shap
v0.46.0
SHAP (SHapley Additive exPlanations) — это теоретико-игровой подход для объяснения результатов любой модели машинного обучения. Он связывает оптимальное распределение кредитов с локальными объяснениями, используя классические значения Шепли из теории игр и связанные с ними расширения (подробности и цитаты см. в статьях).
SHAP можно установить из PyPI или conda-forge:
форма установки пипа или установка conda -c форма conda-forge
Хотя SHAP может объяснить результаты любой модели машинного обучения, мы разработали высокоскоростной точный алгоритм для методов ансамбля деревьев (см. нашу статью Nature MI). Быстрые реализации C++ поддерживаются для моделей дерева XGBoost , LightGBM , CatBoost , scikit-learn и pyspark :
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])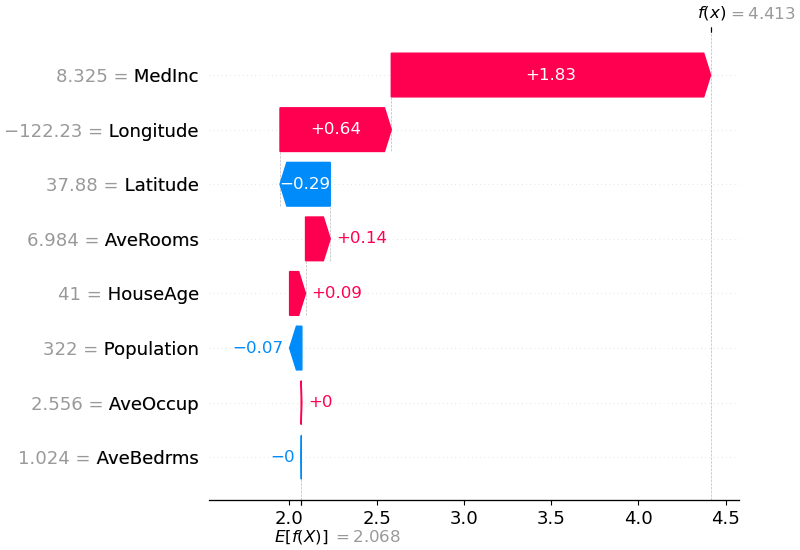
В приведенном выше объяснении показаны функции, каждая из которых способствует преобразованию выходных данных модели из базового значения (средний результат модели по переданному нами набору обучающих данных) к выходным данным модели. Функции, повышающие прогноз, показаны красным, а те, которые повышают прогноз, — синим. Другой способ визуализировать то же объяснение — использовать график сил (они представлены в нашей статье Nature BME):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
Если мы возьмем множество объяснений графика силы, таких как показанное выше, повернем их на 90 градусов, а затем сложим горизонтально, мы сможем увидеть объяснения для всего набора данных (в блокноте этот график интерактивный):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])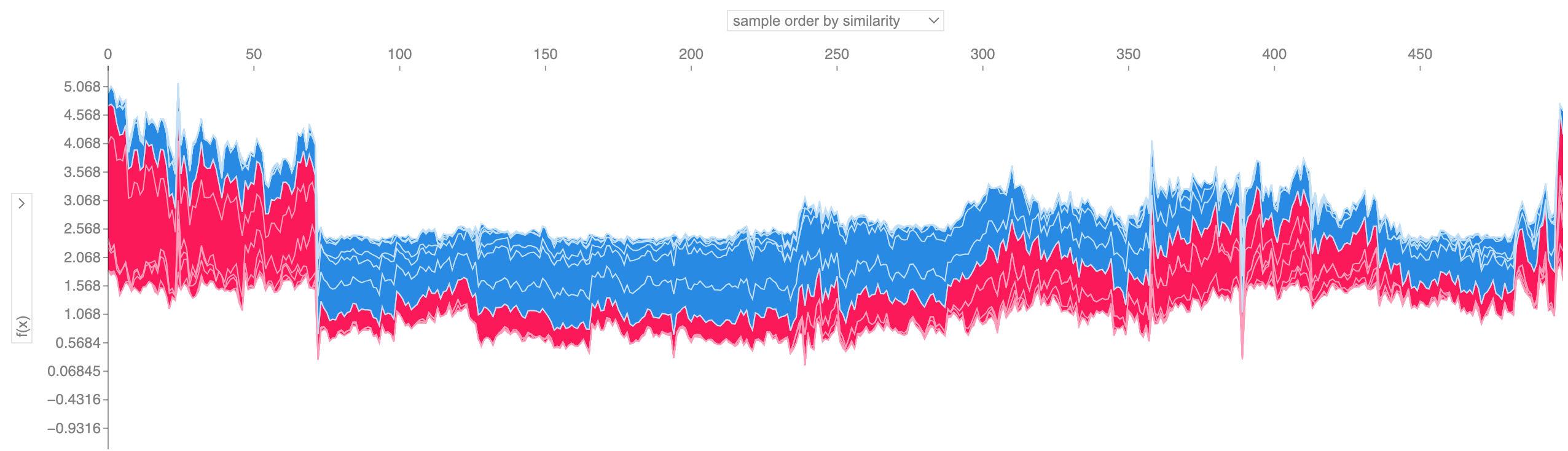
Чтобы понять, как отдельный объект влияет на выходные данные модели, мы можем построить график зависимости SHAP этого объекта от значения объекта для всех примеров в наборе данных. Поскольку значения SHAP представляют ответственность объекта за изменение выходных данных модели, график ниже представляет изменение прогнозируемой цены на дом при изменении широты. Вертикальная дисперсия на одном значении широты представляет собой эффекты взаимодействия с другими объектами. Чтобы выявить эти взаимодействия, мы можем раскрасить их по другому признаку. Если мы передадим весь тензор объяснения в аргумент color , то диаграмма рассеяния выберет лучший признак для раскрашивания. В данном случае он выбирает долготу.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )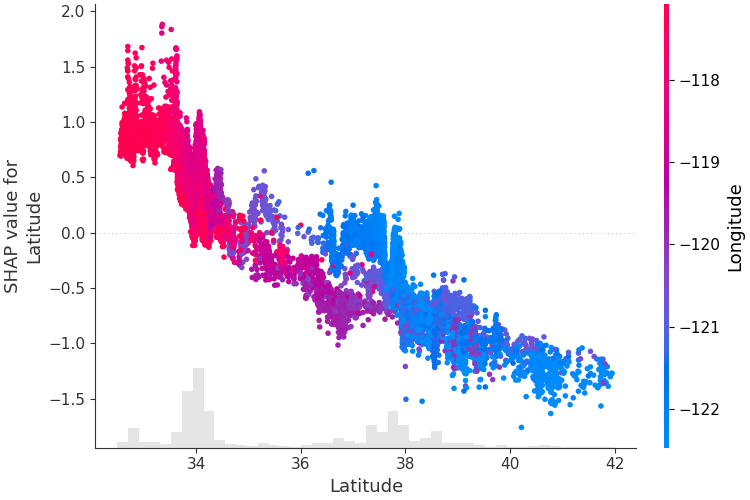
Чтобы получить представление о том, какие функции наиболее важны для модели, мы можем построить значения SHAP для каждой функции для каждого образца. На графике ниже объекты сортируются по сумме величин значений SHAP по всем выборкам и используются значения SHAP, чтобы показать распределение влияния каждого объекта на выходные данные модели. Цвет представляет значение функции (красный максимум, синий минимум). Это показывает, например, что более высокие медианные доходы улучшают прогнозируемую цену на жилье.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )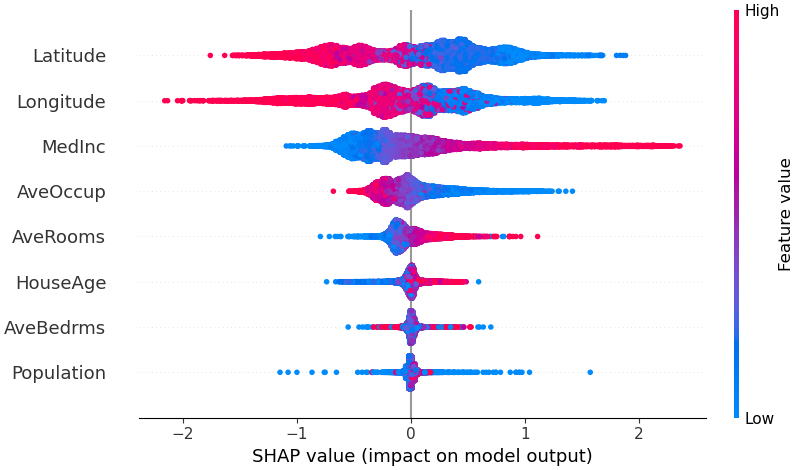
Мы также можем просто взять среднее абсолютное значение значений SHAP для каждого объекта, чтобы получить стандартную гистограмму (создает сложенные столбцы для выходных данных нескольких классов):
shap . plots . bar ( shap_values )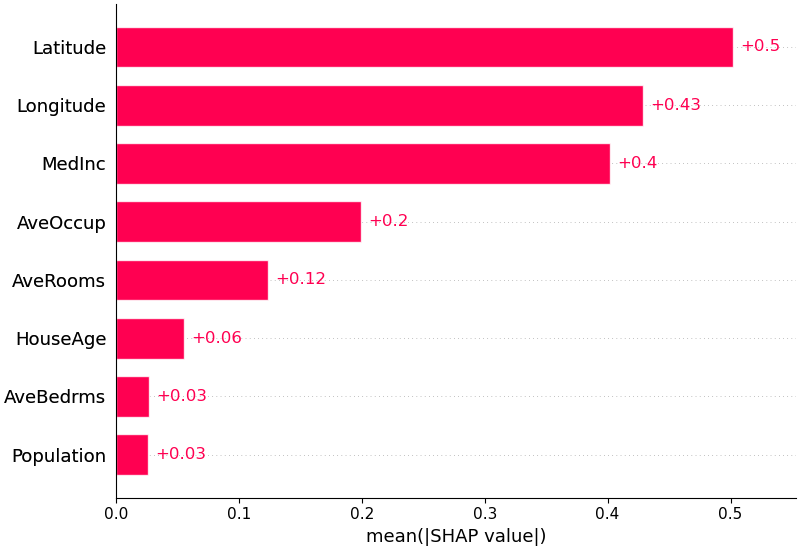
SHAP имеет специальную поддержку моделей естественного языка, например, в библиотеке преобразователей Hugging Face. Добавляя коалиционные правила к традиционным ценностям Шепли, мы можем создавать игры, которые объясняют большую современную модель НЛП, используя очень мало оценок функций. Использовать эту функциональность так же просто, как передать поддерживаемый конвейер преобразователей в SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP — это высокоскоростной алгоритм аппроксимации значений SHAP в моделях глубокого обучения, основанный на связи с DeepLIFT, описанной в документе SHAP NIPS. Реализация здесь отличается от исходного DeepLIFT использованием распределения фоновых выборок вместо одного эталонного значения и использованием уравнений Шепли для линеаризации таких компонентов, как max, softmax, продукты, подразделения и т. д. Обратите внимание, что некоторые из этих улучшений также были реализованы. с момента интеграции в DeepLIFT. Поддерживаются модели TensorFlow и модели Keras, использующие бэкэнд TensorFlow (также имеется предварительная поддержка PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])График выше объясняет десять выходных данных (цифры 0–9) для четырех разных изображений. Красные пиксели увеличивают выходные данные модели, а синие пиксели уменьшают выходные данные. Входные изображения показаны слева и в виде почти прозрачной полутоновой подложки позади каждого пояснения. Сумма значений SHAP равна разнице между ожидаемыми выходными данными модели (усредненными по фоновому набору данных) и текущими выходными данными модели. Обратите внимание, что для «нулевого» изображения важна пустая середина, а для изображения «четверки» отсутствие связи сверху делает его четверкой, а не девяткой.
Ожидаемые градиенты объединяют идеи интегрированных градиентов, SHAP и SmoothGrad в одно уравнение ожидаемого значения. Это позволяет использовать весь набор данных в качестве фонового распределения (в отличие от одного эталонного значения) и обеспечивает локальное сглаживание. Если мы аппроксимируем модель линейной функцией между каждой выборкой фоновых данных и текущими входными данными, которые нужно объяснить, и предположим, что входные объекты независимы, тогда ожидаемые градиенты будут вычислять приблизительные значения SHAP. В приведенном ниже примере мы объяснили, как 7-й промежуточный уровень модели VGG16 ImageNet влияет на выходные вероятности.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) Прогнозы для двух входных изображений объяснены на графике выше. Красные пиксели представляют положительные значения SHAP, которые увеличивают вероятность класса, а синие пиксели представляют отрицательные значения SHAP, которые уменьшают вероятность класса. Используя ranked_outputs=2 мы объясняем только два наиболее вероятных класса для каждого входа (это избавляет нас от объяснения всех 1000 классов).
Ядро SHAP использует специально взвешенную локальную линейную регрессию для оценки значений SHAP для любой модели. Ниже приведен простой пример объяснения многоклассовой SVM в классическом наборе данных радужной оболочки глаза.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )В приведенном выше объяснении показаны четыре функции, каждая из которых способствует увеличению выходных данных модели от базового значения (среднего результата модели по переданному нами набору обучающих данных) к нулю. Если бы были какие-либо функции, поднимающие метку класса выше, они были бы показаны красным.
Если мы возьмем множество объяснений, таких как показанное выше, повернём их на 90 градусов, а затем сложим по горизонтали, мы сможем увидеть объяснения для всего набора данных. Именно это мы и делаем ниже для всех примеров в наборе тестов радужной оболочки глаза:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) Значения взаимодействия SHAP представляют собой обобщение значений SHAP на взаимодействия более высокого порядка. Быстрое точное вычисление парных взаимодействий реализовано для древовидных моделей с помощью shap.TreeExplainer(model).shap_interaction_values(X) . Это возвращает матрицу для каждого прогноза, в которой основные эффекты находятся на диагонали, а эффекты взаимодействия — внедиагонали. Эти значения часто выявляют интересные скрытые взаимосвязи, например, пик повышенного риска смерти для мужчин в возрасте 60 лет (подробности см. в блокноте NHANES):
В блокнотах ниже демонстрируются различные варианты использования SHAP. Если вы хотите попробовать поиграть с оригинальными блокнотами самостоятельно, загляните в каталог блокнотов репозитория.
Реализация Tree SHAP, быстрого и точного алгоритма вычисления значений SHAP для деревьев и ансамблей деревьев.
Модель выживания NHANES со значениями взаимодействия XGBoost и SHAP . Используя данные о смертности за 20 лет наблюдения, этот блокнот демонстрирует, как использовать XGBoost и shap для выявления сложных взаимосвязей факторов риска.
Классификация доходов переписи населения с помощью LightGBM . Используя стандартный набор данных о доходах переписи взрослого населения, этот блокнот обучает древовидную модель повышения градиента с помощью LightGBM, а затем объясняет прогнозы с помощью shap .
Прогнозирование победы League of Legends с помощью XGBoost . Используя набор данных Kaggle, содержащий 180 000 рейтинговых матчей League of Legends, мы обучаем и объясняем древовидную модель повышения градиента с помощью XGBoost, чтобы предсказать, выиграет ли игрок свой матч.
Реализация Deep SHAP, более быстрого (но только приблизительного) алгоритма вычисления значений SHAP для моделей глубокого обучения, основанного на связях между SHAP и алгоритмом DeepLIFT.
Классификация цифр MNIST с помощью Keras . Используя набор данных распознавания рукописного ввода MNIST, этот блокнот обучает нейронную сеть с помощью Keras, а затем объясняет прогнозы с помощью shap .
Keras LSTM для классификации тональности IMDB . Этот блокнот обучает LSTM с помощью Keras на наборе данных анализа тональности текста IMDB, а затем объясняет прогнозы с помощью shap .
Реализация ожидаемых градиентов для аппроксимации значений SHAP для моделей глубокого обучения. Он основан на связях между SHAP и алгоритмом интегрированных градиентов. GradientExplainer работает медленнее, чем DeepExplainer, и делает другие предположения об аппроксимации.
Для линейной модели с независимыми функциями мы можем аналитически вычислить точные значения SHAP. Мы также можем учесть корреляцию признаков, если хотим оценить ковариационную матрицу признаков. LinearExplainer поддерживает оба этих варианта.
Реализация Kernel SHAP, независимого от модели метода оценки значений SHAP для любой модели. Поскольку KernelExplainer не делает никаких предположений о типе модели, он работает медленнее, чем другие алгоритмы, специфичные для типа модели.
Классификация доходов переписи с помощью scikit-learn . Используя стандартный набор данных о доходах переписи взрослого населения, этот блокнот обучает классификатор k-ближайших соседей с помощью scikit-learn, а затем объясняет прогнозы с помощью shap .
Модель ImageNet VGG16 с Keras . Объясните прогнозы классической сверточной нейронной сети VGG16 для изображения. Это работает путем применения независимого от модели метода Kernel SHAP к сегментированному по суперпикселям изображению.
Классификация ирисов . Базовая демонстрация с использованием набора данных популярных видов ирисов. Он объясняет прогнозы шести различных моделей в scikit-learn с использованием shap .
Эти блокноты подробно демонстрируют, как использовать определенные функции и объекты.
shap.decision_plot и shap.multioutput_decision_plot
shap.dependence_plot
LIME: Рибейро, Марко Тулио, Самир Сингх и Карлос Гестрин. «Почему я должен вам доверять?: Объяснение предсказаний любого классификатора». Материалы 22-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных. АКМ, 2016.
Значения выборки Шепли: Струмбель, Эрик и Игорь Кононенко. «Объяснение моделей прогнозирования и отдельных прогнозов с помощью функций». Знания и информационные системы 41.3 (2014): 647-665.
DeepLIFT: Шрикумар, Аванти, Пейтон Гринсайд и Аншул Кундадже. «Изучение важных функций посредством распространения различий активации». Препринт arXiv arXiv:1704.02685 (2017).
Вопрос II: Датта, Анупам, Шаяк Сен и Яир Зик. «Алгоритмическая прозрачность через количественное влияние входных данных: теория и эксперименты с системами обучения». Безопасность и конфиденциальность (SP), симпозиум IEEE 2016 г. ИИЭР, 2016.
Послойное распространение релевантности: Бах, Себастьян и др. «О попиксельных объяснениях решений нелинейного классификатора путем послойного распространения релевантности». PloS one 10.7 (2015): e0130140.
Значения регрессии Шепли: Липовецкий, Стэн и Майкл Конклин. «Анализ регрессии в подходе теории игр». Прикладные стохастические модели в бизнесе и промышленности 17.4 (2001): 319-330.
Древовидный переводчик: Саабас, Андо. Интерпретация случайных лесов. http://blog.datadive.net/interpreting-random-forests/
Алгоритмы и визуализации, используемые в этом пакете, были созданы в основном в результате исследований лаборатории Су-Ин Ли в Вашингтонском университете и исследований Microsoft. Если вы используете SHAP в своих исследованиях, мы будем признательны за ссылку на соответствующую статью(и):
force_plot и медицинских приложений вы можете прочитать/цитировать нашу статью о биомедицинской инженерии Nature (bibtex; свободный доступ).

