Synonyms
Synonyms
Китайские синонимы обработки и понимания естественного языка.
Лучшие китайские синонимы: чат-бот, интеллектуальный набор вопросов и ответов.
synonyms можно использовать для многих задач по пониманию естественного языка: выравнивание текста, алгоритмы рекомендаций, вычисления сходства, семантическое смещение, извлечение ключевых слов, извлечение понятий, автоматическое обобщение, поисковые системы и т. д.
Чтобы предоставлять стабильные, надежные и долгосрочные оптимизированные услуги, компания Synonyms перешла на использование лицензии Chunsong версии 1.0 и взимает плату за загрузку моделей машинного обучения. Подробную информацию см. в хранилище сертификатов. Предыдущие участники (соавторы кода, внесшие выдающийся вклад) могут связаться с нами, чтобы обсудить вопросы взимания платы. -- Chatopera Inc., октябрь 2023 г.
Следуйте инструкциям ниже, чтобы установить и активировать пакеты.
pip install -U synonymsТекущая стабильная версия — v3.x.
Для пакетов моделей машинного обучения Synonyms требуется лицензия в магазине лицензий Chatopera. Сначала приобретите лицензию и получите license id на странице «Лицензии» в магазине лицензий Chatopera ( license id : в хранилище сертификатов на странице сведений о сертификате нажмите [Копировать Сертификат удостоверения]).
Во-вторых, установите переменную среды в скриптах терминала или оболочки, как показано ниже.
например, Shell, сценарии CMD в Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Блокнот Jupyter и т. д.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )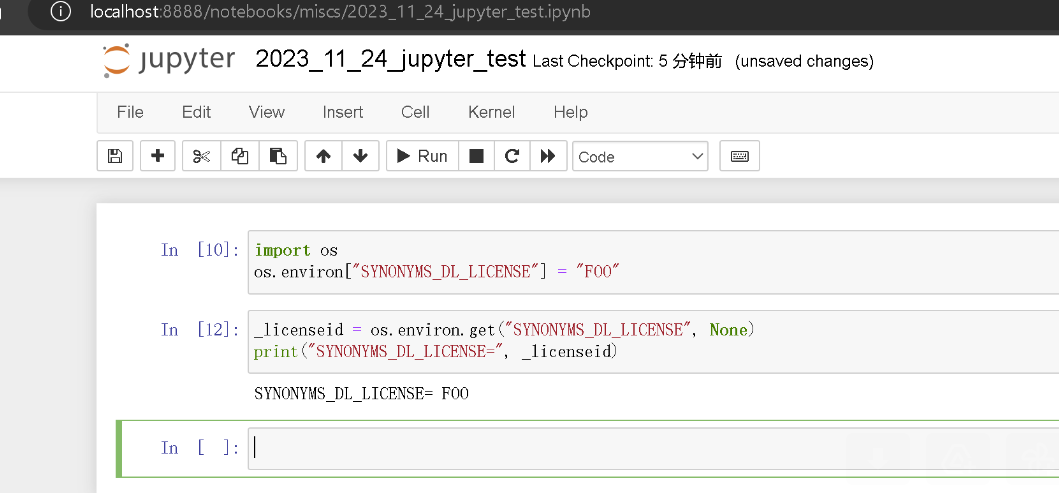
Совет: Файл векторного слова будет загружен в первый раз после установки, а скорость загрузки зависит от условий сети.
Наконец, загрузите пакет модели командой или скриптом —
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Поддерживает использование переменных среды для настройки словаря сегментации слов и файлов векторов слов word2vec.
| переменные среды | описывать |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Векторный файл Word, обученный с использованием word2vec, двоичный формат. |
| SYNONYMS_WORDSEG_DICT | Главный словарь сегментации китайских слов, справочник по формату и использованию |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"], выводить ли журналы отладки, установлено значение "TRUE", значение по умолчанию - "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) возвращает кортеж. nearby_words содержит два элемента: ([nearby_words], [nearby_words_score]) . Расстояние расположено от ближнего к дальнему. nearby_words_score — это оценка расстояния между словами в соответствующей позиции в nearby_words . Чем ближе она к 1, тем ближе она к SIZE — количеству возвращаемых слов; значение по умолчанию — 10. например:
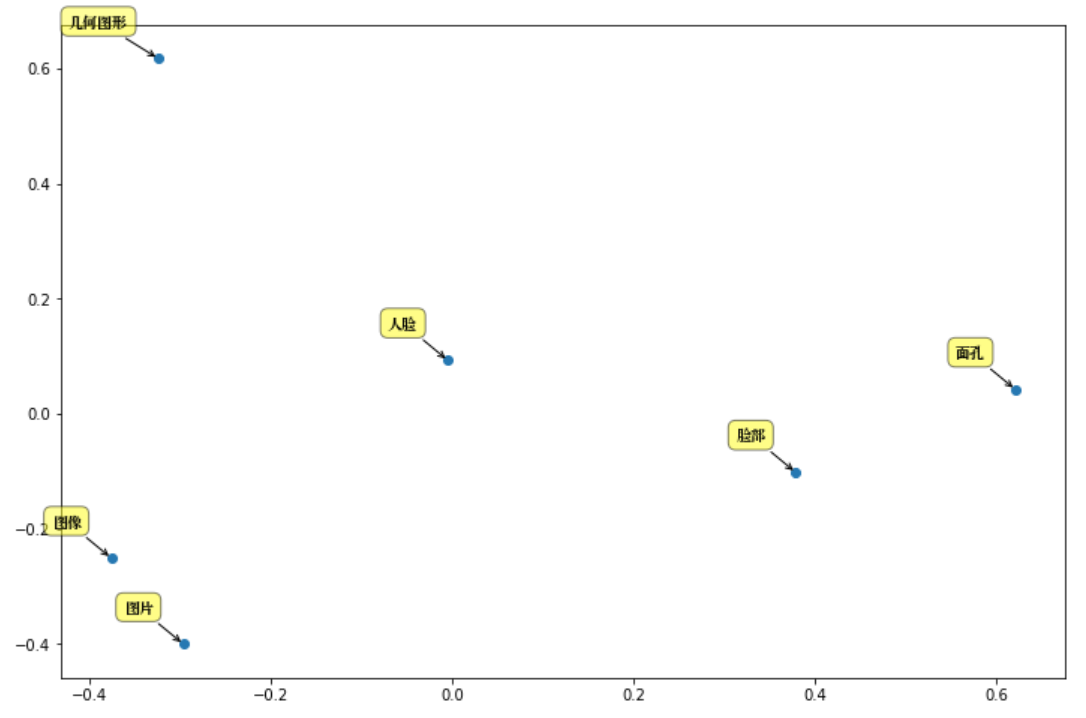
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) В случае OOV возвращается ([], []) , текущий размер словаря: 435 729.
Сравнение сходства двух предложений
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Среди них параметр seg указывает, выполняет ли синонимы.compare сегментацию слов на sen1 и sen2, а значение по умолчанию — True. Возвращаемое значение: [0-1], и чем оно ближе к 1, тем более похожи два предложения.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Вывод синонимов удобным способом для облегчения отладки. display(WORD [, SIZE]) вызывает метод synonyms#nearby .
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE — количество печатных списков словаря, по умолчанию — 10.
Распечатайте описание текущего пакета:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Получите вектор слов, который представляет собой массив NumPy. Если слово является незарегистрированным, выдается исключение KeyError.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Получите вектор предложения после сегментации слова. Вектор составляется в режиме BoW.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Сегментация китайских слов
synonyms . seg ( "中文近义词工具包" )Результатом сегментации слов является кортеж, состоящий из двух списков, которые представляют собой слова и соответствующие им части речи.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])Это причастие не удаляет стоп-слова и знаки препинания.
Извлечение ключевых слов По умолчанию ключевые слова извлекаются по важности.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Получите больше журналов для отладки, установите переменную среды.
SYNONYMS_DEBUG=TRUE
На примере «человеческого лица» проанализируем основные компоненты:
$ pip install -r Requirements.txt
$ python demo.pyОбновленное заявление о статусе.
Что говорят пользователи:
данные построены на основе корпуса викиданных.
«Синонимы Ци Линь» были составлены Мэй Цзяцзюй и другими в 1983 году. В настоящее время широко используемой версией является «Расширенное издание синонимов Ци Линь», поддерживаемое Исследовательским центром социальных вычислений и поиска информации Харбинского технологического института. Оно четко разделяет китайскую лексику. на крупные категории и подкатегории выясняют отношения между словами. Расширенная версия Synonyms Cilin содержит более 70 000 слов, из которых более 30 000 опубликованы в виде открытых данных.
HowNet, также известный как HowNet, — это не просто семантический словарь, а система знаний. Отношения между словами — один из основных сценариев его использования. CNKI содержит более 8 слов.
Международный стандарт оценки алгоритмов сходства слов обычно принимает значение ручной оценки набора пар английских слов, опубликованное Miller&Charles. Набор пар слов состоит из десяти пар высокородственных, десяти пар среднеродственных и десяти пар слабородственных пар английских слов, а затем 38 испытуемых просят оценить семантическую релевантность этих 30 пар и, наконец, принять среднее значение. значение служит ручным критерием. Затем различные инструменты синонимов также оценивают сходство этих слов и сравнивают их с критериями ручной оценки, такими как использование коэффициента корреляции Пирсона. В китайской сфере также распространен метод использования переведенной версии этого словарного списка для сравнения китайских синонимов.
Емкость словарного списка синонимов составляет 435 729. Ниже мы выбираем несколько слов, которые существуют в синонимах Cilin, CNKI и Synonyms, чтобы сравнить их сходство:
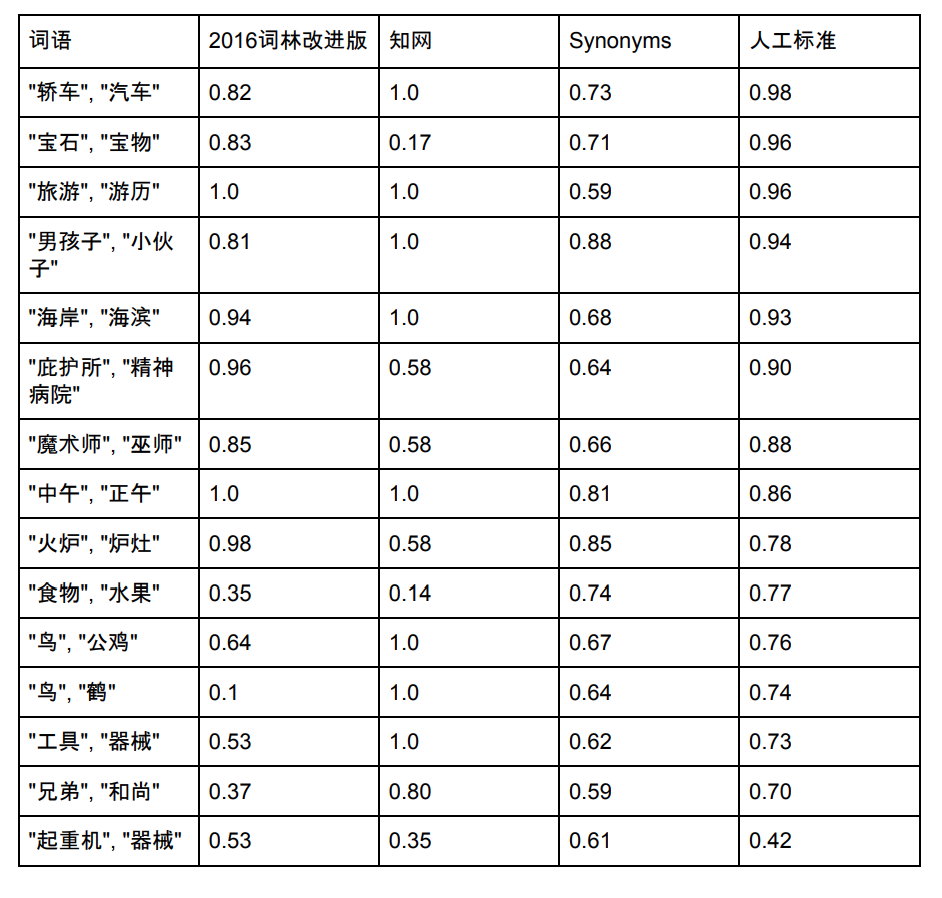
Примечание. Источники данных и оценок Synonym Forest и CNKI. Синонимы также постоянно оптимизируются, и новые оценки могут не соответствовать картинке выше.
Дополнительные результаты сравнения.
Список пользователей, связанных с Github
Протестируйте с py3, MacBook Pro.
python benchmark.py
++++++++++ Название и версия ОС ++++++++++
Платформа: Дарвин
Ядро: 16.7.0
Архитектура: ('64bit', '')
++++++++++ Ядра процессора ++++++++++
Ядра: 4
Загрузка процессора: 60
++++++++++ Системная память ++++++++++
меминформация 8 ГБ
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Сердце машины
Запись для обмена в Интернете: Синонимы, набор инструментов для китайских синонимов @ 07.02.2018
Synonyms публикует сертификат MIT. Данные и процедуры могут использоваться в исследовательских и коммерческих продуктах и должны цитироваться и упоминаться, например, в любых публикуемых средствах массовой информации, журналах, журналах или блогах.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
Корпус Викиданных
Вывод принципа word2vec и анализ кода
Не поддерживается, см. № 5 для получения дополнительной информации.
Word2vec, выпущенный Google, эта библиотека написана на языке C, имеет высокую эффективность использования памяти и быструю скорость обучения. gensim может загружать файлы моделей, выводимые word2vec.
Подробности см. в №64.
Хай Лян Ван
Ху Инси
Эта книга написана в соавторстве с авторами Synonyms.
Ссылка для быстрой покупки книги 
«Интеллектуальный ответ на вопросы и глубокое обучение» Эта книга предназначена для студентов и инженеров-программистов, которые готовятся начать работу с машинным обучением и обработкой естественного языка. В ней представлены многие теоретические принципы и алгоритмы, а также представлено множество примеров программ для повышения практичности. приведены в библиотеке примеров программного кода. Эти программы в основном предназначены для того, чтобы помочь каждому понять принципы и алгоритмы. Вы можете загрузить и выполнить их. Адрес базы кода:
https://github.com/l11x0m7/book-of-qna-code
Word2vec от Google
Викимедиа: источник учебного корпуса
Генсим: word2vec.py
SentenceSim: корпус оценки сходства
джиеба: сегментация китайских слов
Публичная лицензия Чунсонг, версия 1.0
https://bot.chatopera.com/
Облачный сервис Chatopera — это универсальный облачный сервис для внедрения чат-роботов, оплата которого осуществляется в зависимости от количества вызовов интерфейса. Chatopera Cloud Service — это экземпляр бот-платформы Chatopera, работающий по принципу «программное обеспечение как услуга». Облачный сервис Chatopera, основанный на облачных вычислениях, представляет собой облачный сервис чат-бот как услуга .
Роботизированная платформа Chatopera включает в себя такие компоненты, как база знаний, многораундовый диалог, распознавание намерений и распознавание речи, стандартизированную разработку чат-роботов и поддерживает такие сценарии, как интеллектуальные вопросы и ответы корпоративного OA, интеллектуальные вопросы и ответы для HR, интеллектуальное обслуживание клиентов и онлайн-маркетинг. Корпоративные ИТ-отделы и бизнес-отделы используют облачные сервисы Chatopera для быстрого подключения чат-ботов к сети!


