whisperX
3.1.1
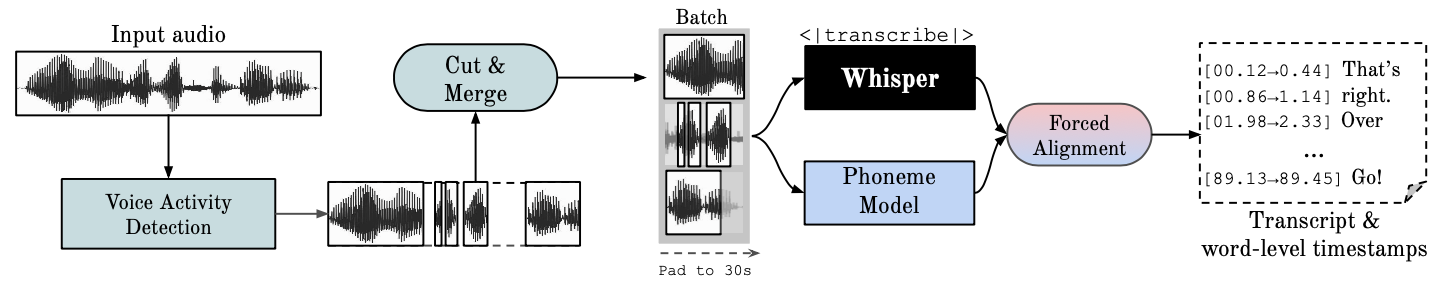
Этот репозиторий обеспечивает быстрое автоматическое распознавание речи (в 70 раз в реальном времени с big-v2) с временными метками на уровне слов и дневниковым описанием говорящего.
Whisper — это модель ASR, разработанная OpenAI и обученная на большом наборе данных разнообразного аудио. Несмотря на то, что он обеспечивает очень точную транскрипцию, соответствующие временные метки устанавливаются на уровне произнесения, а не на уровне каждого слова, и могут быть неточными на несколько секунд. Шепот OpenAI изначально не поддерживает пакетную обработку.
ASR на основе фонем. Набор моделей, настроенных на распознавание мельчайших единиц речи, отличающих одно слово от другого, например, элемента p в слове «tap». Популярный пример модели — wav2vec2.0.
Принудительное выравнивание — это процесс, посредством которого орфографические транскрипции выравниваются по аудиозаписям для автоматического создания сегментации на уровне телефона.
Обнаружение голосовой активности (VAD) — это обнаружение присутствия или отсутствия человеческой речи.
Диаризизация говорящего — это процесс разделения аудиопотока, содержащего человеческую речь, на однородные сегменты в соответствии с личностью каждого говорящего.
Для выполнения графического процессора в системе должны быть установлены библиотеки NVIDIA cuBLAS 11.x и cuDNN 8.x. Пожалуйста, обратитесь к документации CTranslate2.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
Другие способы смотрите здесь.
pip install git+https://github.com/m-bain/whisperx.git
Если пакет уже установлен, обновите его до последней фиксации.
pip install git+https://github.com/m-bain/whisperx.git --upgrade
Если вы хотите изменить этот пакет, клонируйте и установите его в редактируемом режиме:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
Вам также может потребоваться установить ffmpeg, Rust и т. д. Следуйте инструкциям openAI здесь https://github.com/openai/whisper#setup.
Чтобы включить «Диаризацию говорящего» , включите свой токен доступа «Обнимающее лицо» (прочитанный), который вы можете сгенерировать отсюда, после аргумента --hf_token , и примите пользовательское соглашение для следующих моделей: Сегментация и «Диаризация говорящего-3.1» (если вы решите использовать «Диаризацию говорящего»). -Диаризация 2.x, вместо этого следуйте требованиям здесь.)
Примечание
По состоянию на 11 октября 2023 г. существует известная проблема, связанная с низкой производительностью pyannote/Speaker-Diarization-3.0 в шепоте X. Это связано с конфликтами зависимостей между fast-whisper и pyannote-audio 3.0.0. Пожалуйста, ознакомьтесь с этой проблемой для получения более подробной информации и возможных обходных путей.
Запустите шепот в примере сегмента (используя параметры по умолчанию, шепот маленький). Добавьте --highlight_words True чтобы визуализировать тайминги слов в файле .srt.
whisperx examples/sample01.wav
Результат использования WhisperX с принудительным выравниванием по wav2vec2.0 big:
Сравните это с оригинальным шепотом из коробки, где многие транскрипции не синхронизированы:
Для повышения точности временных меток за счет увеличения памяти графического процессора используйте более крупные модели (большая модель выравнивания не оказалась такой полезной, см. статью), например
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
Чтобы пометить стенограмму идентификаторами докладчиков (установите количество говорящих, если известно, например --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
Для запуска на ЦП вместо графического процессора (и для работы в Mac OS X):
whisperx examples/sample01.wav --compute_type int8
Модель выравнивания фонем ASR зависит от языка . Для протестированных языков эти модели автоматически выбираются из конвейеров torchaudio или Huggingface. Просто введите код --language и используйте шепот --model large .
В настоящее время модели по умолчанию предоставляются для {en, fr, de, es, it, ja, zh, nl, uk, pt} . Если обнаруженного языка нет в этом списке, вам необходимо найти модель ASR на основе фонем в хабе моделей HuggingFace и протестировать ее на своих данных.
whisperx --model large-v2 --language de examples/sample_de_01.wav
Дополнительные примеры на других языках см. здесь.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs Если у вас нет доступа к собственным графическим процессорам, воспользуйтесь ссылками выше, чтобы опробовать WhisperX.
Подробные сведения о пакетной обработке и выравнивании, влиянии VAD, а также о выбранной модели выравнивания см. в препринте.
Чтобы снизить требования к памяти графического процессора, попробуйте любое из следующих действий (2 и 3 могут повлиять на качество):
--batch_size 4--model base--compute_type int8Отличия транскрипции от шепота Опенай:
--without_timestamps True , это обеспечивает 1 прямой проход для каждой выборки в пакете. Однако это может привести к несоответствию вывода шепота по умолчанию.--condition_on_prev_text по умолчанию имеет значение False (уменьшает галлюцинации) Если вы владеете несколькими языками, основной способ внести свой вклад в этот проект — это найти модели фонем на «обнимающем лице» (или тренировать свои собственные) и проверить их на речи для целевого языка. Если результаты кажутся хорошими, отправьте запрос на включение и несколько примеров, показывающих его успех.
Поиск ошибок и запросы на включение также очень приветствуются для продолжения этого проекта, поскольку он уже отклоняется от первоначального объема исследования.
Многоязычная инициализация
Автоматический выбор модели выравнивания на основе определения языка
Использование Python
Включение диаризации спикеров
Сброс модели, для небольших ресурсов памяти графического процессора
Серверная часть с более быстрым шепотом
Добавьте max-line и т. д. см. (шепот openai utils.py)
Сегменты на уровне предложения (панель инструментов nltk)
Улучшение логики выравнивания
обновить примеры с помощью дневникизации и выделения слов
Вывод субтитров .ass <- вернуть это (удалено в версии 3)
Добавьте код сравнительного анализа (TEDLIUM для spd/WER и сегментации слов)
Разрешить silero-vad как альтернативный вариант VAD
Улучшите дневникизацию (на уровне слов). Сложнее, чем казалось на первый взгляд...
Свяжитесь с [email protected] для вопросов.
Эта работа и моя докторская степень поддерживаются VGG (Группа визуальной геометрии) и Оксфордским университетом.
Конечно, это основано на слухах openAI. Заимствует важный код выравнивания из руководства PyTorch по принудительному выравниванию. И использует замечательный pyannote VAD/Diarization https://github.com/pyannote/pyannote-audio.
Ценные модели VAD и диаризации из [pyannote audio][https://github.com/pyannote/pyannote-audio]
Отличный бэкэнд от fast-whisper и CTranslate2.
Те, кто поддержал эту работу финансово
Наконец, спасибо разработчикам ОС этого проекта, поддерживающим его работу и выявляющим ошибки.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

