Candle — это минималистская платформа машинного обучения для Rust с упором на производительность (включая поддержку графических процессоров) и простоту использования. Попробуйте наши онлайн-демоверсии: шепот, LLaMA2, T5, yolo, Segment Anything.
Убедитесь, что candle-core установлен правильно, как описано в разделе «Установка» .
Давайте посмотрим, как выполнить простое умножение матриц. Напишите следующее в файл myapp/src/main.rs :
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run должен отображать тензор формы Tensor[[2, 4], f32] .
Установив candle с поддержкой Cuda, просто определите device , которое будет на GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;Более сложные примеры можно найти в следующем разделе.
Эти онлайн-демоверсии полностью работают в вашем браузере:
Мы также предоставляем несколько примеров на основе командной строки с использованием современных моделей:
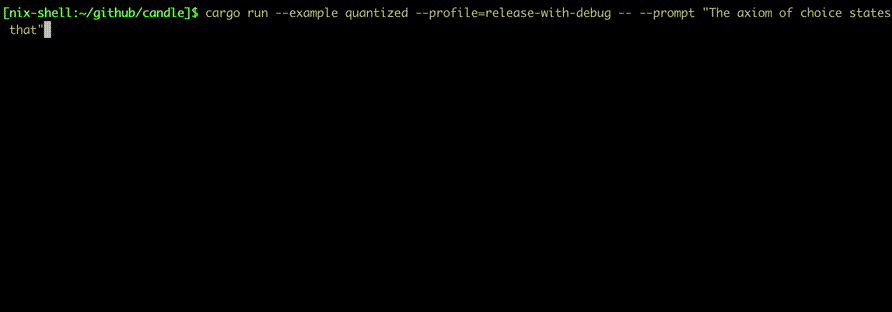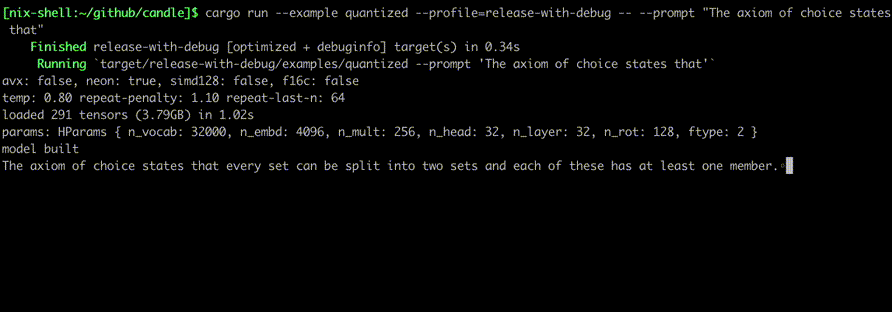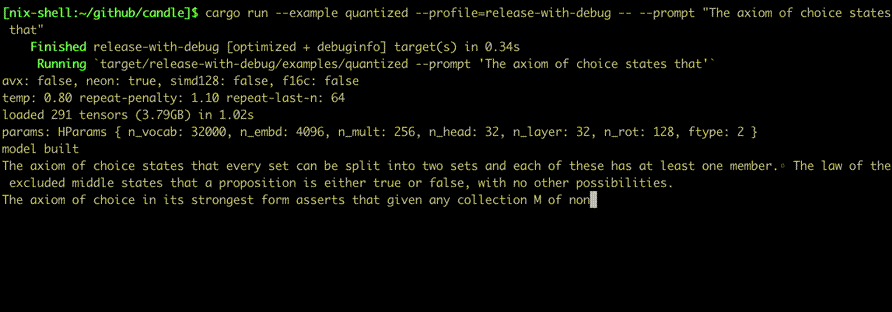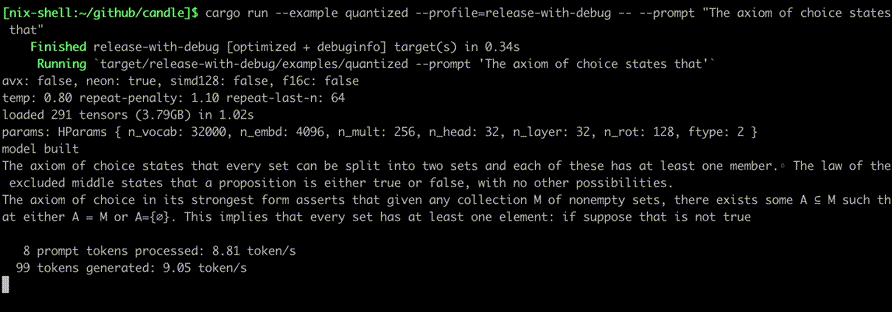





Запустите их, используя такие команды, как:
cargo run --example quantized --release
Чтобы использовать CUDA, добавьте --features cuda в пример командной строки. Если у вас установлен cuDNN, используйте --features cudnn для еще большего ускорения.
Также есть несколько примеров Wasm для шепота и llama2.c. Вы можете собрать их с помощью trunk или опробовать онлайн: шепот, лама2, T5, Phi-1.5 и Phi-2, модель сегментации чего угодно.
Для LLaMA2 выполните следующую команду, чтобы получить файлы весов и запустить тестовый сервер:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081А затем перейдите по адресу http://localhost:8081/.
candle-tutorial : очень подробное руководство, показывающее, как преобразовать модель PyTorch в Candle.candle-lora : эффективная и эргономичная реализация LoRA для Candle. candle-lora имеетoptimisers : набор оптимизаторов, включая SGD с импульсом, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam и RMSprop.candle-vllm : эффективная платформа для вывода и обслуживания локальных LLM, включая сервер API, совместимый с OpenAI.candle-ext : библиотека расширения для Candle, предоставляющая функции PyTorch, недоступные в настоящее время в Candle.candle-coursera-ml : реализация алгоритмов машинного обучения из курса специализации по машинному обучению Coursera.kalosm : мультимодальная мета-инфраструктура на Rust для взаимодействия с локальными предварительно обученными моделями с поддержкой контролируемой генерации, пользовательских сэмплеров, векторных баз данных в памяти, транскрипции звука и многого другого.candle-sampling : методы отбора проб для свечи.gpt-from-scratch-rs : порт учебника Андрея Карпати «Давайте создадим GPT» на YouTube, демонстрирующий API-интерфейс Candle для решения игрушечной проблемы.candle-einops : чистая реализация библиотеки einops Python.atoma-infer : библиотека Rust для быстрого вывода в масштабе, использующая FlashAttention2 для эффективного вычисления внимания, PagedAttention для эффективного управления памятью KV-кэша и поддержки нескольких графических процессоров. Он совместим с OpenAI API.Если у вас есть дополнение к этому списку, отправьте запрос на включение.
Шпаргалка:
| Использование PyTorch | Использование свечи | |
|---|---|---|
| Создание | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| Создание | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| Индексирование | tensor[:, :4] | tensor.i((.., ..4))? |
| Операции | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| Операции | a.matmul(b) | a.matmul(&b)? |
| Арифметика | a + b | &a + &b |
| Устройство | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Дтип | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| Сохранение | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| Загрузка | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
TensorОсновная цель Candle — сделать возможным бессерверный вывод . Платформы полного машинного обучения, такие как PyTorch, очень велики, что замедляет создание экземпляров в кластере. Candle позволяет развертывать легкие двоичные файлы.
Во-вторых, Candle позволяет удалить Python из рабочих нагрузок. Накладные расходы Python могут серьезно снизить производительность, а GIL — печально известный источник головной боли.
Наконец, Rust — это круто! Во многих частях экосистемы HF уже есть ящики Rust, такие как сейфтенсоры и токенизаторы.
dfdx — это огромный контейнер, в типы которого включены фигуры. Это позволяет избежать многих головных болей, заставляя компилятор сразу же жаловаться на несоответствие форм. Однако мы обнаружили, что некоторые функции по-прежнему требуют еженощной работы, а написание кода может быть немного утомительным для неспециалистов по ржавчине.
Мы используем и вносим вклад в другие основные ящики для среды выполнения, поэтому надеемся, что оба ящика смогут извлечь выгоду друг из друга.
burn — это общий набор, который может использовать несколько бэкэндов, чтобы вы могли выбрать лучший движок для своей рабочей нагрузки.
tch-rs Привязки к библиотеке torch в Rust. Чрезвычайно универсальны, но они включают в среду выполнения всю библиотеку факелов. Основной участник tch-rs также участвует в разработке candle .
Если при компиляции двоичных файлов/тестов с использованием функций mkl или ускорения вы получаете некоторые недостающие символы, например, для mkl, вы получаете:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
или для ускорения:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
Вероятно, это связано с отсутствием флага компоновщика, необходимого для включения библиотеки mkl. Вы можете попробовать добавить следующее для mkl в начало вашего двоичного файла:
extern crate intel_mkl_src ;или для ускорения:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
Вероятно, это связано с тем, что у вас нет прав на модель LLaMA-v2. Чтобы это исправить, вам необходимо зарегистрироваться на Huggingface-Hub, принять условия модели LLaMA-v2 и настроить токен аутентификации. Дополнительную информацию см. в выпуске № 350.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
Cutlass предоставляется как подмодуль git, поэтому вы можете запустить следующую команду, чтобы проверить его правильно.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
Это ошибка в gcc-11, вызванная компилятором Cuda. Чтобы это исправить, установите другую, поддерживаемую версию gcc — например gcc-10, и укажите путь к компилятору в переменной среды NVCC_CCBIN.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
Убедитесь, что вы связали все собственные библиотеки, которые могут находиться за пределами целевого объекта проекта, например, для запуска тестов mdbook вам следует запустить:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
Это может быть вызвано загрузкой моделей из /mnt/c , подробнее о stackoverflow.
Вы можете установить RUST_BACKTRACE=1 , чтобы получать обратные трассировки при возникновении ошибки свечи.
Если вы столкнулись с такой ошибкой, как эта, called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } в окнах. Чтобы исправить это, скопируйте и переименуйте эти 3 файла (убедитесь, что они находятся в правильном пути). Пути зависят от вашей версии cuda. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


