/qhjqhj00/MemoRAG, документ: https://arxiv.org/pdf/ 2409.05591в1)
02.09.2024: Начало поддержки руководств. Содержимое будет активно обновляться и расширяться, следите за обновлениями!
26.07.2024: Выпуск новой модели внедрения bge-en-icl, модели внедрения, включающей возможности контекстного обучения, которая, предоставляя соответствующие задачам примеры запроса-ответа, может кодировать семантически более сложные запросы, еще больше улучшая семантику. репрезентативная способность вложений.
26.07.2024: Выпуск новой модели внедрения bge-multilingual-gemma2, многоязычной модели внедрения на основе gemma-2-9b, которая поддерживает несколько языков и разнообразные последующие задачи, достигая нового SOTA в многоязычных тестах (MIRACL, MTEB-fr). и MTEB-pl).
26.07.2024: Выпуск нового упрощенного средства изменения ранжирования bge-reranker-v2.5-gemma2-lightweight, облегченного средства изменения ранжирования на основе gemma-2-9b, которое поддерживает сжатие токенов и облегченные послойные операции, но по-прежнему может обеспечивать хорошую производительность при сохранении значительное количество ресурсов.
BAAI/bge-reranker-base и BAAI/bge-reranker-large , которые являются более мощными, чем модель внедрения. Мы рекомендуем использовать или настраивать их для повторного ранжирования документов из топ-k, возвращаемых в результате внедрения моделей.bge-*-v1.5 чтобы облегчить проблему распределения сходства и улучшить возможность ее поиска без инструкций.bge-large-* (сокращение от BAAI General Embedding), занявших 1-е место в тестах MTEB и C-MTEB! ? ?Если вы не хотите точно настраивать модели, вы можете установить пакет без зависимости тонкой настройки:
pip install -U FlagEmbedding
Если вы хотите точно настроить модели, вы можете установить пакет с зависимостью точной настройки:
pip install -U FlagEmbedding[finetune]
Клонируйте репозиторий и установите
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
Для разработки в редактируемом режиме:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
Сначала загрузите одну из моделей внедрения BGE:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
Затем добавьте в модель несколько предложений и получите их вложения:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
Получив вложения, мы можем вычислить сходство по внутреннему произведению:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
Для получения более подробной информации вы можете обратиться к выводам для внедрения, выводам по изменению ранжирования, точной настройке устройства для внедрения, настройке повторного ранжирования, оценке.
Если вы не знакомы с какими-либо связанными понятиями, пожалуйста, ознакомьтесь с руководством. Если его там нет, сообщите нам.
Чтобы узнать больше об интересных темах, связанных с BGE, ознакомьтесь с исследованиями.
Мы активно поддерживаем сообщество BGE и FlagEmbedding. Дайте нам знать, если у вас есть какие-либо предложения или идеи!
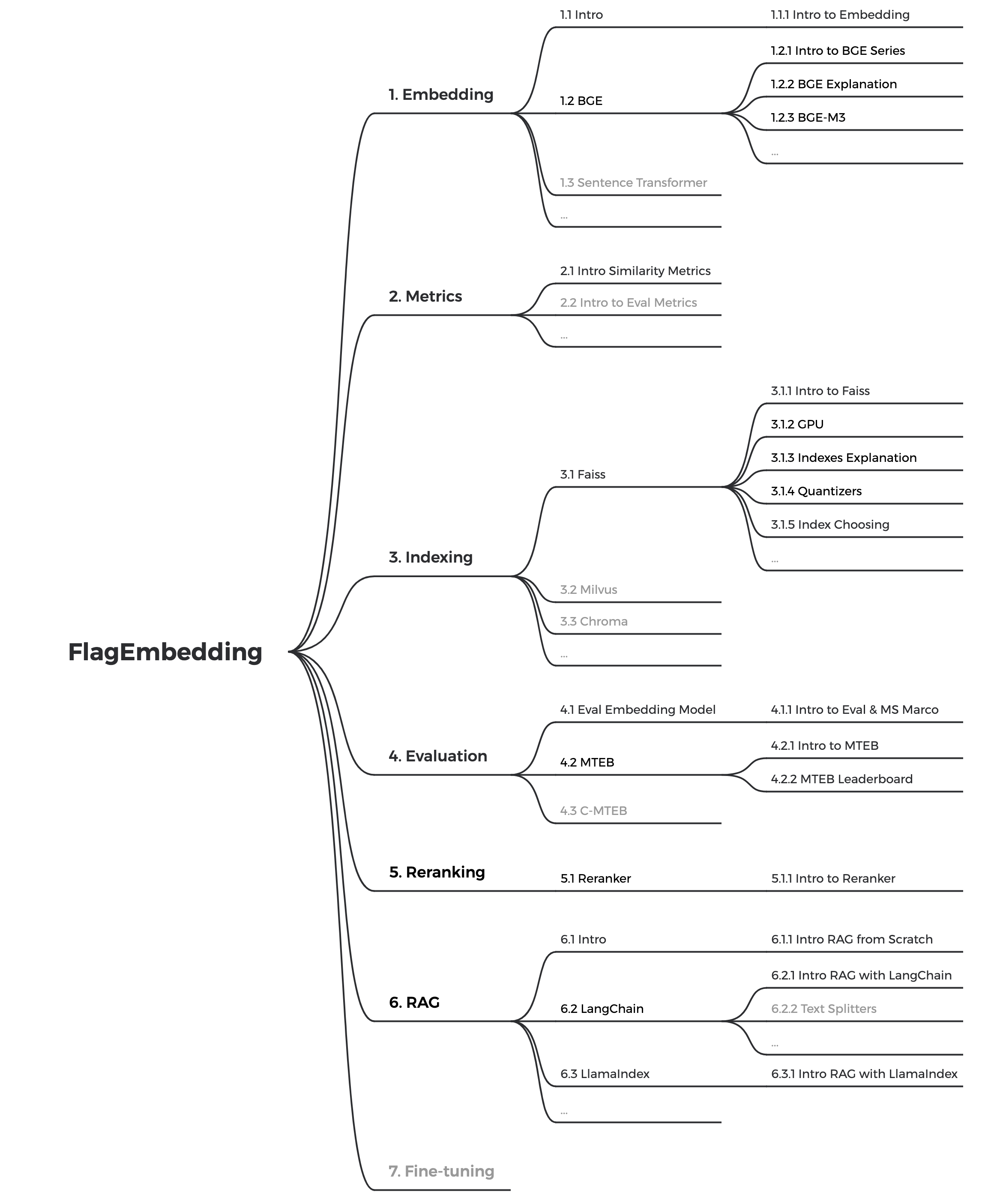
В настоящее время мы обновляем руководства и стремимся создать всеобъемлющее и подробное руководство для начинающих по поиску текста и RAG. Следите за обновлениями!
В ближайшие недели будет выпущен следующий контент:
bge — это сокращение от BAAI general embedding .
| Модель | Язык | Описание | инструкция запроса для поиска |
|---|---|---|---|
| BAAI/bge-en-icl | Английский | Модель внедрения на основе LLM с возможностями контекстного обучения, которая может полностью использовать потенциал модели на основе нескольких примеров. | Свободно предоставляйте инструкции и примеры, основанные на заданной задаче. |
| BAAI/bge-мультиязычный-gemma2 | Многоязычный | Многоязычная модель внедрения на основе LLM, обученная на широком спектре языков и задач. | Дайте инструкции, основанные на заданной задаче. |
| БААИ/бге-м3 | Многоязычный | Многофункциональность (плотный поиск, разреженный поиск, многовекторность (кольбер)), многоязычность и многодетализация (8192 токена) | |
| LM-Коктейль | Английский | точно настроенные модели (Llama и BGE), которые можно использовать для воспроизведения результатов LM-коктейля. | |
| BAAI/LLM-встраиватель | Английский | унифицированная модель внедрения для поддержки разнообразных потребностей в расширении поиска для LLM | См. README |
| BAAI/bge-reranker-v2-m3 | Многоязычный | легкая модель кросс-кодировщика, обладающая мощными многоязычными возможностями, проста в развертывании и обеспечивает быстрый вывод. | |
| BAAI/bge-reranker-v2-gemma | Многоязычный | модель перекрестного кодирования, которая подходит для многоязычных контекстов, хорошо работает как при владении английским языком, так и при многоязычных возможностях. | |
| BAAI/bge-reranker-v2-minicpm-послойно | Многоязычный | модель кросс-кодирования, которая подходит для многоязычных контекстов, хорошо работает как при владении английским, так и в китайском языках, дает свободу выбора слоев для вывода, способствуя ускорению вывода. | |
| BAAI/bge-reranker-v2.5-gemma2-легкий вес | Многоязычный | модель кросс-кодирования, подходящая для многоязычных контекстов, хорошо работает как при владении английским, так и в китайском языках, дает свободу выбора слоев, степени сжатия и слоев сжатия для вывода, способствуя ускорению вывода. | |
| BAAI/bge-reranker-large | китайский и английский | модель кросс-кодировщика, которая более точна, но менее эффективна | |
| BAAI/bge-reranker-base | китайский и английский | модель кросс-кодировщика, которая более точна, но менее эффективна | |
| BAAI/bge-large-en-v1.5 | Английский | версия 1.5 с более разумным распределением сходства | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | Английский | версия 1.5 с более разумным распределением сходства | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | Английский | версия 1.5 с более разумным распределением сходства | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | китайский | версия 1.5 с более разумным распределением сходства | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | китайский | версия 1.5 с более разумным распределением сходства | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | китайский | версия 1.5 с более разумным распределением сходства | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | Английский | Модель внедрения, которая отображает текст в вектор | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | Английский | модель базового масштаба, но с возможностями, аналогичными bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | Английский | мелкосерийная модель, но с конкурентоспособными характеристиками | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | китайский | Модель внедрения, которая отображает текст в вектор | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | китайский | модель базового масштаба, но с возможностями, аналогичными bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | китайский | мелкосерийная модель, но с конкурентоспособными характеристиками | 为这个句子生成表示以用于检索相关文章: |
Благодарим всех наших участников за их усилия и тепло приветствуем новых участников!
Если вы найдете этот репозиторий полезным, поставьте звездочку и цитируйте его.
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding лицензируется по лицензии MIT.


