cambrian
1.0.0
Интересный факт: зрение появилось у животных в кембрийский период! Это послужило вдохновением для названия нашего проекта «Кембрий».
eval/ .dataengine/ .В настоящее время мы поддерживаем обучение ТПУ с использованием TorchXLA.
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " Вот наши кембрийские контрольные точки вместе с инструкциями по использованию гирь. Наши модели превосходны в различных измерениях на уровнях параметров 8B, 13B и 34B. Они демонстрируют конкурентоспособную производительность по сравнению с проприетарными моделями с закрытым исходным кодом, такими как GPT-4V, Gemini-Pro и Grok-1.4V, в нескольких тестах.
| Модель | #Вис. Ток. | ММБ | СКА-I | MathVistaM | ЧартQA | ММВП |
|---|---|---|---|---|---|---|
| ГПТ-4В | УНК | 75,8 | - | 49,9 | 78,5 | 50,0 |
| Близнецы-1.0 Про | УНК | 73,6 | - | 45,2 | - | - |
| Близнецы-1,5 Про | УНК | - | - | 52,1 | 81,3 | - |
| Грок-1,5 | УНК | - | - | 52,8 | 76,1 | - |
| ММ-1-8Б | 144 | 72,3 | 72,6 | 35,9 | - | - |
| ММ-1-30Б | 144 | 75,1 | 81,0 | 39,4 | - | - |
| Базовый LLM: Фи-3-3.8B | ||||||
| Кембрий-1-8Б | 576 | 74,6 | 79,2 | 48,4 | 66,8 | 40,0 |
| Базовый LLM: LLaMA3-8B-Instruct. | ||||||
| Мини-Близнецы-HD-8B | 2880 | 72,7 | 75,1 | 37,0 | 59,1 | 18,7 |
| ЛЛаВА-NeXT-8B | 2880 | 72,1 | 72,8 | 36,3 | 69,5 | 38,7 |
| Кембрий-1-8Б | 576 | 75,9 | 80,4 | 49,0 | 73,3 | 51,3 |
| Базовый LLM: Викуна1.5-13B | ||||||
| Мини-Джемини-HD-13B | 2880 | 68,6 | 71,9 | 37,0 | 56,6 | 19,3 |
| ЛЛаВА-NeXT-13B | 2880 | 70,0 | 73,5 | 35,1 | 62,2 | 36,0 |
| Кембрий-1-13Б | 576 | 75,7 | 79,3 | 48,0 | 73,8 | 41,3 |
| База LLM: Гермес2-Йи-34Б | ||||||
| Мини-Джемини-HD-34Б | 2880 | 80,6 | 77,7 | 43,4 | 67,6 | 37,3 |
| ЛЛаВА-NeXT-34B | 2880 | 79,3 | 81,8 | 46,5 | 68,7 | 47,3 |
| Кембрий-1-34Б | 576 | 81,4 | 85,6 | 53,2 | 75,6 | 52,7 |
Полную таблицу можно найти в нашей статье «Кембрий-1».
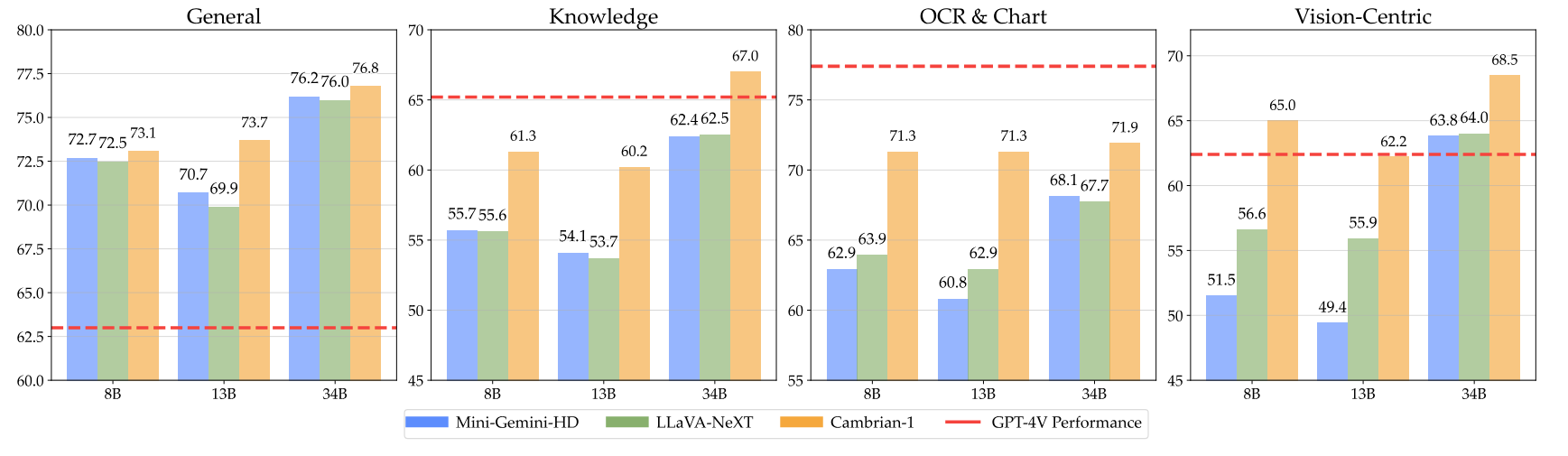
Наши модели предлагают высококонкурентную производительность при использовании меньшего фиксированного количества визуальных токенов.
Чтобы использовать веса моделей, загрузите их с Hugging Face:
Мы предоставляем пример сценария загрузки и генерации модели в inference.py .

В этой работе мы собираем очень большой пул данных по настройке инструкций Cambrian-10M для нас и будущей работы по изучению данных при обучении MLLM. В нашем предварительном исследовании мы фильтруем данные до высококачественного набора курируемых 7M точек данных, который мы называем кембрий-7M. Оба этих набора данных доступны в следующем наборе данных Hugging Face: Cambrian-10M.
Мы собрали разнообразные данные по настройке визуальных инструкций из различных источников, включая VQA, визуальный диалог и воплощенное визуальное взаимодействие. Чтобы обеспечить высококачественные, надежные и крупномасштабные данные знаний, мы разработали Internet Data Engine.
Кроме того, мы заметили, что данные VQA имеют тенденцию генерировать очень короткие выходные данные, что приводит к сдвигу распределения обучающих данных. Чтобы решить эту проблему, мы использовали GPT-4v и GPT-4o для создания расширенных ответов и более креативных данных.
Чтобы решить проблему неадекватности научных данных, мы разработали Internet Data Engine для сбора надежных научных данных VQA. Этот движок можно применять для сбора данных по любой теме. Используя этот движок, мы собрали дополнительные 161 тысячу точек данных по настройке визуальных инструкций, связанных с наукой, увеличив общий объем данных в этой области на 400 %! Если вы хотите использовать эту часть данных, используйте этот jsonl.
Мы использовали GPT-4v для создания дополнительных 77 тысяч точек данных. Эти данные либо используют GPT-4v для перезаписи исходного VQA только для ответов в более длинные ответы с более подробными ответами, либо генерируют данные настройки визуальных инструкций на основе данного изображения. Если вы хотите использовать эту часть данных, используйте этот jsonl.
Мы использовали GPT-4o для создания дополнительных 60 тысяч точек данных объявлений. Эти данные побуждают модель генерировать очень длинные ответы и часто содержат очень творческие вопросы, такие как написание стихотворения, сочинение песни и многое другое. Если вы хотите использовать эту часть данных, используйте этот jsonl.
Мы провели первоначальное исследование по курированию данных:
Эмпирически мы обнаружили, что этот параметр
| Категория | Соотношение данных |
|---|---|
| Язык | 21,00% |
| Общий | 34,52% |
| оптическое распознавание символов | 27,22% |
| Подсчет | 8,71% |
| Математика | 7,20% |
| Код | 0,87% |
| Наука | 0,88% |
По сравнению с предыдущей моделью LLaVA-665K масштабирование и улучшенное управление данными значительно повышают производительность модели, как показано в таблице ниже:
| Модель | Средний | Общие знания | оптическое распознавание символов | Диаграмма | Ориентированное на видение |
|---|---|---|---|---|---|
| ЛЛаВА-665К | 40,4 | 64,7 | 45,2 | 20,8 | 31,0 |
| Кембрий-10М | 53,8 | 68,7 | 51,6 | 47,1 | 47,6 |
| Кембрий-7М | 54,8 | 69,6 | 52,6 | 47,3 | 49,5 |
Хотя обучение с помощью Cambrian-7M обеспечивает конкурентоспособные результаты тестов, мы заметили, что модель имеет тенденцию выдавать более короткие ответы и действовать как машина вопросов и ответов. Такое поведение, которое мы называем феноменом «автоответчика», может ограничить полезность модели в более сложных взаимодействиях.
Мы обнаружили, что добавление системной подсказки, например «Ответьте на вопрос, используя одно слово или фразу». может помочь смягчить проблему. Этот подход побуждает модель давать такие краткие ответы только тогда, когда это соответствует контексту. Для получения более подробной информации, пожалуйста, обратитесь к нашей статье.
Мы также подготовили набор данных Cambrian-7M с системной подсказкой, которая включает в себя системную подсказку для расширения творческих способностей модели и возможности общения в чате.
Ниже представлена последняя конфигурация обучения для кембрия-1.
В статье «Кембрий-1» мы проводим обширные исследования, чтобы продемонстрировать необходимость двухэтапного обучения. Обучение «Кембрий-1» состоит из двух этапов:
Кембрий-1 обучается на TPU-V4-512, но также может обучаться на TPU, начиная с TPU-V4-64. Код обучения графического процессора будет выпущен в ближайшее время. Для обучения графического процессора на меньшем количестве графических процессоров уменьшите per_device_train_batch_size и увеличьте gradient_accumulation_steps соответственно, гарантируя, что глобальный размер пакета останется прежним: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
Оба гиперпараметра, используемые при предварительном обучении и точной настройке, представлены ниже.
| База LLM | Глобальный размер пакета | Скорость обучения | Скорость обучения SVA | Эпохи | Максимальная длина |
|---|---|---|---|---|---|
| ЛЛаМА-3 8Б | 512 | 1е-3 | 1e-4 | 1 | 2048 |
| Викунья-1,5 13Б | 512 | 1е-3 | 1e-4 | 1 | 2048 |
| Гермес Йи-34Б | 1024 | 1е-3 | 1e-4 | 1 | 2048 |
| База LLM | Глобальный размер пакета | Скорость обучения | Эпохи | Максимальная длина |
|---|---|---|---|---|
| ЛЛаМА-3 8Б | 512 | 4e-5 | 1 | 2048 |
| Викунья-1,5 13Б | 512 | 4e-5 | 1 | 2048 |
| Гермес Йи-34Б | 1024 | 2е-5 | 1 | 2048 |
Для точной настройки инструкций мы провели эксперименты, чтобы определить оптимальную скорость обучения для обучения нашей модели. Основываясь на наших выводах, мы рекомендуем использовать следующую формулу для корректировки скорости обучения в зависимости от доступности вашего устройства:
optimal lr = base_lr * sqrt(bs / base_bs)
Чтобы получить базовый LLM и обучить модели 8B, 13B и 34B:
Мы используем комбинацию данных выравнивания LLaVA, ShareGPT4V, Mini-Gemini и ALLaVA для предварительной подготовки нашего визуального коннектора (SVA). В Кембрии-1 мы проводим обширные исследования, чтобы продемонстрировать необходимость и преимущества использования дополнительных данных выравнивания.
Для начала посетите нашу страницу данных выравнивания «Обнимающее лицо» для получения более подробной информации. Скачать данные выравнивания можно по следующим ссылкам:
Мы предоставляем примеры сценариев обучения на следующих языках:
Если вы хотите обучаться с использованием других источников данных или пользовательских данных, мы поддерживаем широко используемый формат данных LLaVA. Для обработки очень больших файлов мы используем формат JSONL вместо формата JSON для отложенной загрузки данных, чтобы оптимизировать использование памяти.
Как и в случае с тренировочным SVA, посетите наши данные Cambrian-10M для получения более подробной информации о данных настройки инструкций.
Мы предоставляем примеры сценариев обучения на следующих языках:
--mm_projector_type : чтобы использовать наш модуль SVA, установите для этого значения значение sva . Чтобы использовать двухслойный проектор MLP в стиле LLaVA, установите для этого значения значение mlp2x_gelu .--vision_tower_aux_list : список используемых моделей машинного зрения (например '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : список количества жетонов видения для каждой башни видения; каждое число должно быть квадратным (например '[576, 576, 576, 9216]' ). Карта объектов каждой обзорной башни будет интерполирована для удовлетворения этого требования.--image_token_len : окончательное количество токенов видения, которое будет предоставлено LLM; число должно быть квадратным (например, 576 ). Обратите внимание: если mm_projector_type имеет значение mlp, каждое число в vision_tower_aux_token_len_list должно совпадать с image_token_len . Приведенные ниже аргументы имеют смысл только для проектора SVA.--num_query_group : значение G для модуля SVA.--query_num_list : список номеров запросов для каждой группы запросов в SVA (например '[576]' ). Длина списка должна быть равна num_query_group .--connector_depth : значение D для модуля SVA.--vision_hidden_size : скрытый размер модуля SVA.--connector_only : Если установлено значение true, модуль SVA будет отображаться только перед LLM, в противном случае он будет вставлен внутрь LLM несколько раз. Следующие три аргумента имеют смысл только в том случае, если для него установлено значение False .--num_of_vision_sampler_layers : общее количество модулей SVA, вставленных в LLM.--start_of_vision_sampler_layers : индекс слоя LLM, после которого начинается вставка SVA.--stride_of_vision_sampler_layers : шаг вставки модуля SVA внутри LLM. Мы разместили наш оценочный код в подпапке eval/ . Пожалуйста, ознакомьтесь с README там для более подробной информации.
Следующие инструкции помогут вам запустить локальную демо-версию Gradio с помощью Cambrian. Мы предоставляем простой веб-интерфейс для взаимодействия с моделью. Вы также можете использовать CLI для вывода. Эта установка во многом вдохновлена LLaVA.
Пожалуйста, следуйте инструкциям ниже, чтобы запустить локальную демо-версию Gradio. Схема местного кода обслуживания находится ниже 1 .
%%{init: {"theme": "base"}}%%
блок-схема БТ
%% Объявить узлы
стиль заливки gws: # f9f, обводка: # 333, ширина обводки: 2 пикселя
стиль c заливка:#bbf,обводка:#333,ширина обводки:2px
стиль mw8b fill:#aff,stroke:#333,stroke-width:2px
стиль mw13b fill:#aff,stroke:#333,stroke-width:2px
%% стиль sglw13b fill:#ffa,stroke:#333,stroke-width:2px
%% стиль lsglw13b fill:#ffa,stroke:#333,stroke-width:2px
gws["Градио (сервер пользовательского интерфейса)"]
c["Контроллер (API-сервер):<br/>ПОРТ: 10000"]
mw8b["Модель Worker:<br/><b>Cambrian-1-8B</b><br/>ПОРТ: 40000"]
mw13b["Модель Worker:<br/><b>Cambrian-1-13B</b><br/>ПОРТ: 40001"]
%% sglw13b["Бэкэнд SGLang:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["Рабочий SGLang:<br/><b>Cambrian-1-34B<b><br/>ПОРТ: 40002"]
подграф «Демо-архитектура»
направление БТ
с <--> gws
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
конец
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadВы только что запустили веб-интерфейс Gradio. Теперь вы можете открыть веб-интерфейс с URL-адресом, напечатанным на экране. Вы можете заметить, что в списке моделей нет модели. Не волнуйтесь, мы еще не запустили ни одну рабочую модель. Он будет автоматически обновляться при запуске рабочей модели.
Вскоре.
Это фактический исполнитель , который выполняет вывод на графическом процессоре. Каждый рабочий отвечает за одну модель, указанную в --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bПодождите, пока процесс загрузит модель и вы увидите «Uvicorn работает на…». Теперь обновите веб-интерфейс Gradio, и вы увидите только что запущенную модель в списке моделей.
Вы можете запустить столько воркеров, сколько захотите, и сравнить контрольные точки разных моделей в одном интерфейсе Gradio. Пожалуйста, оставьте --controller прежним и измените --port и --worker указав разные номера портов для каждого работника.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> Если вы используете устройство Apple с чипом M1 или M2, вы можете указать устройство mps, используя флаг --device : --device mps .
Если объем видеопамяти вашего графического процессора меньше 24 ГБ (например, RTX 3090, RTX 4090 и т. д.), вы можете попробовать запустить его с несколькими графическими процессорами. Наша последняя база кода автоматически попытается использовать несколько графических процессоров, если у вас более одного графического процессора. Вы можете указать, какие графические процессоры использовать, с помощью CUDA_VISIBLE_DEVICES . Ниже приведен пример работы с первыми двумя графическими процессорами.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTODO
Если вы считаете кембрийский период полезным для ваших исследований и приложений, пожалуйста, цитируйте его с помощью этого BibTeX:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
Уведомления об использовании и лицензии : В этом проекте используются определенные наборы данных и контрольные точки, на которые распространяются соответствующие оригинальные лицензии. Пользователи должны соблюдать все положения и условия этих исходных лицензий, включая, помимо прочего, Условия использования OpenAI для набора данных и специальные лицензии для моделей базового языка для контрольных точек, обученных с использованием набора данных (например, лицензия сообщества Llama для LLaMA-3, и Викунья-1,5). Этот проект не накладывает никаких дополнительных ограничений, кроме тех, которые предусмотрены исходными лицензиями. Кроме того, пользователям напоминают, что они должны убедиться, что использование ими набора данных и контрольных точек соответствует всем применимым законам и правилам.
Скопировано из диаграммы LLaVA. ↩


