ThinkRAG
1.0.0
Английский | Упрощенный китайский
Систему улучшения поиска больших моделей ThinkRAG можно легко развернуть на ноутбуке для реализации интеллектуальных ответов на вопросы в местной базе знаний.
Система построена на основе LlamaIndex и Streamlit и оптимизирована для домашних пользователей во многих областях, таких как выбор модели и обработка текста.
ThinkRAG — это прикладная система для крупных моделей, разработанная для профессионалов, исследователей, студентов и других работников умственного труда. Ее можно использовать непосредственно на ноутбуках, а данные базы знаний сохраняются локально на компьютере.
ThinkRAG имеет следующие возможности:
В частности, ThinkRAG также провел множество настроек и оптимизации для домашних пользователей:
ThinkRAG может использовать все модели, поддерживаемые фреймом данных LlamaIndex. Информацию о списке моделей можно найти в соответствующей документации.
ThinkRAG стремится создать систему приложений, которая будет удобна в использовании, полезна и проста в использовании.
Поэтому мы сделали тщательный выбор и компромиссы между различными моделями, компонентами и технологиями.
Во-первых, при использовании больших моделей ThinkRAG поддерживает API OpenAI и все совместимые API-интерфейсы LLM, включая отечественных производителей крупных моделей, таких как:
Если вы хотите развертывать большие модели локально, ThinkRAG выбирает Ollama, которая проста и удобна в использовании. Мы можем загрузить большие модели для локального запуска через Ollama.
В настоящее время Ollama поддерживает локализованное развертывание почти всех основных крупных моделей, включая Llama, Gemma, GLM, Mistral, Phi, Llava и т. д. Для получения подробной информации посетите официальный сайт Олламы ниже.
Система также использует встраиваемые модели и переупорядоченные модели и поддерживает большинство моделей Hugging Face. В настоящее время ThinkRAG в основном использует модели серии BGE от BAAI. Местные пользователи могут посетить зеркальный веб-сайт, чтобы узнать и загрузить.
После загрузки кода с Github используйте pip для установки необходимых компонентов.
pip3 install -r requirements.txtЧтобы запустить систему в автономном режиме, сначала загрузите Ollama с официального сайта. Затем используйте команду Ollama для загрузки больших моделей, таких как GLM, Gemma и QWen.
Синхронно загрузите модель внедрения (BAAI/bge-large-zh-v1.5) и модель реранжирования (BAAI/bge-reranker-base) из Hugging Face в каталог localmodels.
Конкретные шаги см. в документе в каталоге документации: HowToDownloadModels.md.
Чтобы добиться более высокой производительности, рекомендуется использовать коммерческий API LLM для больших моделей с сотнями миллиардов параметров.
Сначала получите ключ API от поставщика услуг LLM и настройте следующие переменные среды.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "Вы можете пропустить этот шаг и настроить ключ API через интерфейс приложения после запуска системы.
Если вы решите использовать один или несколько API-интерфейсов LLM, удалите поставщика услуг, который вы больше не используете, в файле конфигурации config.py.
Конечно, вы также можете добавить в файл конфигурации других поставщиков услуг, совместимых с API OpenAI.
ThinkRAG по умолчанию работает в режиме разработки. В этом режиме система использует локальное файловое хранилище и вам не нужно устанавливать какую-либо базу данных.
Чтобы переключиться в производственный режим, вы можете настроить переменные среды следующим образом.
THINKRAG_ENV = productionВ производственном режиме система использует векторную базу данных Chroma и базу данных «ключ-значение» Redis.
Если у вас не установлен Redis, рекомендуется установить его через Docker или использовать существующий экземпляр Redis. Настройте информацию о параметрах экземпляра Redis в файле config.py.
Теперь вы готовы запустить ThinkRAG.
Запустите следующую команду в каталоге, содержащем файл app.py.
streamlit run app.pyСистема запустится и автоматически откроет следующий URL-адрес в браузере для отображения интерфейса приложения.
http://локальный хост:8501/
Первый запуск может занять некоторое время. Если встроенная модель на Hugging Face не загружена заранее, система автоматически загрузит модель, и вам придется подождать дольше.
ThinkRAG поддерживает настройку и выбор больших моделей в пользовательском интерфейсе, включая базовый URL-адрес и ключ API LLM API для больших моделей, и вы можете выбрать конкретную модель для использования, например glm-4 ThinkRAG.
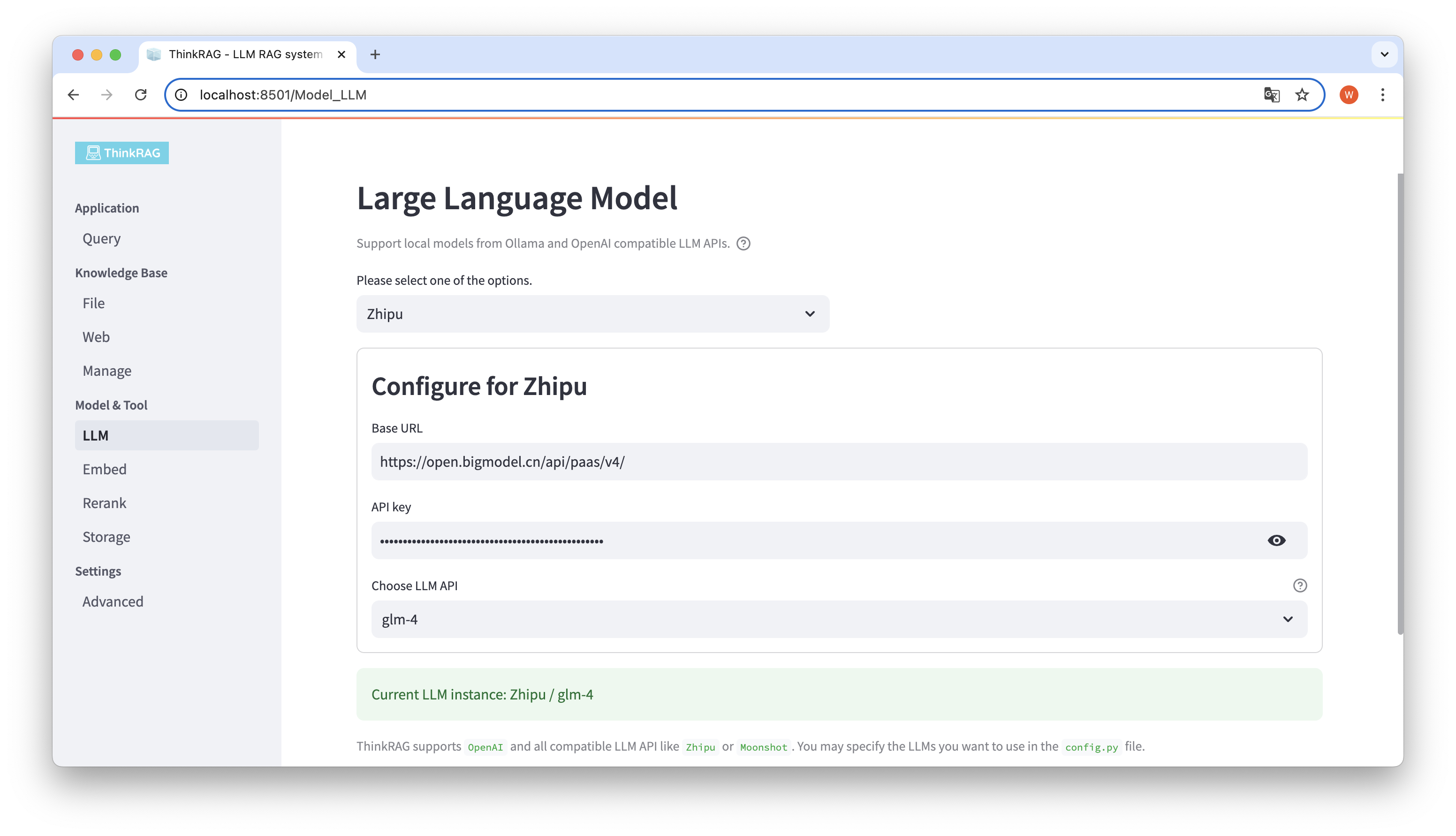
Система автоматически определит, доступны ли API и ключ. Если они доступны, выбранный в данный момент экземпляр большой модели будет отображаться зеленым текстом внизу.
Аналогично, система может автоматически получать модели, загруженные Олламой, а пользователь может выбрать нужную модель в пользовательском интерфейсе.
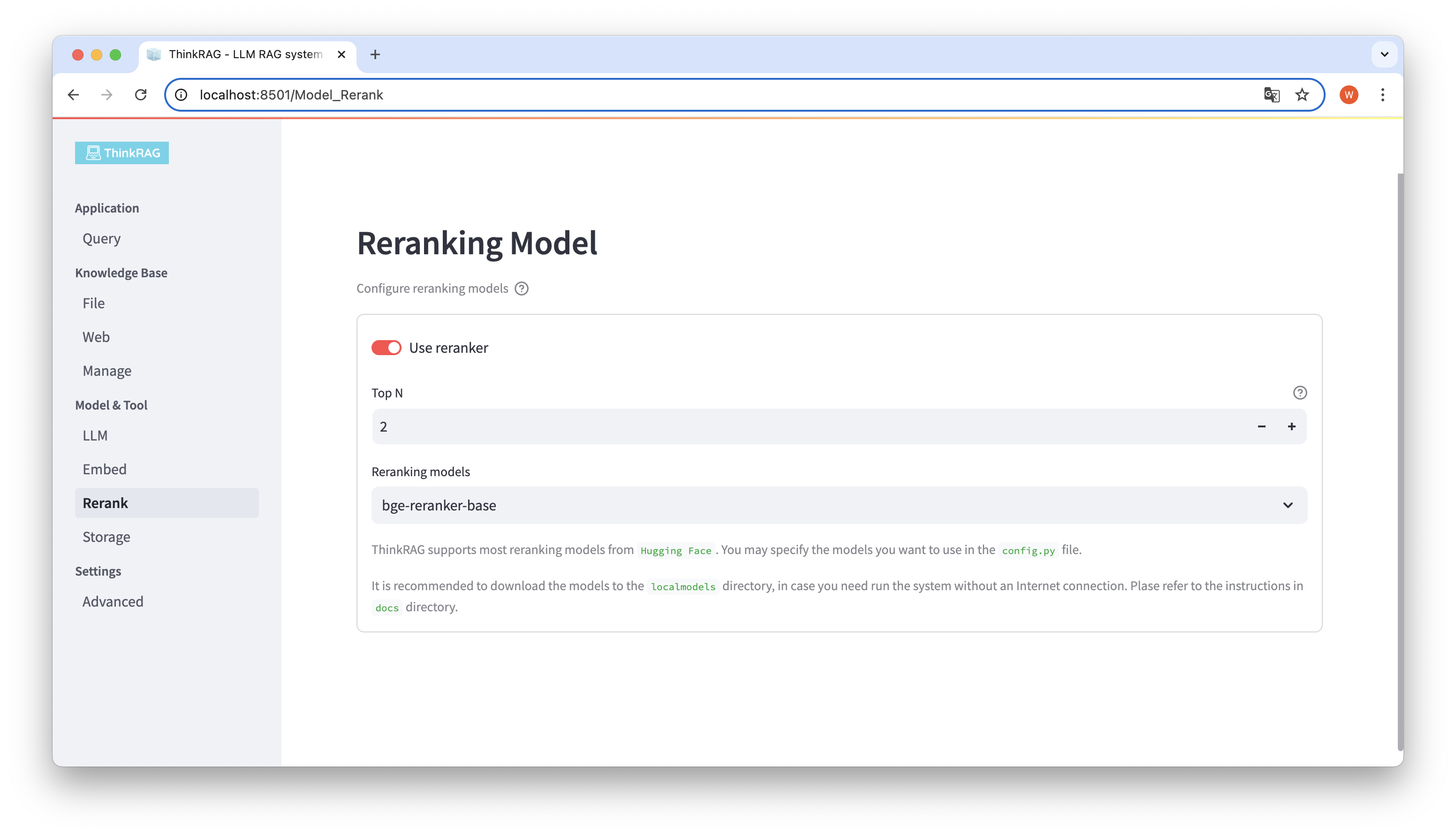
Если вы загрузили встроенную модель и переставили ее в локальный каталог localmodels. В пользовательском интерфейсе вы можете переключить выбранную модель и установить параметры переставляемой модели, например Top N.
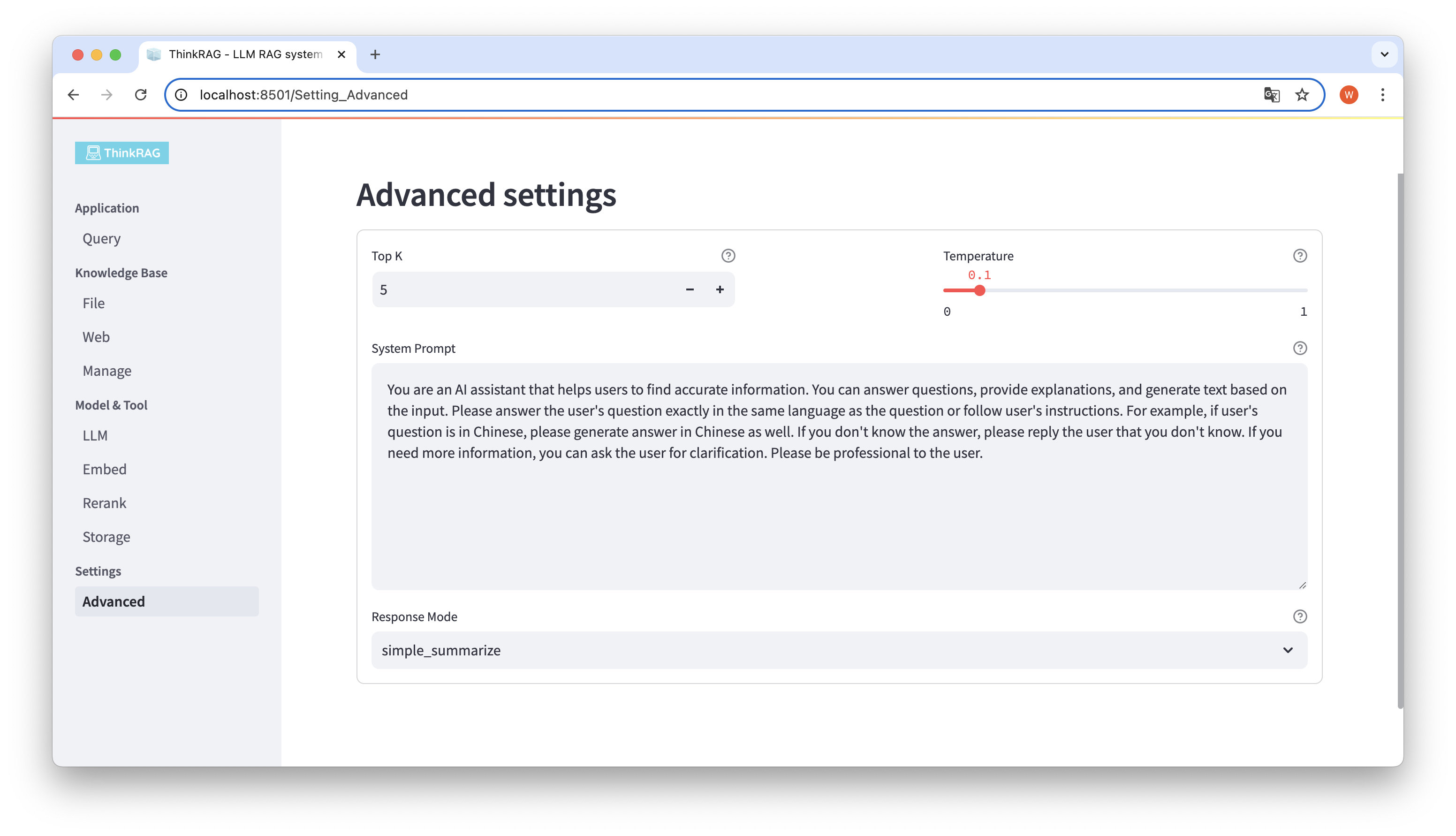
На левой панели навигации нажмите «Дополнительные параметры» (Настройки-Дополнительно). Также вы можете установить следующие параметры:
Используя различные параметры, мы можем сравнивать результаты больших моделей и находить наиболее эффективную комбинацию параметров.
ThinkRAG поддерживает загрузку различных файлов, таких как PDF, DOCX, PPTX и т. д., а также поддерживает загрузку URL-адресов веб-страниц.
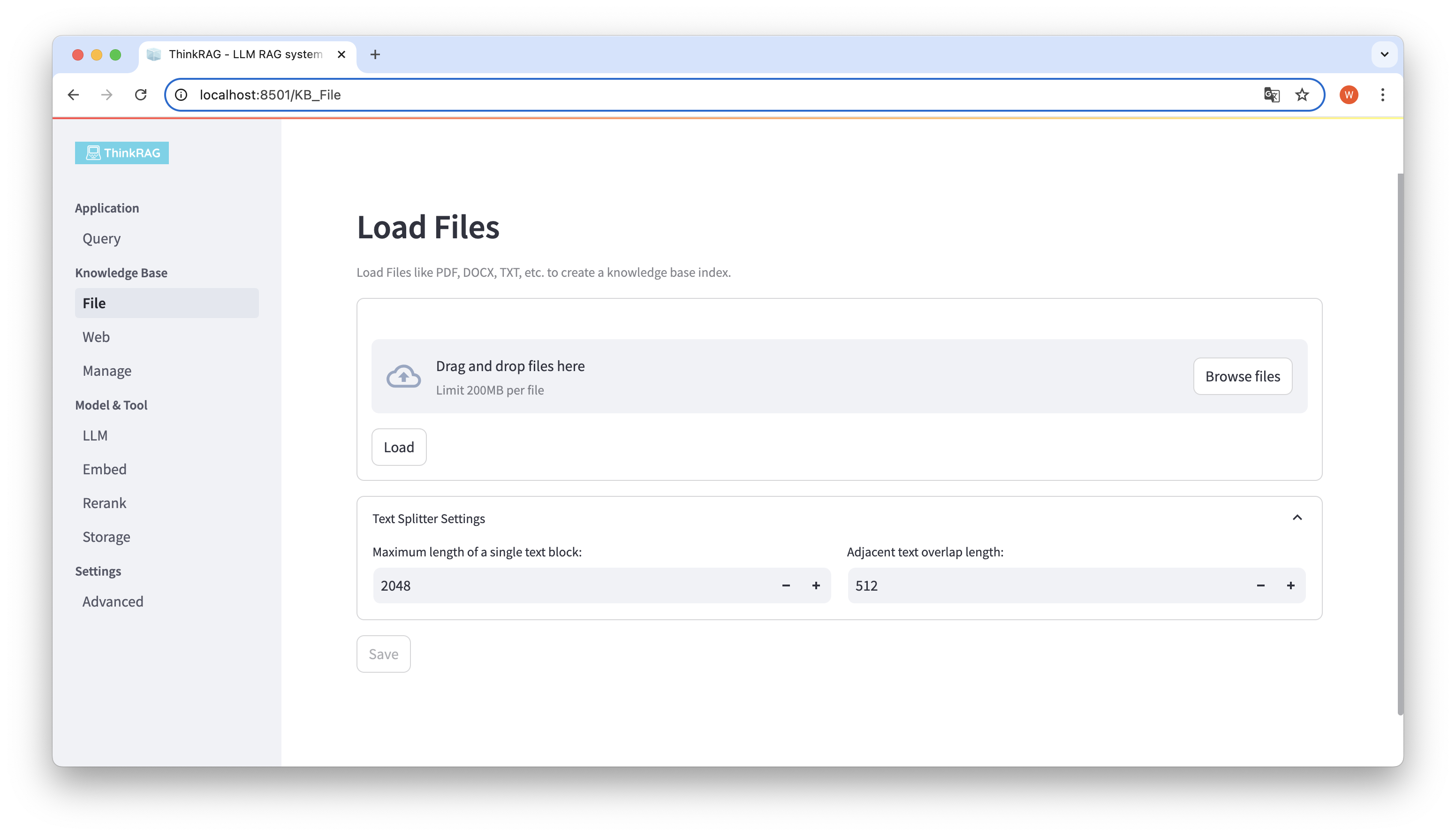
Нажмите кнопку «Обзор файлов», выберите файл на своем компьютере, а затем нажмите кнопку «Загрузить», чтобы загрузить все загруженные файлы.
Затем нажмите кнопку «Сохранить», и система обработает файл, включая сегментацию текста и встраивание, и сохранит его в базе знаний.
Аналогичным образом вы можете ввести или вставить URL-адрес веб-страницы, получить информацию о веб-странице и сохранить ее в базе знаний после обработки.
Система поддерживает управление базой знаний.
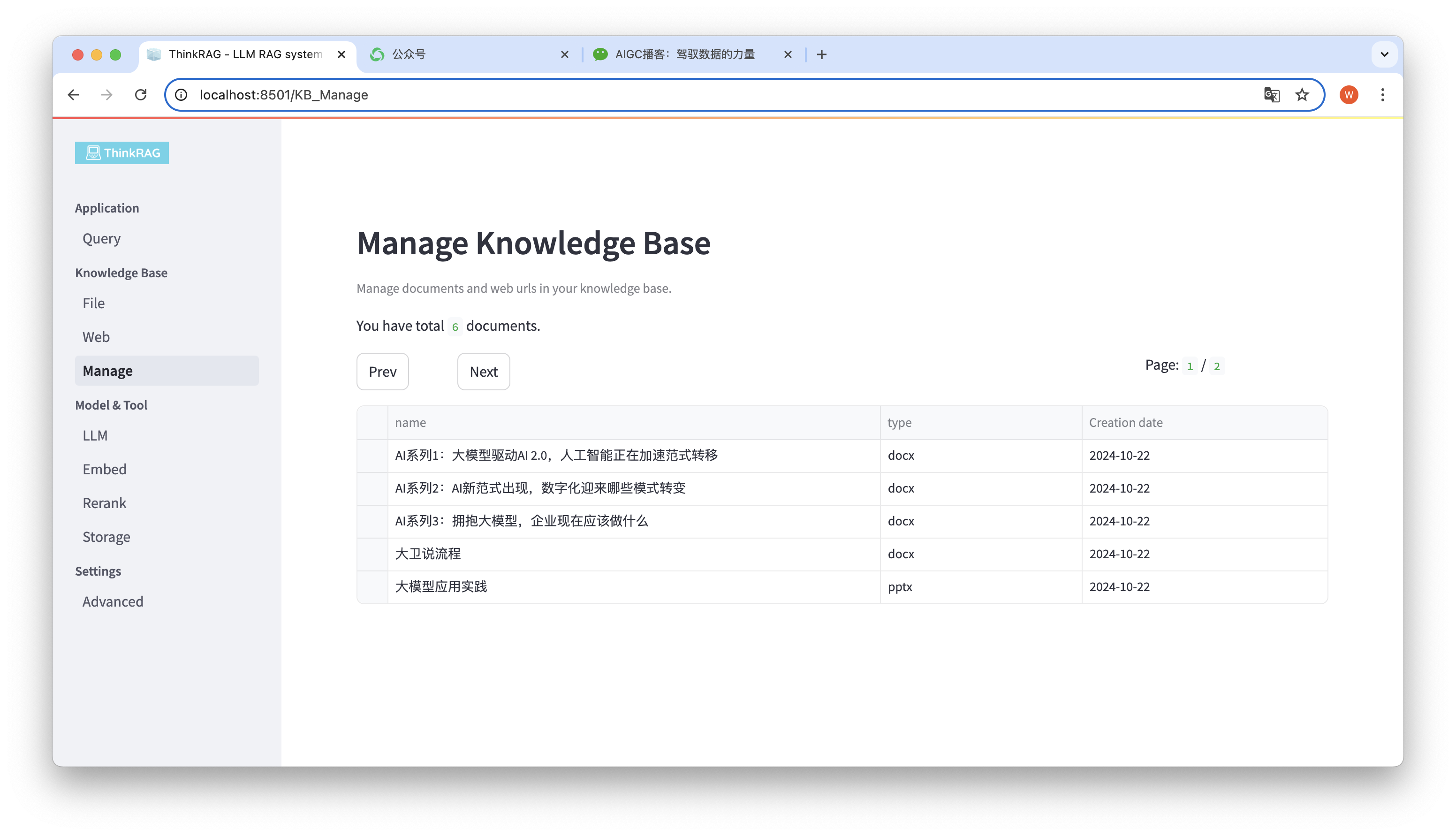
Как показано на рисунке выше, ThinkRAG может перечислять все документы в базе знаний на страницах.
Выберите документы, которые необходимо удалить, и появится кнопка «Удалить выбранные документы». Нажмите эту кнопку, чтобы удалить документы из базы знаний.
На левой панели навигации нажмите «Запрос», и появится интеллектуальная страница вопросов и ответов.
После ввода вопроса система выполнит поиск в базе знаний и предоставит ответ. В ходе этого процесса система будет использовать такие технологии, как гибридный поиск и перестановка, для получения точного контента из базы знаний.
Например, мы загрузили в базу знаний документ Word: «David Says Process.docx».
Теперь задайте вопрос: «Каковы три характеристики процесса?»
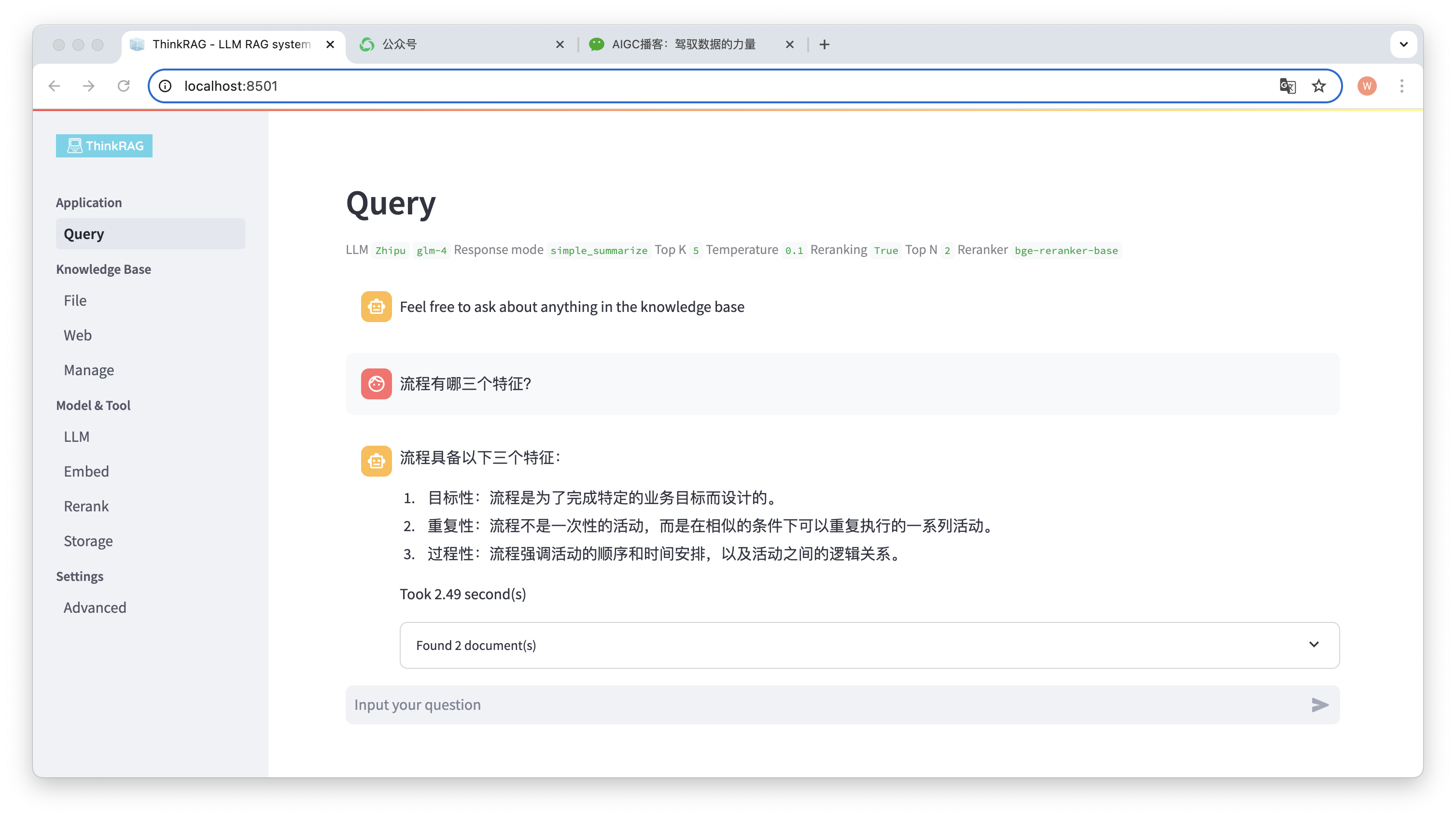
Как показано на рисунке, системе потребовалось 2,49 секунды, чтобы дать точный ответ: процесс целенаправленный, повторяющийся и процедурный. В то же время система также предоставляет 2 связанных документа, извлеченных из базы знаний.
Видно, что ThinkRAG полностью и эффективно реализует функцию расширенной генерации поиска больших моделей на основе локальной базы знаний.
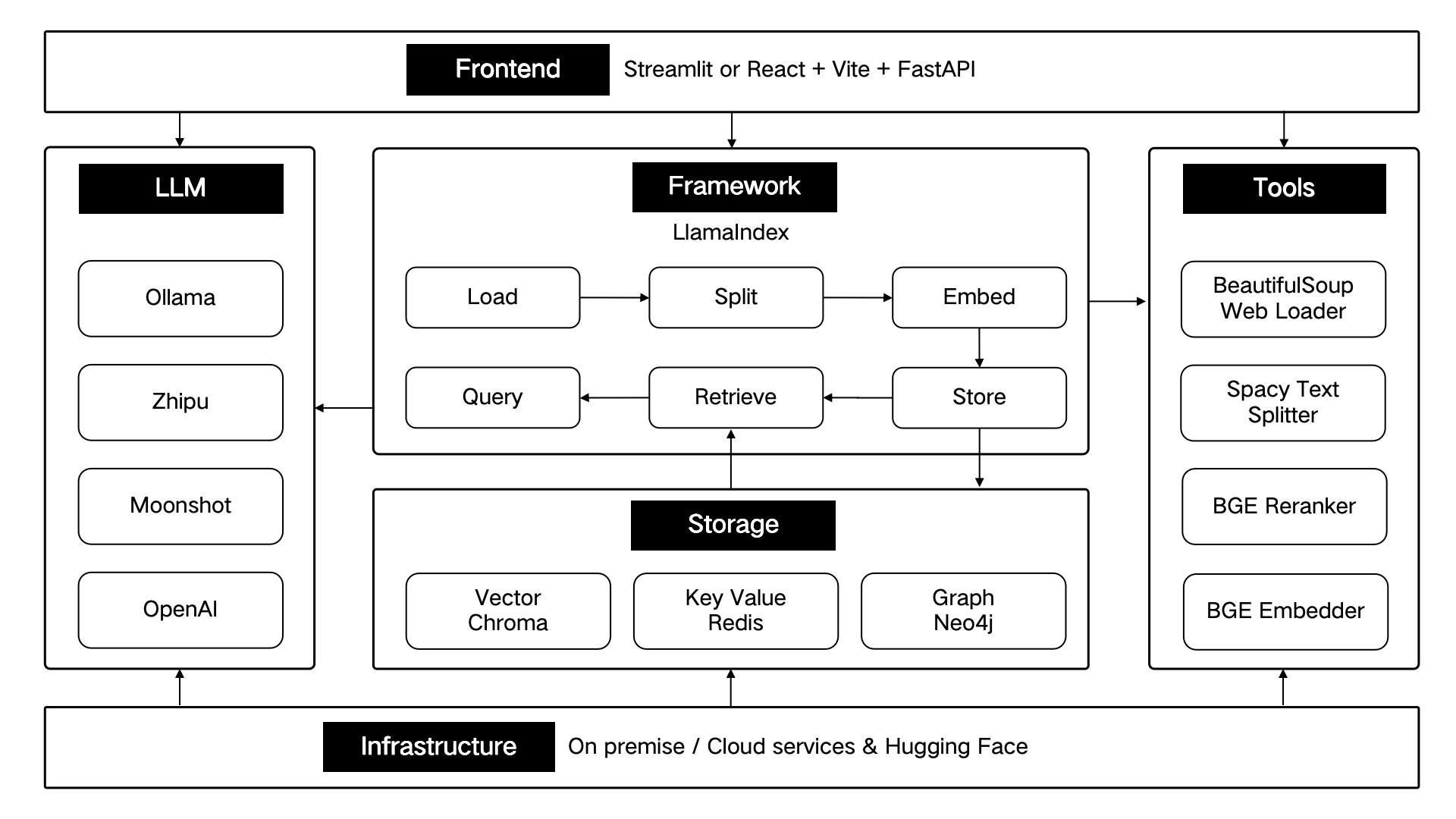
ThinkRAG разработан с использованием инфраструктуры данных LlamaIndex и использует Streamlit для внешнего интерфейса. В режиме разработки и режиме производства системы используются разные технические компоненты соответственно, как показано в следующей таблице:
| режим разработки | режим производства | |
|---|---|---|
| структура RAG | ЛамаИндекс | ЛамаИндекс |
| интерфейсная платформа | Стримлит | Стримлит |
| встроенная модель | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| переставить модель | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| разделитель текста | Разделитель предложений | SpacyTextSplitter |
| Хранение разговоров | SimpleChatStore | Редис |
| Хранение документов | SimpleDocumentStore | Редис |
| Индексное хранилище | SimpleIndexStore | Редис |
| векторное хранилище | ПростойВекторМагазин | ЛансДБ |
Эти технические компоненты архитектурно спроектированы согласно шести частям: внешний интерфейс, платформа, большая модель, инструменты, хранилище и инфраструктура.
Как показано ниже:
ThinkRAG продолжит оптимизировать основные функции и продолжать повышать эффективность и точность поиска, в основном включая:
В то же время мы будем продолжать совершенствовать архитектуру приложения и улучшать взаимодействие с пользователем, в основном включая:
Приглашаем вас присоединиться к проекту с открытым исходным кодом ThinkRAG и работать вместе над созданием продуктов искусственного интеллекта, которые понравятся пользователям!
ThinkRAG использует лицензию MIT.


