Система управления метрополитеном
Весенние проекты SUSTech 2024, курс CS307 - Principles of Database System под руководством Юсиня М.А.
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
Первая часть проекта в основном посвящена разработке схемы базы данных, которая удовлетворяет принципам реляционных баз данных на основе предоставленных данных. После завершения этапа проектирования мы написали сценарии для импорта этих больших наборов данных. Чтобы обеспечить точность импортированных данных, нам пришлось выполнить несколько операторов запроса и проверить результаты запроса в день защиты. Кроме того, мы также провели несколько экспериментов с данными, чтобы получить замечательные идеи, как будет показано позже.
[Читать подробные требования]
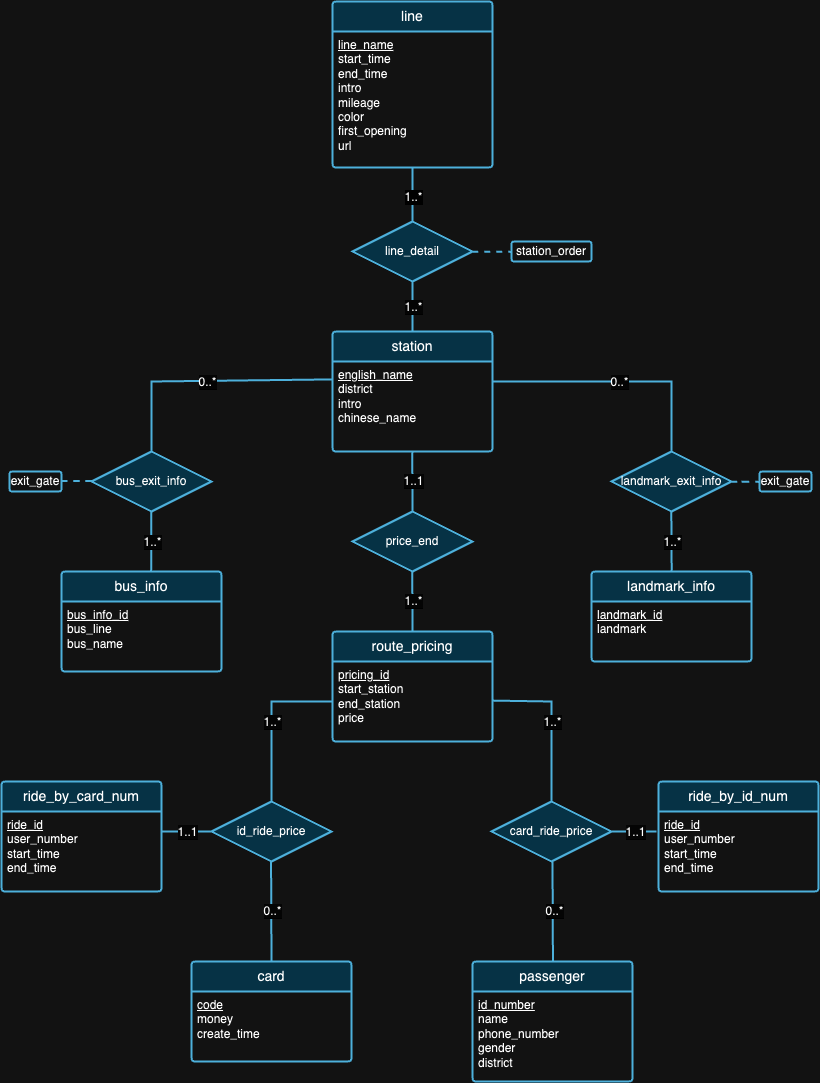
Мы считаем, что ни одна база данных не идеальна. На самом деле, в конструкции, предложенной нами на схеме ER выше, есть недостатки. Мы надеемся, что после изучения наборов данных и предыстории каждого набора данных вы сможете попытаться обнаружить недостатки дизайна самостоятельно! :)
Примечание . Для интерпретации рисунка
| ИДЕНТИФИКАТОР | ОС | Чип | Память | SSD | Инструменты |
|---|---|---|---|---|---|
| 1 | macOS Сонома 14.4.1 | Яблоко М3 Про | 18 ГБ | 1 ТБ | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), Datagrip 2024.1 |
| 2 | Windows 11 Домашняя 23ч2 | Intel(R) Core(TM) 12-го поколения i9-12900H | 32 ГБ | 1 ТБ | IDEA 2024.1 (CE), Datagrip 2024.1 |
| 3 | Убунту 22.04.4 (ВМ) | Яблоко М1 Про | 16 ГБ | 512 ГБ | IDEA 2024.1 (CE), Datagrip 2024.1 |
Experiment 1: Different Import Methods Метод 1 (исходный сценарий). Этот метод использует библиотеку java.sql . Сначала мы установили соединение с нашим сервером PostgreSQL. Затем мы читаем все данные из файлов JSON. Затем мы перебрали все данные и создали PreparedStatement для каждого оператора вставки. Наконец, мы вызвали метод executeUpdate() для индивидуального выполнения каждого оператора.
Метод 2 (оптимизированный скрипт). Этот метод также использует библиотеку java.sql и использует тот же алгоритм чтения данных, что и метод 1. Разница в том, что теперь мы используем метод executeBatch() . Таким образом, мы перебрали все данные, создали каждый оператор вставки с помощью PreparedStatement и добавили каждый PreparedStatement в пакет для пакетного выполнения.
Метод 3 (запуск файла .sql): мы использовали программу Java для генерации операторов вставки SQL и записывали их в файл .sql , используя тот же алгоритм чтения данных, упомянутый выше. Затем запускаем файл в DataGrip.
Поскольку мы используем один и тот же алгоритм чтения данных во всех трех методах, для наших последующих тестов мы будем использовать среднее время выполнения. Первоначально мы собрали три разных времени выполнения — 504 мс, 546 мс и 552 мс — и рассчитали среднее время выполнения 534 мс.
| Тестовая среда | Метод | Среднее время чтения (мс) | Время записи (мс) | Общее время (мс) | Пропускная способность (операторов/с) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636,91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
В таблице 2 показаны различные показатели производительности для разных методов: метод 2 демонстрирует самую высокую пропускную способность, а метод 1 — самое медленное общее время. Это делает метод 2 стандартным методом тестирования в предстоящих экспериментах.
Experiment 2: Data Import with Different Data VolumesУправление данными различных объемов и их импорт — важнейший аспект обеспечения производительности, масштабируемости и надежности системы баз данных.
Перед процессом импорта мы заметили, что данные «поездки» были заметно больше по объему по сравнению с другими. Основываясь на этой идее, мы решили протестировать импорт данных разных объемов только в ride.json . Поскольку вес данных не является постоянным, импорт меньшего объема для других таблиц может привести к серьезной проблеме из-за связи между таблицами.
Первоначально мы начали с импорта полных данных (100 % объема) для всех остальных таблиц, кроме таблиц rides_by_id_num и rides_by_card_num , чтобы обеспечить согласованность нашего дизайна. Чтобы эффективно справиться с этим, мы приняли стратегию поэтапного импорта данных о ride , начиная с 20% подмножества данных, что соответствует 20 000 записей. Этот начальный этап позволил нам оценить влияние на производительность системы и внести необходимые корректировки в процесс импорта без ущерба для стабильности базы данных. После успешной проверки и настройки производительности мы приступили к импорту 50 % данных и, наконец, к оставшейся части, чтобы завершить импорт 100 % данных. Обратите внимание, что для всех импортов мы использовали метод 2, поскольку он самый быстрый.
| Тестовая среда | Метод | Объем | Время чтения (мс) | Время записи (мс) | Общее время (мс) | Количество операторов | Пропускная способность (операторов/с) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859 г. | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263,95 |
Как видно из таблицы 3, по мере увеличения объема данных (от 20% до 50% и до 100%) время чтения и записи имеет тенденцию к увеличению, что приводит к увеличению общего времени выполнения операций. Однако эти цифры не несут никакого глубокого смысла, поскольку объемы импорта у нас были разные. Если вместо этого мы посмотрим на количество пропускных операций, то пропускная способность (операторов/с) постепенно снижается с увеличением объема данных, что указывает на то, что система становится менее эффективной при обработке операторов по мере увеличения рабочей нагрузки.
Experiment 3: Data Import on Different Operating SystemsПри тестировании процесса импорта данных на разных ОС мы использовали самый быстрый метод импорта — метод 2 со 100% объемом импорта.
Обратите внимание, что при запуске сценария импорта Java в Linux через виртуальную машину важно учитывать несправедливый недостаток производительности и распределения ресурсов, поскольку виртуализация может привести к увеличению накладных расходов и повлиять на эффективность системы.
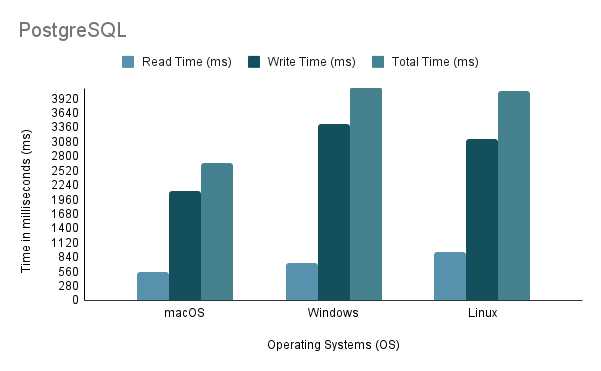
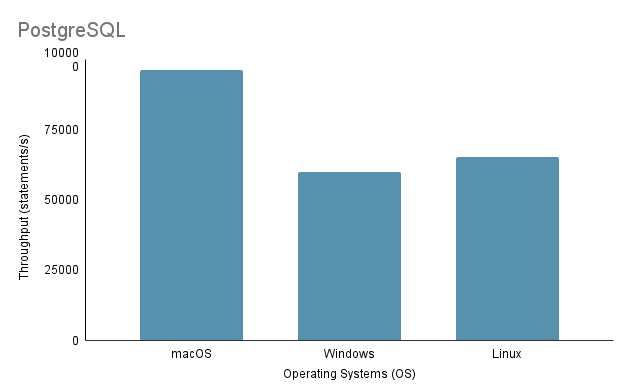
На основе приведенного выше анализа становится ясно, что среда 1 (macOS) демонстрирует наилучшую производительность с самым коротким общим временем 2648 мс и самой высокой пропускной способностью 97 632,92 операторов/с. Напротив, среда 2 (Windows) является самой медленной с общим временем 4117 мс и самой низкой пропускной способностью — 60 669,02 операторов/с. Стоит отметить, что Linux Ubuntu, хотя и работал в качестве виртуальной машины, по-прежнему превосходил по производительности «голую» Windows.
Experiment 4: Data Import with Various Programming LanguagesВ этом эксперименте мы использовали упомянутый выше метод 2 для кода Java, поскольку он самый быстрый. Тем временем для Python мы написали метод импорта, который использовал Psycopg2 для связи с сервером базы данных PostgreSQL.
| Тестовая среда | Язык программирования | Время чтения (мс) | Время записи (мс) | Общее время (мс) | Пропускная способность (операторов/с) |
|---|---|---|---|---|---|
| 1 | Ява | 534 | 2114 | 2648 | 96263,95 |
| 1 | Питон | 390 | 7237 | 7627 | 28119.66 |
Данные таблицы 4 показывают, что Java превзошла Python как по скорости, так и по пропускной способности, что указывает на его превосходную эффективность при операциях чтения и записи.
Experiment 5: Data Import on Different DatabasesМы разработали три разных метода импорта как для PostgreSQL, так и для MySQL, но провели эксперимент только со методом 2, поскольку это выбор разработчика для импорта данных. И PostgreSQL, и MySQL имеют схожий дизайн реализации базы данных (с точки зрения DDL) и схожий дизайн кода импорта.
| Тестовая среда | Метод | База данных | Время чтения (мс) | Время записи (мс) | Общее время (мс) | Пропускная способность (операторов/с) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263,95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809,22 |
Несмотря на то, что обе базы данных основаны на SQL, PostgreSQL примерно в 16 раз быстрее, когда дело касается времени записи. Это может быть связано с различиями в архитектуре ядра базы данных и реализации драйвера ( postgresql-42.2.5.jar для PostgreSQL и mysql-connector-j-8.3.0.jar для MySQL).
Вторая часть проекта сосредоточена на обеспечении базовых функций доступа к системе баз данных путем создания серверной библиотеки, которая предоставляет набор интерфейсов прикладного программирования (API). Обратите внимание, что необходимо импортировать дополнительный набор данных, поэтому требуется обновленная реализация базы данных (можно найти в ./Project2/DataImport ).
[Читать подробные требования]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) с помощью Maven (рекомендуется IntelliJ IDEA IDE).

