chrono_lens
v1.1.1
Это общедоступный репозиторий проекта анализа камер дорожного движения, опубликованного в блоге кампуса Управления национальной статистики по науке о данных как часть индикаторов быстрого реагирования на коронавирус ONS (например, «Действие камер дорожного движения» — 10 сентября 2020 г.), а также базовой методологии. В проекте использовалась Google Compute Platform (GCP) для создания масштабируемого решения, но базовая методология не зависит от платформы; этот репозиторий содержит нашу реализацию, ориентированную на GCP.
Ниже представлен пример результатов, полученных для Индикатора быстрого реагирования на коронавирус.
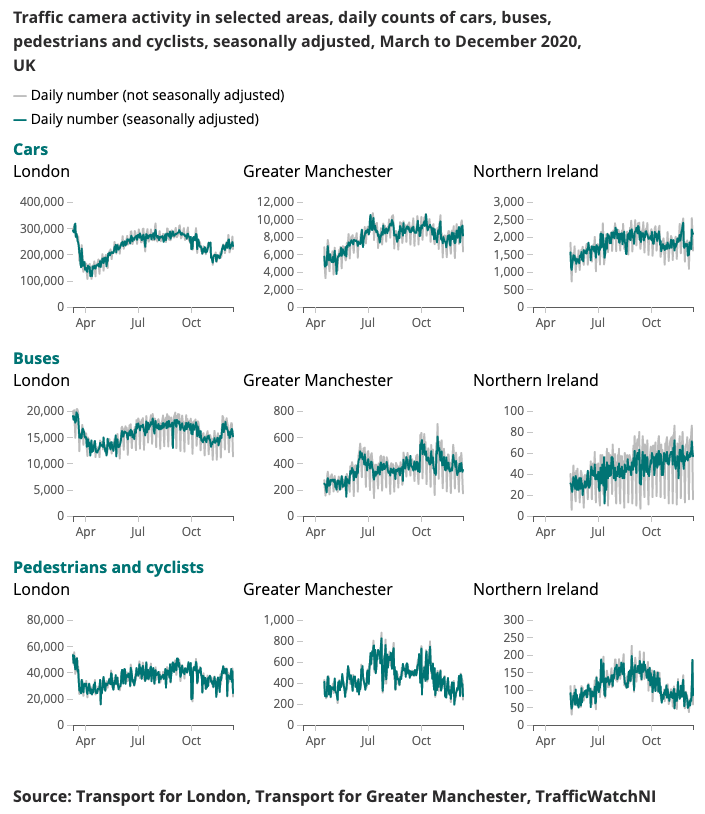
Понимание меняющихся моделей мобильности и поведения в режиме реального времени было основным направлением реакции правительства на коронавирус (COVID-19). Кампус науки о данных изучает альтернативные источники данных, которые могут дать представление о том, как оценить уровни социального дистанцирования и отслеживать подъем общества и экономики по мере ослабления условий изоляции.
Дорожные камеры являются широкодоступным и общедоступным источником данных, позволяющим транспортным специалистам и общественности оценивать транспортный поток в различных частях страны через Интернет. Изображения, создаваемые камерами дорожного движения, общедоступны, имеют низкое разрешение и не позволяют идентифицировать людей или транспортные средства индивидуально. Они отличаются от систем видеонаблюдения, используемых в целях общественной безопасности и правоохранительных органов для автоматического распознавания номерных знаков (ANPR) или для мониторинга скорости движения.
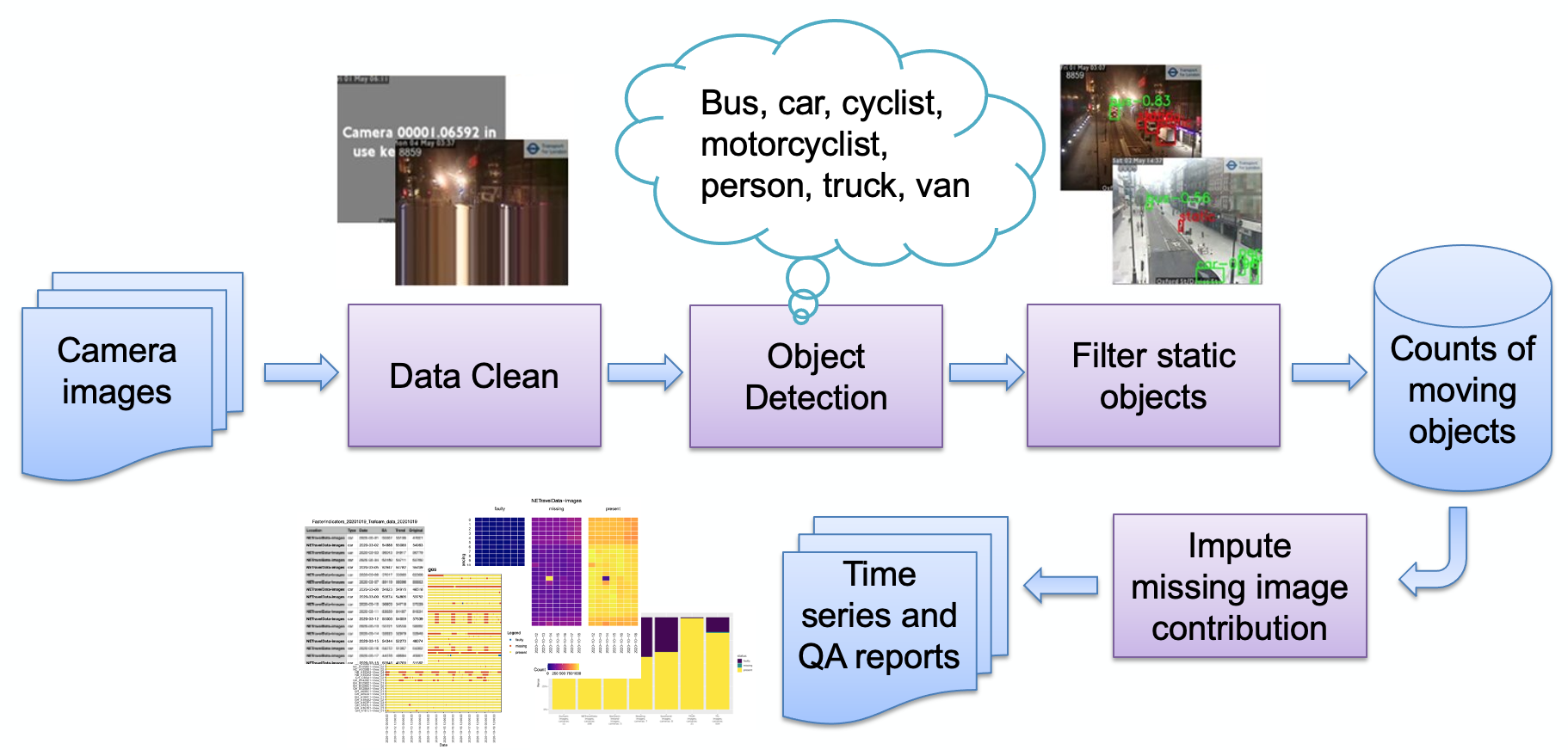
Основные этапы конвейера, как показано на изображении:
Прием изображения
Неправильное обнаружение изображения
Обнаружение объектов
Обнаружение статических объектов
Хранение результатов подсчета
Затем данные могут быть дополнительно обработаны (сезонная корректировка, вменение пропущенных значений) и преобразованы в отчеты по мере необходимости. Кратко рассмотрим основные этапы трубопровода.
Набор источников камер (изображения JPEG, размещенные в Интернете) выбирается пользователем и предоставляется пользователю в виде списка URL-адресов. Приведен пример кода для получения общедоступных изображений из Transport for London, а также специальный код для получения данных о дорожном движении на северо-востоке непосредственно из городской обсерватории Университета Ньюкасла.
Камеры могут быть недоступны по разным причинам (сбой системы, отключение сигнала местным оператором и т. д.), что может привести к тому, что модель будет генерировать ложное количество объектов (например, небольшой объект может выглядеть как далекий автобус). Пример такого изображения: 
До сих пор все эти изображения следовали шаблону очень синтетического изображения, состоящего из плоского цвета фона и наложенного текста (по сравнению с изображением естественной сцены). В настоящее время эти изображения обнаруживаются путем уменьшения глубины цвета (склеивания похожих цветов) и последующего просмотра самой высокой части изображения, занятой одним цветом. Как только оно превышает пороговое значение, мы определяем, что изображение является синтетическим, и отмечаем его как ошибочное. Другие неисправности могут возникнуть из-за кодирования, например: 
Здесь подача камеры остановилась и повторился последний «живой» ряд; мы обнаруживаем это, проверяя, соответствует ли нижняя строка изображения строке выше (в пределах порогового значения). Если это так, то следующая строка выше проверяется на совпадение и так далее, пока строки не перестанут совпадать или пока не закончатся строки. Если количество совпадающих строк превышает пороговое значение, то изображение вряд ли сгенерирует полезные данные и, следовательно, будет помечено как ошибочное.
Обратите внимание, что разные поставщики изображений используют разные способы показать, что камера недоступна; Наша методика обнаружения основана на использовании небольшого количества цветов, т.е. на чисто синтетическом изображении. Если используется более естественное изображение, наша техника может не сработать. Альтернативой является создание «библиотеки» неудачных изображений и поиск сходства, что может лучше работать с более естественными изображениями.
Процесс обнаружения объектов идентифицирует как статические, так и движущиеся объекты с использованием предварительно обученного Faster-RCNN, предоставленного Городской обсерваторией Университета Ньюкасла. Модель была обучена на 10 000 изображениях дорожных камер из северо-восточной Англии и дополнительно проверена кампусом обработки данных ONS, чтобы подтвердить, что модель можно использовать с изображениями с камер из других районов Великобритании. Он обнаруживает следующие типы объектов: автомобиль, фургон, грузовик, автобус, пешеход, велосипедист, мотоциклист.
Поскольку мы стремимся обнаруживать активность, важно отфильтровывать статические объекты, используя временную информацию. Изображения отбираются с 10-минутными интервалами, поэтому традиционные методы обнаружения фона в видео, такие как смесь гауссиан, не подходят.
Любые пешеходы и транспортные средства, классифицированные во время обнаружения объектов, будут установлены как статичные и исключены из окончательного подсчета, если они также появятся на заднем плане. На изображении ниже показан пример результатов статической маски, где припаркованные автомобили на изображении (а) идентифицируются как статичные и удаляются. Дополнительным преимуществом является то, что статическая маска может помочь устранить ложные тревоги. Например, на изображении (б) мусорное ведро ошибочно идентифицируется как пешеход при обнаружении объекта, но отфильтровывается как статический фон.

Результаты просто сохраняются в виде таблицы, схемы записи идентификатора камеры, даты, времени, связанных счетчиков для каждого типа объекта (автомобиль, фургон, пешеход и т. д.), если изображение ошибочно или изображение отсутствует.
Изначально система проектировалась как облачная, чтобы обеспечить масштабируемость; однако это создает барьер для входа — вам необходимо иметь учетную запись у облачного провайдера, знать, как защитить инфраструктуру и т. д. Имея это в виду, мы также перенесли код для работы на автономной машине. (или «локальный хост»), чтобы заинтересованный пользователь мог просто запустить систему на своем ноутбуке. Обе реализации теперь описаны ниже.
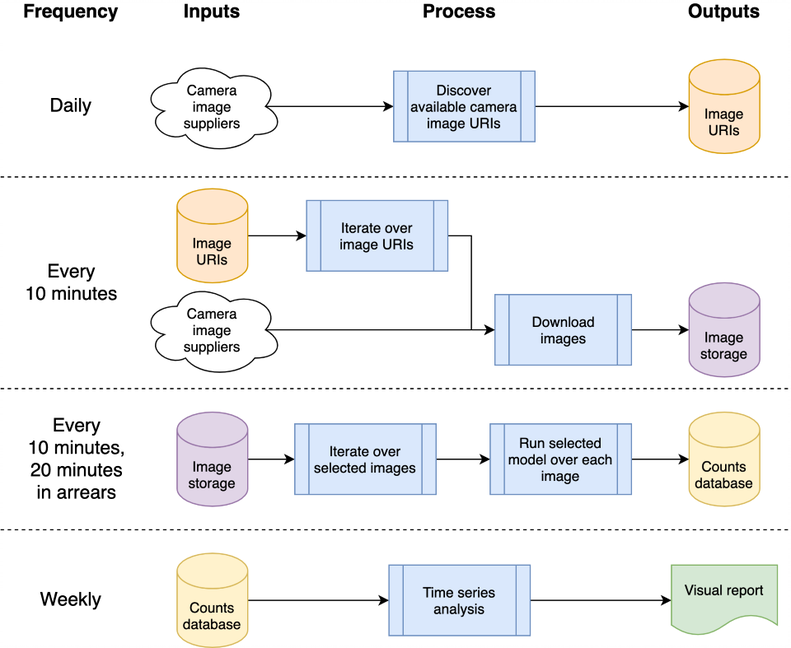
Эту архитектуру можно сопоставить с одной машиной или облачной системой; мы решили использовать Google Compute Platform (GCP), но другие платформы, такие как Amazon Web Services (AWS) или Microsoft Azure, будут предоставлять относительно эквивалентные услуги.
Система размещается в виде «облачных функций», которые представляют собой автономный код без сохранения состояния, который можно вызывать повторно, не вызывая повреждений, что является ключевым моментом для повышения надежности функций. Ежедневные и «каждые 10 минут» пакеты обработки организуются с помощью планировщика GCP для запуска темы GCP Pub/Sub в соответствии с желаемым расписанием. Облачные функции GCP регистрируются для темы и запускаются при каждом запуске темы.
Обработка изображений для обнаружения транспортных средств и пешеходов приводит к записи количества объектов в базу данных для последующего анализа в виде временного ряда. База данных используется для обмена данными между сбором данных и анализом временных рядов, уменьшая связанность. Мы используем BigQuery в GCP в качестве нашей базы данных, учитывая его широкую поддержку в других продуктах GCP, таких как Data Studio для визуализации данных; реализация локального хоста сохраняет ежедневные CSV-файлы для сравнения, чтобы устранить любую зависимость от конкретной базы данных или другой инфраструктуры.
Исходный код, связанный с GCP, хранится в cloud папке; при этом изображения загружаются, обрабатываются для подсчета объектов, сохраняются в базе данных и (еженедельно) производят анализ временных рядов. Вся документация и исходный код хранятся в cloud папке; обратитесь к Cloud README.md для обзора архитектуры и того, как установить свой собственный экземпляр с помощью наших скриптов в пространство вашего проекта GCP. Проект можно интегрировать в GitHub, что обеспечивает автоматическое развертывание и автоматическое выполнение тестов из коммитов в локальный проект GitHub; это также описано в файле Cloud README.md. Код поддержки облака также хранится в модуле chrono_lens.gcloud , что позволяет сценариям командной строки поддерживать GCP вместе с кодом функции облака в cloud папке.
Автономный код для одной машины («localhost») содержится в модуле chrono_lens.localhost . Этот процесс повторяет тот же процесс, что и вариант GCP, хотя и использует один компьютер, и каждый файл Python в chrono_lens.localhost сопоставляется с облачными функциями GCP. Дополнительную информацию см. в README-localhost.md.
Теперь мы опишем различные шаги и предварительные условия для установки системы, учитывая, что реализации как GCP, так и локального хоста требуют, по крайней мере, некоторой локальной установки.
Настоятельно рекомендуется создать виртуальную среду, позволяющую обеспечить изолированную рабочую среду. Примеры хорошей рабочей среды: conda, pyenv и poerty.
Обратите внимание, что зависимости уже содержатся в requirements.txt , поэтому установите его с помощью pip:
pip install -r requirements.txt
Чтобы предотвратить случайное сохранение паролей, рекомендуется использовать перехватчики предварительной фиксации, которые предотвращают обработку коммитов git до того, как конфиденциальная информация попадет в репозиторий. Мы использовали перехватчики предварительной фиксации с https://github.com/ukgovdatascience/govcookiecutter.
При установке файла require.txt будет установлен инструмент предварительной фиксации, который теперь необходимо подключить к git:
pre-commit install
... который затем извлечет конфигурацию из .pre-commit-config.yaml .
ПРИМЕЧАНИЕ. Для теста предварительной фиксации check-added-large-files максимальный размер в КБ в .pre-commit-config.yaml временно увеличивается до 60 МБ при добавлении файла модели RCNN /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb . Затем ограничение возвращается к 5 МБ как разумный «нормальный» верхний предел.
Прежде чем продолжить, рекомендуется выполнить проверку всех файлов, чтобы убедиться, что ничего не обнаружено по ошибке:
pre-commit run --all-files
Это сообщит о любых существующих проблемах, что полезно, поскольку в противном случае перехватчик запускается только для отредактированных файлов.
Проект предназначен для использования преимущественно через облачную инфраструктуру, но существуют служебные сценарии для локального доступа и обновления временных рядов в облаке. Эти сценарии расположены в папке scripts/gcloud , каждый из которых теперь описан в отдельных разделах. Дополнительную информацию можно найти в scripts/gcloud/README.md , а их использование дополнительной виртуальной машиной описано в cloud/README.md .
Использование без облака поддерживается сценариями в папке scripts/localhost , а подробности использования системы chrono_lens на автономном компьютере описаны в README-localhost.md . Дополнительную информацию об использовании сценариев можно найти в scripts/localhost/README.md .
Обратите внимание, что сценарии используют код из папки chrono_lens .
| Версия | Дата | Примечания |
|---|---|---|
| 1.0.0 | 08.06.2021 | Первый выпуск публичного репозитория |
| 1.0.1 | 2021-09-21 | Исправление ошибок для изолированных изображений, повышение версии тензорного потока. |
| 1.1.0 | ? | Добавлена ограниченная поддержка отдельной машины. |
Здесь представлены области потенциальной будущей работы; эти изменения, возможно, не изучаются, но они созданы для того, чтобы люди знали о потенциальных улучшениях, которые мы рассмотрели.
В настоящее время для создания инфраструктуры GCP используются сценарии оболочки bash; улучшением было бы использование IaC, например Terraform. Это упрощает изменение (например) конфигураций облачных функций без необходимости вручную удалять триггер Cloud Build Trigger и заново создавать его при изменении среды выполнения или ограничений памяти.
Текущая конструкция основана на первоначальном варианте использования получения изображений до того, как модели были завершены, поэтому загружаются все доступные изображения, а не только те, которые анализируются. Чтобы сократить затраты на прием, код приема должен перекрестно сверяться с анализируемыми файлами JSON и загружать только эти файлы; предупреждение должно быть поднято, когда какой-либо из этих источников больше не доступен или если становятся доступными новые источники.
Ночное заполнение изображений для NETravelData обновляет около 40% изображений NETravelData; Преимущество регулярного обновления уменьшается, если числа требуются только ежедневно, и, следовательно, облачную функцию distribute_ne_travel_data можно удалить.
http async к PubSub Первоначальный дизайн использует сценарии, управляемые вручную, при тестировании новых моделей, а именно, batch_process_images.py . Здесь сообщается об успехе (или неудаче) и количестве обработанных изображений. Для этого хорошо подходит облачная функция, которая возвращает результат. Однако более эффективной архитектурой было бы использовать очередь PubSub внутри с функциями distribute_json_sources и processed_scheduled , добавляя работу в очереди PubSub, которые используются одной рабочей функцией, а не текущую иерархию асинхронных вызовов (с использованием двух дополнительных функций для масштабирования). ).
Городская обсерватория Университета Ньюкасла предоставила предварительно обученный Faster-RCNNN, который мы используем (локальная копия хранится в /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb ).
Данные предоставлены Службой открытых данных по управлению и контролю городского движения Северо-Востока, имеющей лицензию Open Government License 3.0. Изображения принадлежат компании Tyne and Wear Urban Traffic Management and Control.
Данные Северо-Востока далее обрабатываются и хранятся в Городской обсерватории Университета Ньюкасла, чью поддержку и советы мы с благодарностью отмечаем.
Данные предоставляются TfL и основаны на TfL Open Data. Данные лицензируются в соответствии с версией 2.0 Открытой правительственной лицензии. Данные TfL содержат данные ОС © Авторские права и права на базу данных Crown, 2016 г., а также данные карты Geomni UK © и права на базу данных (2019 г.).
В этом проекте используются различные сторонние библиотеки; они перечислены на странице зависимостей, чей вклад мы с благодарностью отмечаем.


