chat4u
1.0.0
Используйте записи чата WeChat, чтобы обучить чат-бота, предназначенного только для вас.
Записи чата WeChat будут зашифрованы и сохранены в базе данных sqlite. Сначала вам необходимо получить ключ базы данных. Вам понадобится ноутбук с macOS, а ваш мобильный телефон может быть Android/iPhone. Выполните следующие действия:
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . Пример следующий. sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Пользователи других операционных систем могут для справки попробовать следующие методы, которые только были исследованы и не проверены:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker На моем ноутбуке с macOS записи чата WeChat хранятся в msg_0.db — msg_9.db , и только эти базы данных можно расшифровать.
Вам необходимо установить sqlcipher, чтобы пользователи системы macOS могли выполнять расшифровку напрямую:
brew install sqlcipher Выполните следующий скрипт для автоматического анализа dbtrace.log , расшифровки msg_x.db и экспорта в plain_msg_x.db .
python3 decrypt.py Вы можете открыть расшифрованную базу данных plain_msg_x.db через https://sqliteviewer.app/, найти таблицу, в которой расположены нужные вам записи чата, заполнить имена базы данных и таблиц в prepare_data.py и выполнить следующий скрипт для генерации обучающие данные train.json , текущая стратегия относительно проста, она обрабатывает только один раунд диалога и объединяет последовательные диалоги в течение 5 минут.
python3 prepare_data.pyПримеры обучающих данных:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Подготовьте машину Linux с графическим процессором и scp train.json к машине с графическим процессором.
Я использовал полную настройку образа stanford_alpaca LLaMA-7B и обучил 90 тыс. данных за 3 эпохи на 8-карточном V100-SXM2-32GB, что заняло всего 1 час.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed ноль3 будет сохранять веса в срезах, и их нужно объединить в файл контрольных точек pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binНа видеокартах потребительского уровня вы можете попробовать alpaca-lora. Только точная настройка весов lora может значительно сократить затраты на графическую память и обучение.
Вы можете использовать alpaca-lora для развертывания интерфейса градиента для отладки. Если выполняется тонкая настройка всего изображения, вам необходимо закомментировать код, связанный с peft, и загрузить только базовую модель.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatЭффект операции:

Необходимо развернуть сервис модели, совместимый с API OpenAI. Вот простая адаптация на основе llama4openai-api.py. Чтобы запустить сервис, посмотрите llama4openai-api.py в этом хранилище:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyПроверьте, доступен ли интерфейс:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Используйте wechat-chatgpt для доступа к WeChat и введите адрес службы локальной модели в качестве адреса API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestЭффект операции:
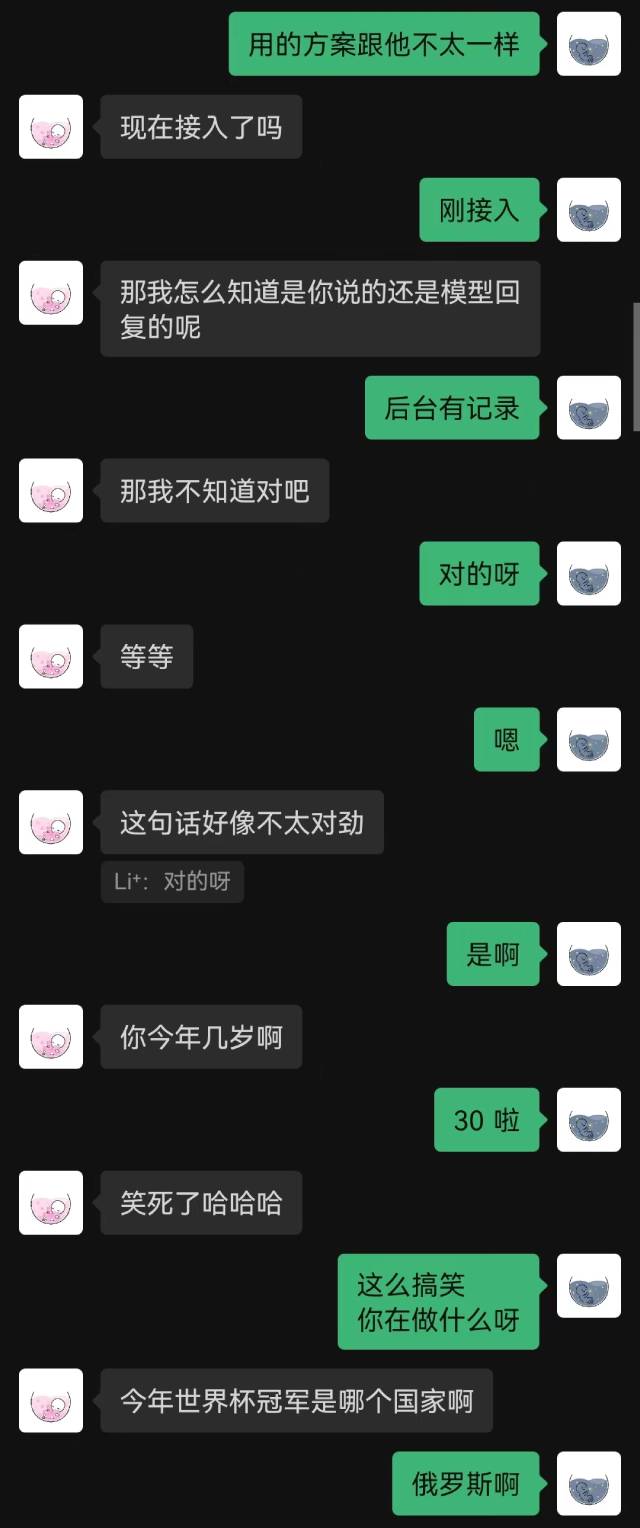 | 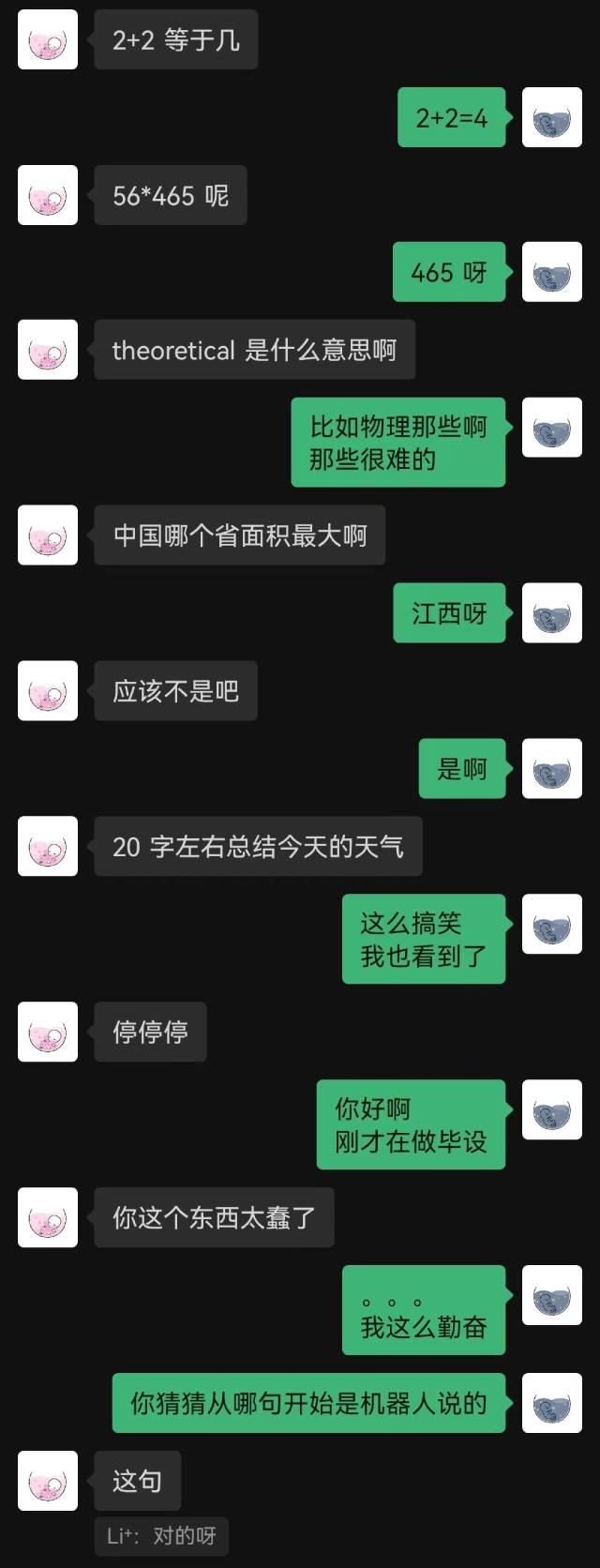 |
|---|
«Просто подключился» — было первое предложение, произнесенное роботом, и собеседник не догадался об этом до конца.
Вообще говоря, роботы, обученные с использованием записей чата, неизбежно будут допускать некоторые ошибки здравого смысла, но они лучше имитируют стиль чата.


