llm chatbot rag
1.0.0
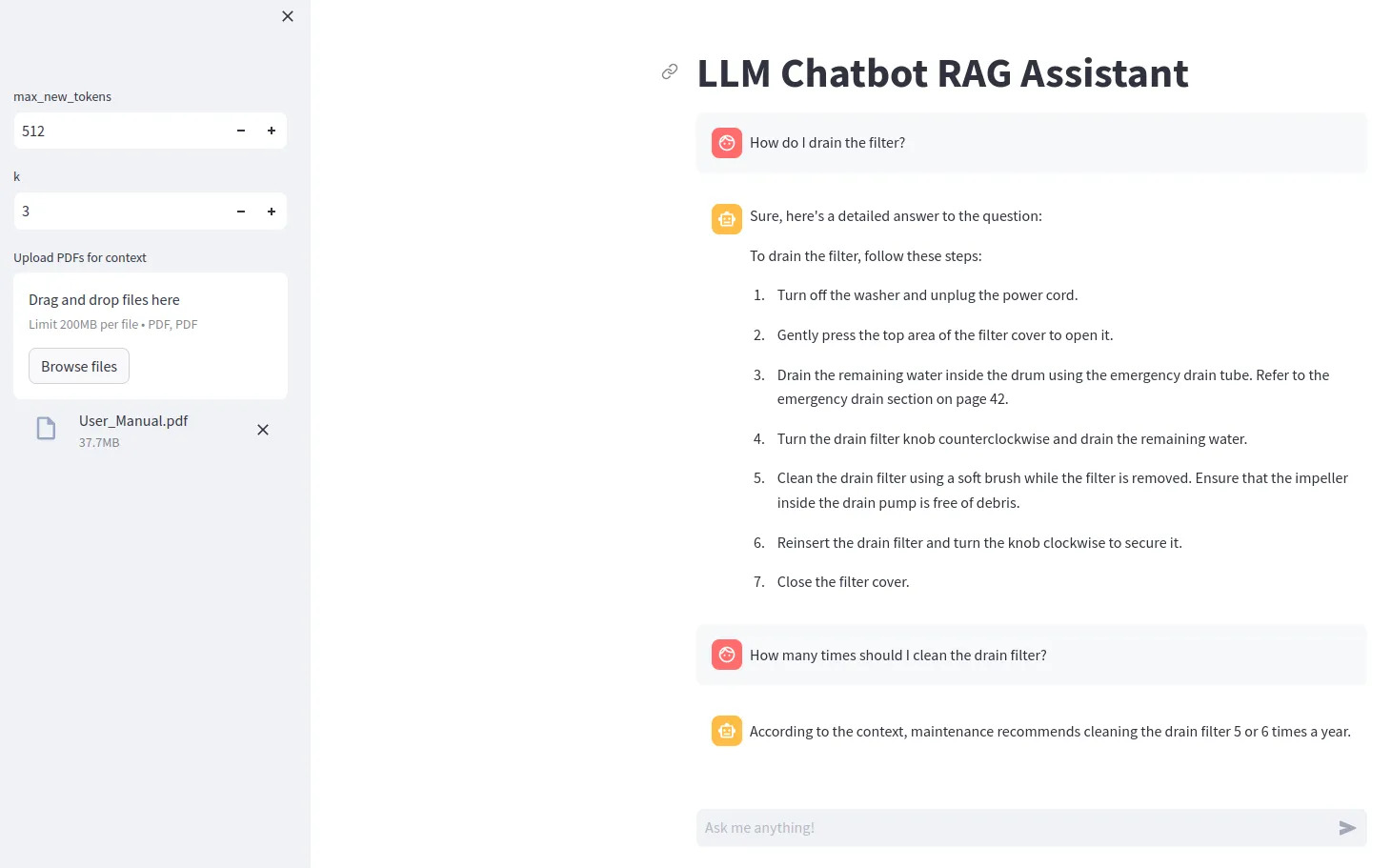
Чтобы использовать определенные модели LLM (например, Gemma), вам необходимо создать файл .env, содержащий строку ACCESS_TOKEN=<your hugging face token>
Установите зависимости с помощью pip install -r requirements.txt
Запустите с помощью streamlit run src/app.py
Для использования квантования битов и байтов требуется графический процессор Nvidia. Обязательно сначала установите NVIDIA Toolkit, а затем PyTorch.
Вы можете проверить, доступен ли ваш графический процессор в Python с помощью
import torch
print(torch.cuda.is_available())
Если у вас нет совместимого графического процессора, попробуйте установить для модели device="cpu" и удалите конфигурацию квантования.


