LARS
v2.0-beta8:

LARS — это приложение, которое позволяет вам запускать LLM (большие языковые модели) локально на вашем устройстве, загружать свои собственные документы и участвовать в беседах, в которых LLM основывает свои ответы на загруженном вами контенте. Это заземление помогает повысить точность и уменьшить распространенную проблему неточностей или «галлюцинаций», генерируемых ИИ. Этот метод широко известен как «Поисковая дополненная генерация» или RAG.
Существует множество настольных приложений для локального запуска LLM, и LARS стремится стать лучшим приложением LLM с открытым исходным кодом, ориентированным на RAG. С этой целью LARS развивает концепцию RAG гораздо дальше, добавляя подробные цитаты к каждому ответу, предоставляя вам конкретные названия документов, номера страниц, выделение текста и изображения, относящиеся к вашему вопросу, и даже предоставляя программу чтения документов прямо в окно ответа. Хотя все цитаты не всегда присутствуют для каждого ответа, идея состоит в том, чтобы иметь хотя бы некоторую комбинацию цитат для каждого ответа RAG, и это, как правило, так и есть.
Демонстрационное видео LARS
Python v3.10.x или выше: https://www.python.org/downloads/
ПиТорч:
Если вы планируете использовать свой графический процессор для запуска LLM, обязательно установите драйверы графического процессора и наборы инструментов CUDA/ROCm, соответствующие вашей настройке, и только затем приступайте к настройке PyTorch ниже.
Загрузите и установите версию PyTorch, подходящую для вашей системы: https://pytorch.org/get-started/locally/
Клонируем репозиторий:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensУстановите зависимости Python:
Windows через PIP:
pip install -r .requirements.txt
Linux через PIP:
pip3 install -r ./requirements.txt
Примечание по Azure. Некоторые необходимые библиотеки Azure НЕ доступны на платформе MacOS! Поэтому для MacOS включен отдельный файл требований, за исключением этих библиотек:
МакОС:
pip3 install -r ./requirements_mac.txt
Вернуться к оглавлению
После установки запустите LARS, используя:
cd web_app
python app.py # Use 'python3' on Linux/macOS
Перейдите по адресу http://localhost:5000/ в своем браузере.
Все каталоги приложений, необходимые для LARS, теперь будут созданы на диске.
Сервер HF-Waitress автоматически запустится и загрузит LLM (Microsoft Phi-3-Mini-Instruct-44) при первом запуске, что может занять некоторое время в зависимости от скорости вашего интернет-соединения.
При первом запросе модель внедрения (all-mpnet-base-v2) будет загружена из HuggingFace Hub, что займет некоторое время.
Вернуться к оглавлению
В Windows:
Загрузите Microsoft Visual Studio Build Tools 2022 с официального сайта — «Инструменты для Visual Studio».
ПРИМЕЧАНИЕ. При установке вышеперечисленного обязательно выберите следующие компоненты:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
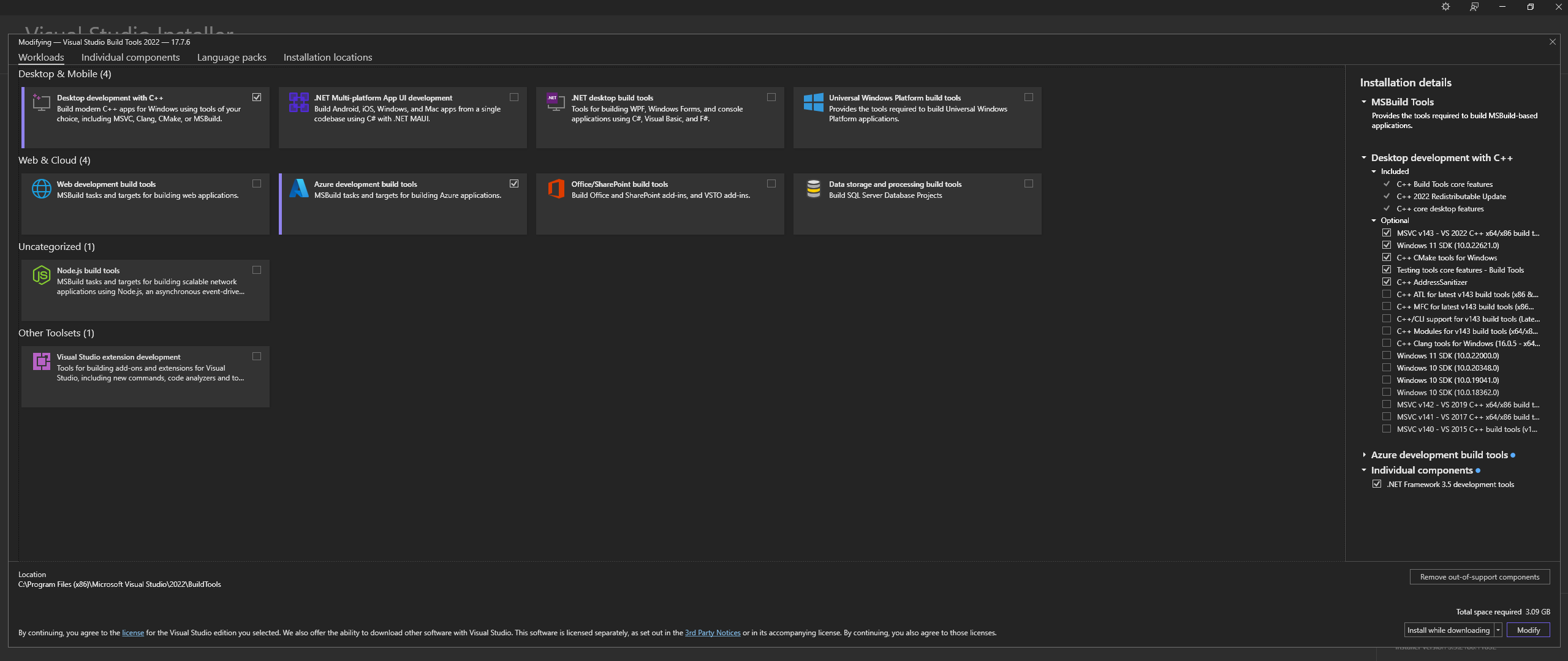
Desktop development with C++ », а также дополнительные параметры MSVC and C++ CMake выбраны, как описано выше.В Linux (на базе Ubuntu и Debian) установите следующие пакеты:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
Скачать из официального репо:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Установите CMAKE в Windows с официального сайта.
C:Program FilesCMakebinСоздайте llama.cpp с помощью CMAKE:
Примечание. Для более быстрой компиляции добавьте аргумент -j для параллельного запуска нескольких заданий. Например, cmake --build build --config Release -j 8 будет параллельно запускать 8 заданий.
Сборка с помощью CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
Если вы столкнулись с проблемами при попытке запустить CMake -B build , ознакомьтесь с подробной информацией по устранению неполадок при установке CMake ниже.
Добавить в ПУТЬ:
path_to_cloned_repollama.cppbuildbinRelease
Проверьте установку через терминал:
llama-server
Установите драйверы графического процессора Nvidia
Установите Nvidia CUDA Toolkit — LARS, созданный и протестированный с версиями 12.2 и 12.4.
Проверьте установку через терминал:
nvcc -V
nvidia-smi
Исправление CMAKE-CUDA (очень важно!):
Скопируйте все четыре файла из следующего каталога:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
и вставьте их в следующий каталог:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
Это необязательная, но настоятельно рекомендуемая зависимость. Если эта настройка не завершена, поддерживаются только PDF-файлы.
Окна:
Скачать с официального сайта
Добавьте в PATH либо через:
Расширенные настройки системы -> Переменные среды -> Системные переменные -> EDIT PATH Variable -> Добавьте следующее (измените в соответствии с местом установки):
C:Program FilesLibreOfficeprogram
Или через PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux на базе Ubuntu и Debian — загрузите с официального сайта или установите через терминал:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora и другие дистрибутивы на основе RPM — загрузите с официального сайта или установите через терминал:
sudo dnf update
sudo dnf install libreoffice
MacOS — загрузите с официального сайта или установите через Homebrew:
brew install --cask libreoffice
Проверьте установку:
В Windows и MacOS: запустите приложение LibreOffice.
В Linux через терминал:
libreoffice --version
LARS использует библиотеку Python pdf2image для преобразования каждой страницы документа в изображение, необходимое для оптического распознавания символов. Эта библиотека по сути является оболочкой утилиты Poppler, которая управляет процессом преобразования.
Окна:
Скачать из официального репо
Добавьте в PATH либо через:
Расширенные настройки системы -> Переменные среды -> Системные переменные -> EDIT PATH Variable -> Добавьте следующее (измените в соответствии с местом установки):
path_to_installationpoppler_versionLibrarybin
Или через PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Линукс:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
Это необязательная зависимость: Tesseract-OCR не используется активно в LARS, но методы его использования присутствуют в исходном коде.
Окна:
Загрузите Tesseract-OCR для Windows через UB-Mannheim
Добавьте в PATH либо через:
Расширенные настройки системы -> Переменные среды -> Системные переменные -> EDIT PATH Variable -> Добавьте следующее (измените в соответствии с местом установки):
C:Program FilesTesseract-OCR
Или через PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
Вернуться к оглавлению
LARS был создан и протестирован с использованием Python v3.11.x.
Установите Python v3.11.x в Windows:
Скачать v3.11.9 с официального сайта
Во время установки обязательно установите флажок «Добавить Python 3.11 в PATH» или добавьте его вручную позже, либо через:
Расширенные настройки системы -> Переменные среды -> Системные переменные -> EDIT PATH Variable -> Добавьте следующее (измените в соответствии с местом установки):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
Или через PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Установите Python v3.11.x в Linux (на базе Ubuntu и Debian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
Проверьте установку через терминал:
python3 --version
Если вы столкнулись с ошибками при pip install , попробуйте следующее:
Удалить номера версий:
==version.number , например:urllib3==2.0.4urllib3Создайте и используйте виртуальную среду Python:
Желательно использовать виртуальную среду, чтобы избежать конфликтов с другими проектами Python.
Окна:
Создайте виртуальную среду Python (venv):
python -m venv larsenv
Активируйте и впоследствии используйте venv:
.larsenvScriptsactivate
Деактивируйте venv, когда закончите:
deactivate
Linux и MacOS:
Создайте виртуальную среду Python (venv):
python3 -m venv larsenv
Активируйте и впоследствии используйте venv:
source larsenv/bin/activate
Деактивируйте venv, когда закончите:
deactivate
Если проблемы не исчезнут, рассмотрите возможность открытия проблемы в репозитории LARS GitHub для получения поддержки.
CMake nmake failed , как показано ниже: 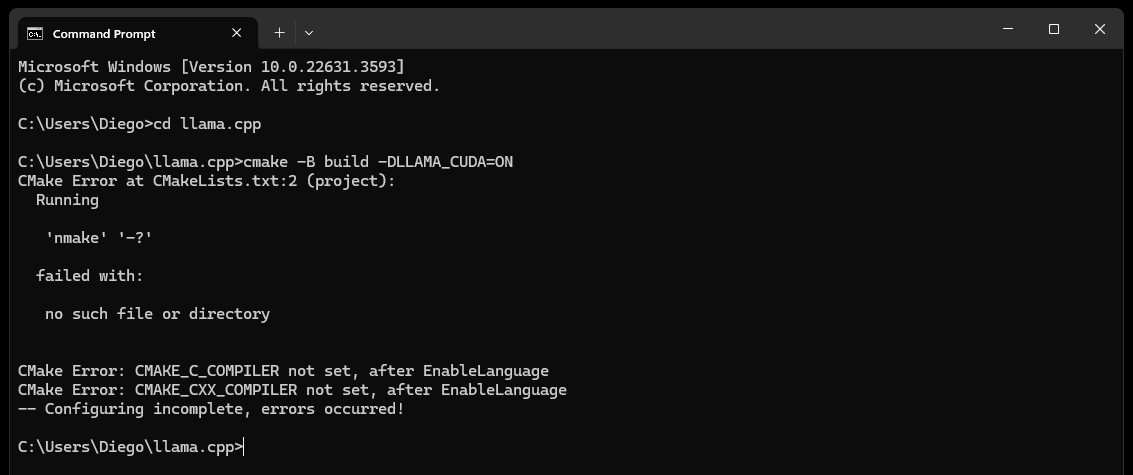
Обычно это указывает на проблему с вашими инструментами сборки Microsoft Visual Studio, поскольку CMake не может найти инструмент nmake, который является частью инструментов сборки Microsoft Visual Studio. Попробуйте выполнить следующие действия, чтобы решить проблему:
Убедитесь, что установлены инструменты сборки Visual Studio:
Убедитесь, что у вас установлены инструменты сборки Visual Studio, включая nmake. Эти инструменты можно установить с помощью установщика Visual Studio, выбрав рабочую нагрузку Desktop development with C++ и дополнительные параметры MSVC and C++ CMake
Проверьте шаг 0 раздела «Зависимости», в частности, скриншот в нем.
Проверьте переменные среды:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
Используйте командную строку разработчика:
Откройте «Командную строку разработчика для Visual Studio», которая настраивает для вас необходимые переменные среды.
Вы можете найти это приглашение в меню «Пуск» в Visual Studio.
Установите генератор CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
Если проблемы не исчезнут, рассмотрите возможность открытия проблемы в репозитории LARS GitHub для получения поддержки.
В конце концов (примерно через 60 секунд) на странице вы увидите предупреждение об ошибке:
Failed to start llama.cpp local-server
Это означает, что первый запуск завершен, все каталоги приложений созданы, но в каталоге models нет LLM, и теперь их можно переместить в него.
Переместите ваши LLM (любой формат файлов, поддерживаемый llama.cpp, предпочтительно GGUF) во вновь созданный каталог models , расположенный по умолчанию в следующих местах:
C:/web_app_storage/models/app/storage/models/app/models После того как вы разместили свои LLM в каталоге соответствующих models выше, обновите http://localhost:5000/
Примерно через 60 секунд вы снова получите предупреждение об ошибке с сообщением « Failed to start llama.cpp local-server
Это связано с тем, что теперь ваш LLM необходимо выбрать в меню Settings LARS.
Примите предупреждение и нажмите значок шестеренки Settings в правом верхнем углу.
На вкладке LLM Selection выберите LLM и соответствующий формат шаблона подсказки из соответствующих раскрывающихся списков.
Измените дополнительные настройки, чтобы правильно установить параметры GPU , Context-Length и, при необходимости, предел генерации токена ( Maximum tokens to predict ) для выбранного LLM.
Нажмите Save , и если автоматическое обновление не запускается, обновите страницу вручную.
Если все шаги выполнены правильно, первоначальная настройка завершена и LARS готов к использованию.
LARS также запомнит ваши настройки LLM для последующего использования.
Вернуться к оглавлению
Поддерживаемые форматы документов:
Если LibreOffice установлен и добавлен в PATH, как описано в шаге 4 раздела «Зависимости», поддерживаются следующие форматы:
Если LibreOffice не установлен, поддерживаются только PDF-файлы.
Параметры OCR для извлечения текста:
LARS предоставляет три метода извлечения текста из документов с учетом различных типов и качества документов:
Локальное извлечение текста: использует PyPDF2 для эффективного извлечения текста из неотсканированных PDF-файлов. Идеально подходит для быстрой обработки, когда высокая точность не имеет решающего значения или необходима полностью локальная обработка.
Azure ComputerVision OCR — повышает точность извлечения текста и поддерживает отсканированные документы. Полезно для обработки стандартных макетов документов. Предлагает уровень бесплатного пользования, подходящий для начальных пробных версий и использования в небольших объемах, с ограничением 5000 транзакций в месяц при скорости 20 транзакций в минуту.
Azure AI Document Intelligence OCR — лучше всего подходит для документов со сложной структурой, например таблиц. Специальный парсер в LARS оптимизирует процесс извлечения.
ПРИМЕЧАНИЯ:
Варианты Azure OCR в большинстве случаев требуют затрат на API и не входят в комплект LARS.
Ограниченная бесплатная версия для ComputerVision OCR доступна по ссылке выше. Эта услуга в целом дешевле, но медленнее и может не работать для нестандартных макетов документов (кроме A4 и т. д.).
При выборе варианта оптического распознавания символов учитывайте типы документов и ваши требования к точности.
LLM:
В настоящее время поддерживаются только локальные LLM.
Меню Settings предоставляет опытному пользователю множество опций для настройки и изменения LLM через вкладку LLM Selection .
Обратите внимание, что при использовании llama.cpp: Очень важно: выберите подходящий формат шаблона приглашения для используемого LLM.
LLM, обученные для следующих форматов шаблонов подсказок, в настоящее время поддерживаются через llama.cpp:
Настройте параметры базовой конфигурации с помощью Advanced Settings (запускает перезагрузку LLM и обновление страницы):
Измените настройки, чтобы изменить поведение ответа в любое время:
Встраивание моделей и векторной базы данных:
В LARS предусмотрены четыре модели внедрения:
За исключением внедрений Azure-OpenAI, все остальные модели работают полностью локально и бесплатно. При первом запуске эти модели будут загружены из HuggingFace Hub. Это однократная загрузка, и впоследствии они будут присутствовать локально.
Пользователь может переключаться между этими моделями внедрения в любое время через вкладку VectorDB & Embedding Models в меню Settings .
Таблица загруженных документов: в меню Settings отображается таблица для выбранной модели внедрения, в которой отображается список документов, встроенных в связанную векторную базу данных. Если документ загружается несколько раз, в этой таблице будет несколько записей, что может быть полезно для устранения любых проблем.
Очистка базы данных векторов: используйте кнопку Reset и подтвердите очистку выбранной базы данных векторов. При этом на диске создается новая база данных VectorDB для выбранной модели внедрения. Старая векторная база данных все еще сохраняется, и к ней можно вернуться, вручную изменив файл config.json.
Редактировать системную подсказку:
Системная подсказка служит инструкцией для LLM на протяжении всего разговора.
LARS предоставляет пользователю возможность редактировать системную подсказку через меню Settings , выбрав опцию Custom в раскрывающемся списке на вкладке « System Prompt .
Изменения в системной подсказке начнут новый чат.
Принудительно включить/отключить RAG:
Через меню Settings пользователь может принудительно включить или отключить RAG (дополненная генерация извлечения — использование содержимого ваших документов для улучшения ответов, генерируемых LLM), когда это необходимо.
Это часто полезно для оценки ответов LLM в обоих сценариях.
Принудительное отключение также приведет к отключению функций атрибуции.
Рекомендуемым вариантом является настройка по умолчанию, которая использует NLP для определения того, когда следует и не следует выполнять RAG.
Эту настройку можно изменить в любое время
История чата:
Используйте меню истории чата в левом верхнем углу, чтобы просмотреть и возобновить предыдущие разговоры.
Очень важно: при возобновлении предыдущих бесед обращайте внимание на несоответствия шаблонов подсказок! Используйте значок Information в правом верхнем углу, чтобы убедиться, что LLM, использованный в предыдущем разговоре, и LLM, используемый в настоящее время, основаны на одних и тех же форматах шаблонов подсказок!
Рейтинг пользователя:
Каждый ответ может быть оценен пользователем по 5-балльной шкале в любое время.
Данные рейтингов хранятся в базе данных chat-history.db SQLite3, расположенной в каталоге приложения:
C:/web_app_storage/app/storage/appДанные рейтингов очень ценны для оценки и доработки инструмента для ваших рабочих процессов.
Что можно и чего нельзя:
Вернуться к оглавлению
Если чат идет не так или появляются странные ответы, просто попробуйте запустить New Chat через меню в левом верхнем углу.
Либо начните новый чат, просто обновив страницу.
Если возникли проблемы с цитированием или производительностью RAG, попробуйте сбросить векторную базу данных, как описано в шаге 4 Общего руководства пользователя выше.
Если какие-либо проблемы с приложением возникают и не решаются простым запуском нового чата или перезапуском LARS, попробуйте удалить файл config.json, выполнив следующие действия:
CTRL+Cconfig.json , расположенный в LARS/web_app (тот же каталог, что и app.py ).В случае каких-либо серьезных проблем с данными и цитированием, которые не удается устранить даже путем сброса VectorDB, как описано в шаге 4 Общего руководства пользователя выше, выполните следующие действия:
CTRL+CC:/web_app_storage/app/storage/appЕсли проблемы не исчезнут, рассмотрите возможность открытия проблемы в репозитории LARS GitHub для получения поддержки.
Вернуться к оглавлению
LARS был адаптирован к среде развертывания контейнера Docker с помощью двух отдельных изображений, как показано ниже:
Оба имеют разные требования: первый представляет собой более простое развертывание, но имеет гораздо более низкую производительность вывода из-за того, что ЦП и память DDR действуют как узкие места.
Хотя это и не является явным требованием, некоторый опыт работы с контейнерами Docker и знание концепций контейнеризации и виртуализации будут очень полезны в этом разделе!
Начнем с общих шагов настройки для обоих:
Установка Докера
Ваш процессор должен поддерживать виртуализацию, и она должна быть включена в BIOS/UEFI вашей системы.
Загрузите и установите Docker Desktop.
Если вы используете Windows, вам может потребоваться установить подсистему Windows для Linux, если она еще не установлена. Для этого откройте PowerShell от имени администратора и выполните следующее:
wsl --install
Убедитесь, что Docker Desktop запущен и работает, затем откройте командную строку/терминал и выполните следующую команду, чтобы убедиться, что Docker правильно установлен и работает:
docker ps
Создайте том хранилища Docker, который будет подключен к контейнерам LARS во время выполнения:
Создание тома хранения для использования с контейнером LARS очень выгодно, поскольку оно позволит вам обновить контейнер LARS до более новой версии или переключаться между вариантами контейнера CPU и GPU, сохраняя при этом все ваши настройки, историю чата и векторные базы данных. .
Выполните следующую команду в командной строке/терминале:
docker volume create lars_storage_volue
Этот том будет присоединен к контейнеру LARS позже во время выполнения, а сейчас приступайте к созданию образа LARS, выполнив следующие шаги.
В командной строке/терминале выполните следующие команды:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
После этого перейдите по адресу http://localhost:5000/ в своем браузере и следуйте оставшейся части шагов первого запуска и руководства пользователя.
Разделы «Устранение неполадок» применимы и к Container-LARS.
Требования (помимо Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Для Linux у вас все настроено с учетом вышеизложенного, поэтому пропустите следующий шаг и переходите непосредственно к шагам сборки и запуска, приведенным ниже.
Если вы используете Windows и впервые запускаете контейнер графического процессора Nvidia на Docker, пристегнитесь, так как это будет непростая поездка (настоятельно рекомендуется один или три любимых напитка!)
Рискуя получить чрезмерную избыточность, прежде чем продолжить, убедитесь, что присутствуют следующие зависимости:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
Если вы не уверены, обратитесь к разделу «Зависимости Nvidia CUDA» и разделу «Настройка Docker» выше.
Если вышеперечисленное присутствует и настроено, можно продолжить.
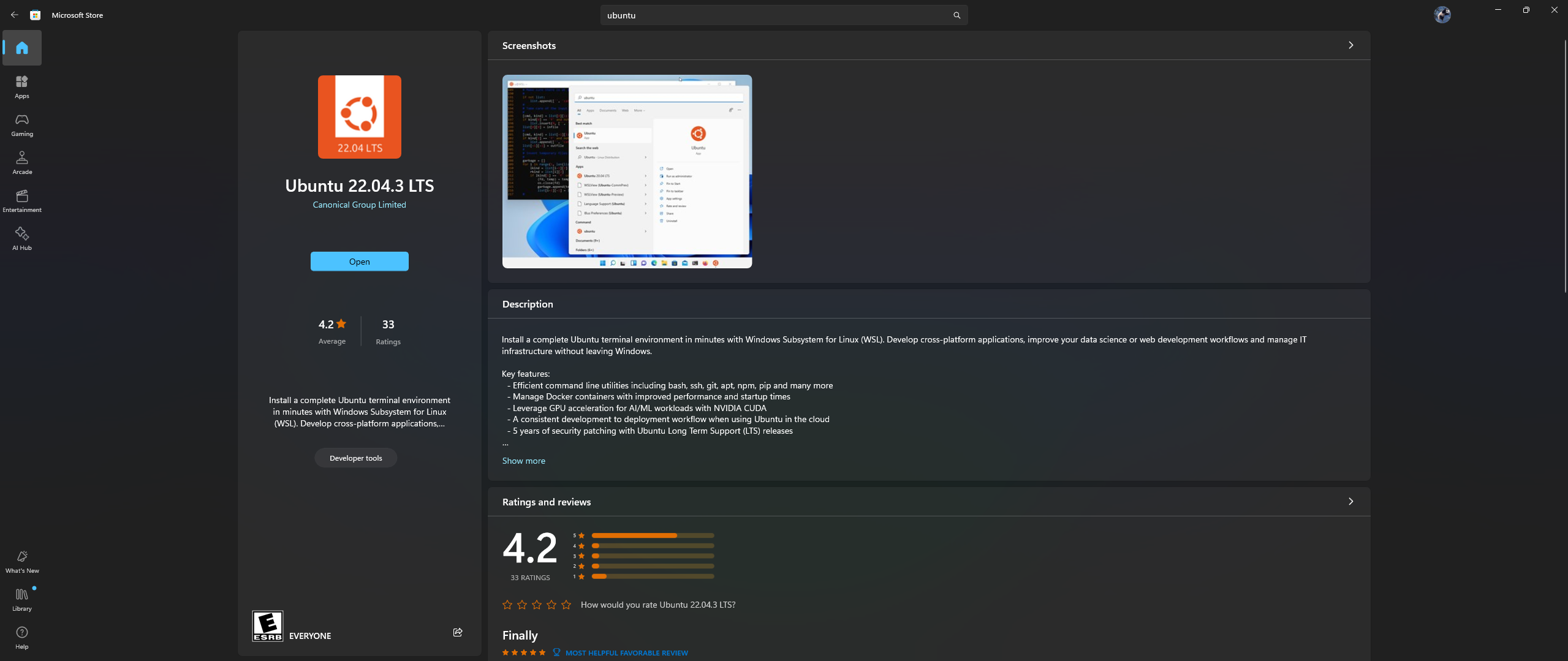
Откройте приложение Microsoft Store на своем ПК, загрузите и установите Ubuntu 22.04.3 LTS (версия должна совпадать с версией, указанной в строке 2 файла docker).
Да, вы правильно прочитали вышеизложенное: загрузите и установите Ubuntu из приложения Microsoft Store, см. снимок экрана ниже:
Пришло время установить Nvidia Container Toolkit в Ubuntu. Для этого выполните следующие действия:
Запустите оболочку Ubuntu в Windows, выполнив поиск Ubuntu в меню «Пуск» после завершения установки, указанной выше.
В открывшейся командной строке Ubuntu выполните следующие шаги:
Настройте производственный репозиторий:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Обновите список пакетов из репозитория и установите пакеты Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Настройте среду выполнения контейнера с помощью команды nvidia-ctk, которая изменяет файл /etc/docker/daemon.json, чтобы Docker мог использовать среду выполнения контейнера Nvidia:
sudo nvidia-ctk runtime configure --runtime=docker
Перезапустите демон Docker:
sudo systemctl restart docker
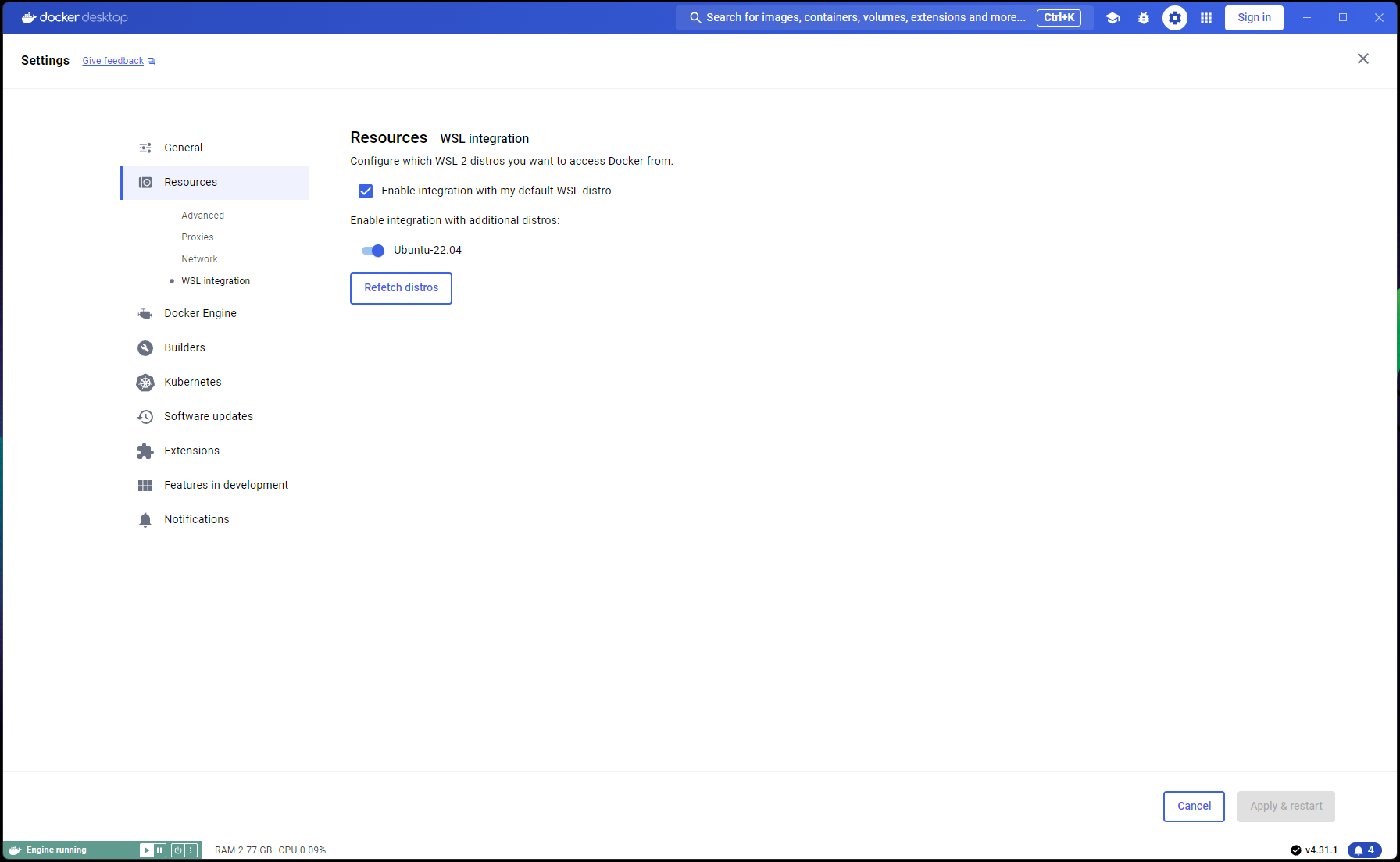
Теперь ваша установка Ubuntu завершена, пришло время завершить интеграцию WSL и Docker:
Откройте новое окно PowerShell и установите эту установку Ubuntu в качестве WSL по умолчанию:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Перейдите на Docker Desktop -> Settings -> Resources -> WSL Integration -> Проверить интеграцию по умолчанию и Ubuntu 22.04. См. скриншот ниже:
Теперь, если все сделано правильно, вы готовы собрать и запустить контейнер!
В командной строке/терминале выполните следующие команды:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
После этого перейдите по адресу http://localhost:5000/ в своем браузере и следуйте оставшейся части шагов первого запуска и руководства пользователя.
Разделы «Устранение неполадок» применимы и к Container-LARS.
Если вы столкнулись с ошибками, связанными с сетью, особенно в отношении недоступных репозиториев пакетов при сборке контейнера, это проблема с сетью на вашей стороне, часто связанная с проблемами брандмауэра.
В Windows перейдите в Control PanelSystem and SecurityWindows Defender FirewallAllowed apps или найдите Firewall в меню «Пуск» и выберите « Allow an app through the firewall и убедитесь, что ``Docker Desktop Backend`` разрешен через
При первом запуске LARS будет загружена модель внедрения преобразователей предложений.
В контейнерной среде эта загрузка иногда может быть проблематичной и приводить к ошибкам при запросе.
Если это произойдет, просто зайдите в меню настроек LARS: Settings->VectorDB & Embedding Models и измените модель внедрения на BGE-Base или BGE-Large, это приведет к перезагрузке и повторной загрузке.
После этого продолжайте задавать вопросы снова, и ответ должен появиться как обычно.
Вы можете вернуться к модели внедрения преобразователей предложений, и проблема должна быть решена.
Как указано выше в разделе «Устранение неполадок», модели внедрения загружаются при первом запуске LARS.
Лучше всего сохранить состояние контейнера перед его выключением, чтобы не повторять этот шаг загрузки при каждом последующем запуске контейнера.
Для этого откройте другую командную строку/терминал и зафиксируйте изменения ПЕРЕД закрытием работающего контейнера LARS:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
Это создаст обновленный образ, который вы сможете использовать при последующих запусках:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
ПРИМЕЧАНИЕ. Сделав вышеизложенное, если вы проверите пространство, используемое изображениями, с помощью docker images , вы заметите, что используется много места. НО, не воспринимайте размеры здесь буквально! Размер, отображаемый для каждого изображения, включает общий размер всех его слоев, но многие из этих слоев являются общими для разных изображений, особенно если эти изображения основаны на одном и том же базовом изображении или если одно изображение является зафиксированной версией другого. Чтобы узнать, сколько места на диске на самом деле используют ваши образы Docker, используйте:
docker system df
Вернуться к оглавлению
| Категория | Задачи | Статус |
|---|---|---|
| Исправления ошибок: | Опасность создания текстового файла с нулевым байтом. Иногда, если распознавание текста или извлечение текста из входного документа завершается неудачно, может остаться файл 0B .txt, что приводит к дальнейшим повторным попыткам полагать, что файл уже загружен. | ? Будущая задача |
| Практические особенности: | Основное внимание уделяется простоте использования: | |
| Переключатель пользовательского интерфейса бесплатного уровня Azure CV-OCR | ✅ Завершено 8 июня 2024 г. | |
| Удалить чаты | ? Будущая задача | |
| Переименовать чаты | ? Будущая задача | |
| Сценарий установки PowerShell | ? Будущая задача | |
| Скрипт установки Linux | ? Будущая задача | |
| Серверная часть Ollama для вывода LLM как альтернатива llama.cpp | ? Будущая задача | |
| Интеграция сервисов OCR от других облачных провайдеров (GCP, AWS, OCI и т. д.) | ? Будущая задача | |
| Переключатель пользовательского интерфейса, позволяющий игнорировать предыдущие извлечения текста при загрузке документа. | ? Будущая задача | |
| Модальное всплывающее окно для загрузки файлов: параметры зеркального извлечения текста из настроек, глобальная перезапись отправленных файлов, переключение для сохранения настроек. | ? Будущая задача | |
| Ориентированность на производительность: | ||
| Поддержка Nvidia TensorRT-LLM AWQ | ? Будущая задача | |
| Задачи исследования: | Изучите Nvidia TensorRT-LLM: требует создания TRT-движков AWQ-LLM, специфичных для целевого графического процессора, NvTensorRT-LLM представляет собой собственную экосистему и работает только на Python v3.10. | ✅ Завершено 13 июня 2024 г. |
| Локальное распознавание текста с Vision LLM: MS-TrOCR (выполнено), Космос-2.5 (высокий приоритет), Ллава, Флоренция-2 | ? В разработке Обновление от 5 июля 2024 г. | |
| Улучшения RAG: изменение рейтинга, RAPTOR, T-RAG. | ? Будущая задача | |
| Исследование интеграции GraphDB: использование LLM для извлечения данных о связях сущностей из документов, а также заполнения, обновления и обслуживания GraphDB. | ? Будущая задача |
Вернуться к оглавлению
Я надеюсь, что LARS помог вам в работе, и приглашаю вас поддержать его постоянное развитие! Если вы цените этот инструмент и хотите внести свой вклад в его будущие улучшения, рассмотрите возможность сделать пожертвование. Ваша поддержка помогает мне продолжать совершенствовать LARS и добавлять новые функции.
Как сделать пожертвование Чтобы сделать пожертвование, воспользуйтесь следующей ссылкой на мой PayPal:
Пожертвовать через PayPal
Ваш вклад очень ценен и будет использован для финансирования дальнейших усилий по развитию.
Вернуться к оглавлению


