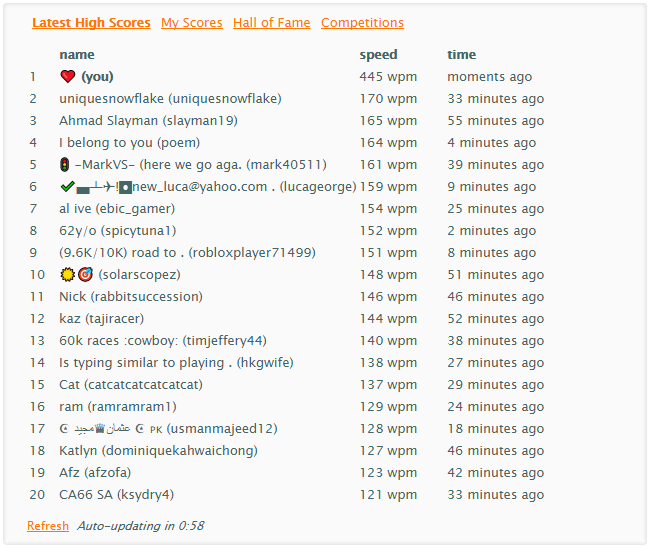
В этом репозитории содержится сценарий, который я использовал, чтобы победить в онлайн-игре по набору текста, возглавив таблицу лидеров с нечеловеческим показателем WPM почти 450.
Я не рекомендую использовать этот скрипт на typeracer, он противоречит TOS (ваша учетная запись будет забанена, как и моя) и загрязняет таблицу лидеров для других реальных игроков. Вместо этого я считаю этот проект просто интересным экспериментом и обучающим опытом.
Для тех, кому интересно, я изложил ниже каждый этап процесса. Обратите внимание, что этот конкретный метод может больше не работать в будущем, поскольку typeracer может (и должен) изменить процедуру проверки пользователя. Я могу подтвердить, что этот скрипт работает по состоянию на 16 февраля 2020 г.
На самом деле автоматически ввести гонку так же просто, как извлечь текст из DOM и отправить правильный набор ключевых событий JavaScript.
Хотя скорость вашей гонки определяется временным интервалом между ложными нажатиями клавиш (который может быть сколь угодно низким), похоже, что если в какой-то момент ваш WPM превысит 450, вас выкинут из игры. Таким образом, существует верхний предел WPM, который может получить сценарий. Чтобы достичь скорости 445 слов в минуту (самая высокая скорость, которую мне удалось получить), нажатия клавиш были разделены случайными интервалами времени от 22,5 до 26,5 мс.
После достаточно высокого WPM (>100) вам предоставляется изображение капчи, которое не имеет чисто текстовой формы нигде на стороне клиента — это настоящая проблема.
Чтобы подтвердить свой результат, вы должны иметь возможность ввести капчу в течение заданного времени и с достаточно высокой точностью (~ 95% или выше). Капчи всегда содержат 5 строк искаженного (курсивного и синусоидального) текста с черными отметинами, покрывающими изображение.

Типичная капча
Заполнение капчи — относительно долгий, запутанный, вероятностный, спекулятивный и ручной процесс, однако его нужно выполнить только один раз, поэтому я не собираюсь упрощать этот процесс.
Перед чтением изображения сценарий выполняет некоторую предварительную обработку, используя временный HTML-холст, чтобы упростить распознавание текста. В частности, изображение сканируется на наличие пикселей, которые достаточно темные, чтобы потенциально быть частью черной маркировки. Когда пиксель найден, он изменяется, чтобы представлять тот же цвет, что и фон в этой точке изображения.

То же изображение капчи после предварительной обработки
После применения этой процедуры я также попытался обратить вспять эффект синисоидальной деформации. Это было весьма эффективно для улучшения читаемости данного изображения, однако фактический период эффекта деформации варьируется между изображениями на несколько пикселей. Даже применение эффекта смещения на пару пикселей значительно снижает читаемость к концу изображения, поскольку волна становится противофазной. Поэтому я решил убрать этот раздел предварительной обработки.
Следующим шагом является отправка созданного предварительно обработанного изображения в библиотеку OCR (оптического распознавания символов) под названием Tesseract. Чтобы весь скрипт мог работать в браузере, он использует JS-порт библиотеки, доступной здесь.
Через несколько секунд Tesseract вернет фрагмент текста с точностью, обычно от 65% до 85%.
Анализ текста, возвращенного Tesseract, выявил некоторые распространенные ошибки, которые я мог вручную исправить с помощью некоторых манипуляций со строками.
Это состояло из различных замен символов, таких как
После завершения предыдущего шага текст вводится в текстовое поле, используемое для завершения ввода капчи. На этом этапе текст еще не имеет достаточно высокой точности, чтобы пройти капчу, однако есть время для ручного редактирования, в запасе около 3-5 секунд.
Чтобы облегчить этот процесс, простые орфографические ошибки можно легко исправить с помощью встроенной в браузеры проверки орфографии (щелкните правой кнопкой мыши, выберите рекомендуемые слова из списка).
После всех этих шагов мне потребовалось всего около полдюжины попыток, чтобы получить точность, удовлетворяющую капче.