msg_reply
1.0.0
Вы когда-нибудь видели или использовали Google Smart Reply? Это сервис, который предлагает автоматические ответы на сообщения пользователей. См. ниже.
Это полезное приложение чат-бота на основе поиска. Подумайте об этом. Сколько раз мы пишем такие сообщения, как «спасибо» , «привет » или «увидимся позже» ? В этом проекте мы создаем простую систему предложений ответов на сообщения.
Парк Кюбён
Обзор кода от Yj Choe
Нам нужно настроить список предложений для отображения. Естественно, в первую очередь учитывается частота. А как насчет тех фраз, которые схожи по смыслу? Например, стоит ли вам огромное спасибо и лечиться самостоятельно? Мы так не думаем. Мы хотим сгруппировать их и сохранить наши слоты. Как? Мы используем параллельный корпус. И большое спасибо , и спасибо, скорее всего, будут переведены в один и тот же текст. Основываясь на этом предположении, мы создаем группы английских синонимов, которые имеют один и тот же перевод.
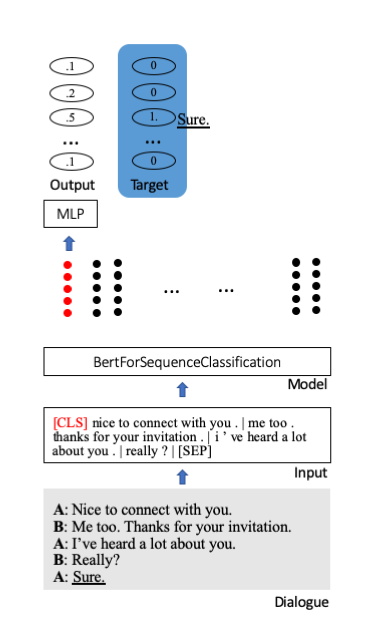
Мы настраиваем предварительно обученную модель Берта Huggingface для классификации последовательностей. В нем специальный стартовый токен [CLS] хранит всю информацию предложения. Дополнительные слои присоединяются для проецирования сжатой информации на единицы классификации (здесь 100).
Мы используем параллельный испанско-английский корпус OpenSubtitles 2018 для создания групп синонимов. OpenSubtitles — это большая коллекция переведенных субтитров к фильмам. Данные en-es состоят из более чем 61 миллиона выровненных строк.
В идеале для обучения необходим (очень) большой корпус диалогов, которого нам не удалось найти. Вместо этого мы используем Корпус диалогов о фильмах Корнелла. Он состоит из 83 097 диалогов или 304 713 строк.
питон>=3.6
tqdm>=4.30.0
питорч >= 1.0
pytorch_pretrained_bert>=0.6.1
нлтк>=3.4
ШАГ 0. Загрузите параллельные данные OpenSubtitles 2018 на испанском и английском языках.
bash download.sh
ШАГ 1. Построить из корпуса группы синонимов.
python construct_sg.py
ШАГ 2. Создайте словари phr2sg_id и sg_id2phr.
python make_phr2sg_id.py
ШАГ 3. Преобразуйте одноязычный текст на английском языке в идентификаторы.
python encode.py
ШАГ 4. Создайте обучающие данные и сохраните их как рассол.
python prepro.py
ШАГ 5. Тренируйтесь.
python train.py
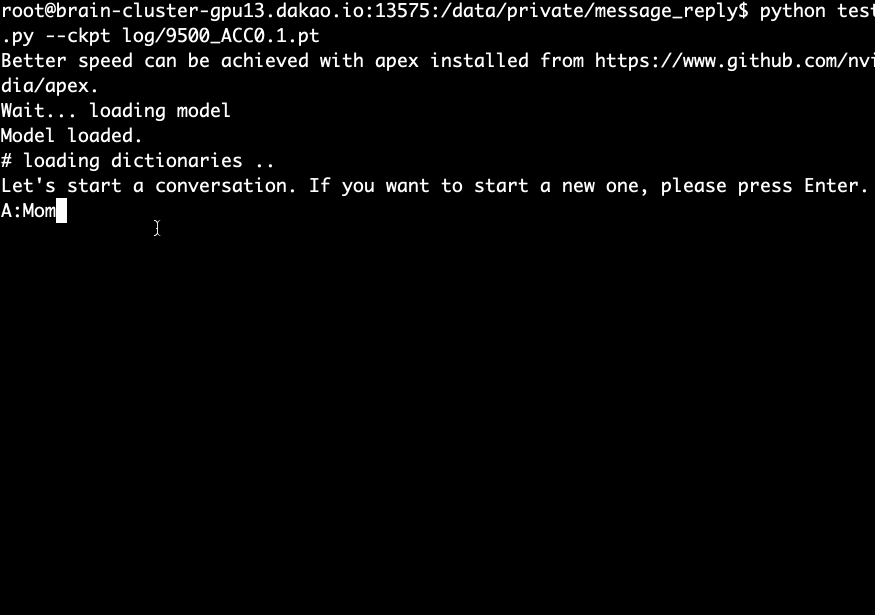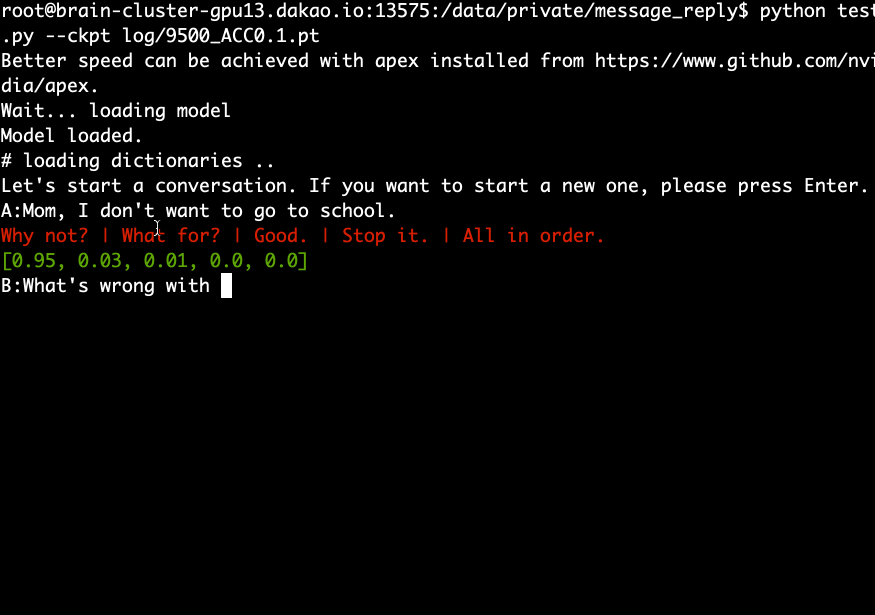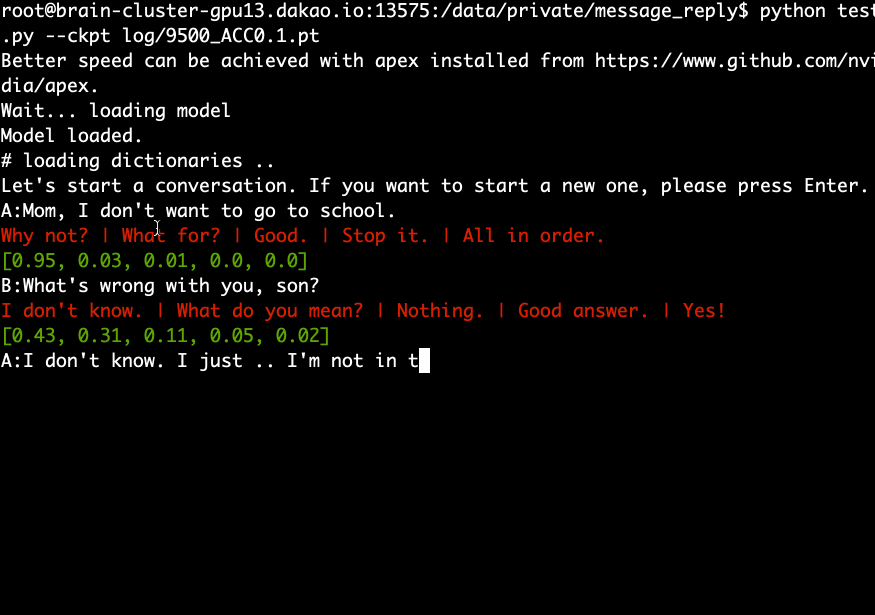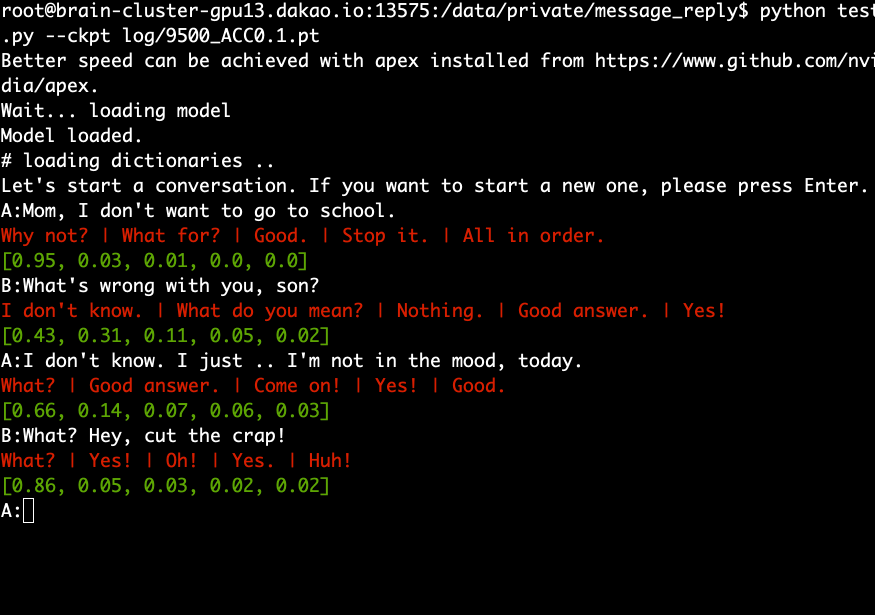
Загрузите и извлеките предварительно обученную модель и выполните следующую команду.
python test.py --ckpt log/9500_ACC0.1.pt
Тренировочные потери медленно, но неуклонно уменьшаются.
Точность@5 оценочных данных составляет от 10 до 20 процентов.
Для реального применения необходим гораздо больший корпус.
Не уверен, насколько сценарии фильмов похожи на диалоги-сообщения.
Необходима лучшая стратегия построения групп синонимов.
Чат-бот, основанный на поиске, является реалистичным приложением, поскольку он безопаснее и проще, чем чат-бот, основанный на генерации.


