lance
v0.20.0

Современный формат столбчатых данных для машинного обучения. Преобразование из Parquet с помощью двух строк кода для ускорения произвольного доступа в 100 раз, векторного индекса, управления версиями данных и многого другого.
Совместим с pandas, DuckDB, Polars и pyarrow; в ближайшее время будут добавлены новые интеграции.
Документация • Блог • Discord • Twitter
Lance — это современный формат столбчатых данных, оптимизированный для рабочих процессов и наборов данных машинного обучения. Ланс идеально подходит для:
К основным особенностям Ланса можно отнести:
Высокопроизводительный произвольный доступ: в 100 раз быстрее, чем Parquet, без ущерба для производительности сканирования.
Векторный поиск: найдите ближайших соседей за миллисекунды и объедините OLAP-запросы с векторным поиском.
Автоматическое управление версиями без копирования: управляйте версиями своих данных без необходимости дополнительной инфраструктуры.
Экосистемная интеграция: Apache Arrow, Pandas, Polars, DuckDB и другие на подходе.
Кончик
Lance находится в активной разработке, и мы приветствуем вклад. Пожалуйста, ознакомьтесь с нашим руководством по участию для получения дополнительной информации.
Установка
pip install pylanceЧтобы установить предварительную версию:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceКончик
Предварительные версии выпускаются чаще, чем полные версии, и содержат новейшие функции и исправления ошибок. Они проходят тот же уровень тестирования, что и полные версии. Мы гарантируем, что они останутся опубликованными и доступными для загрузки в течение как минимум 6 месяцев. Если вы хотите привязаться к определенной версии, отдайте предпочтение стабильной версии.
Превращение в Ланса
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Чтение данных Lance
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )Панды
df = dataset . to_table (). to_pandas ()
dfДакДБ
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Векторный поиск
Загрузите подмножество sift1m
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzПревратите его в Ланса
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Создайте индекс
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQПоиск набора данных
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Каталог | Описание |
|---|---|
| ржавчина | Реализация ядра Rust |
| питон | Привязки Python (pyo3) |
| документы | Источник документации |
Здесь мы выделим несколько аспектов дизайна Лэнса. Для получения более подробной информации см. полный проектный документ Lance.
Векторный индекс : векторный индекс для поиска сходства в пространстве внедрения. Поддержка как процессоров ( x86_64 и arm ), так и графических процессоров ( Nvidia (cuda) и Apple Silicon (mps) ).
Кодировки : для достижения быстрого столбчатого сканирования и сублинейных точечных запросов Лэнс использует собственные кодировки и макеты.
Вложенные поля : Лэнс сохраняет каждое подполе как отдельный столбец для поддержки эффективных фильтров, таких как «найти изображения, на которых обнаруженные объекты включают кошек».
Управление версиями : Манифест можно использовать для записи снимков. В настоящее время мы поддерживаем автоматическое создание новых версий посредством добавления, перезаписи и создания индекса.
Быстрые обновления (ROADMAP): обновления будут поддерживаться через журналы упреждающей записи.
Богатые вторичные индексы (ROADMAP):
Мы использовали набор данных SIFT для сравнения наших результатов с 1 млн векторов 128D.
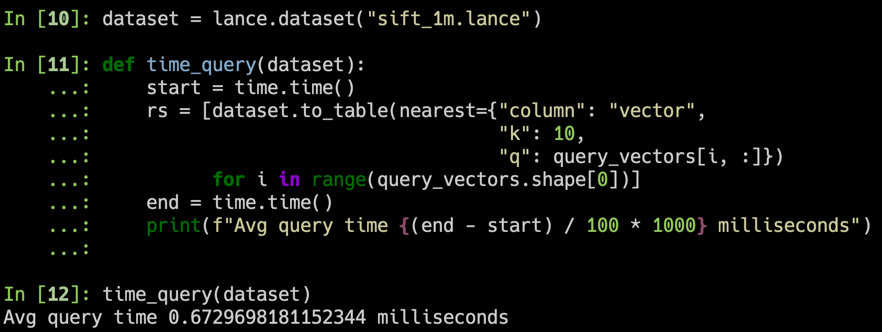
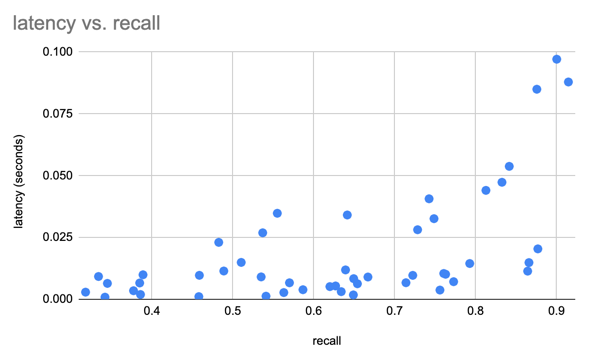
Мы создаем набор данных Lance, используя набор данных Oxford Pet, чтобы провести предварительное тестирование производительности Lance по сравнению с Parquet и необработанными изображениями/XML. Для аналитических запросов Лэнс в 50–100 раз лучше, чем чтение необработанных метаданных. Для пакетного произвольного доступа Lance в 100 раз лучше, чем паркетные и необработанные файлы.

Цикл разработки машинного обучения включает в себя этапы:
график LR
A[Коллекция] --> B[Исследование];
B --> C[Аналитика];
C --> D[Инженер по функциям];
D --> E[Обучение];
E --> F[Оценка];
Ф --> С;
E --> G[Развертывание];
G --> H[Мониторинг];
Ч --> А;
Люди используют разные представления данных на разных этапах производительности или ограничиваются доступными инструментами. Академические учреждения в основном используют XML/JSON для аннотаций и сжатые изображения/данные датчиков для глубокого обучения, которые сложно интегрировать в инфраструктуру данных и медленно обучать в облачном хранилище. В то время как промышленность использует озера данных (методы на основе Parquet, например, Delta Lake, Iceberg) или хранилища данных (AWS Redshift или Google BigQuery) для сбора и анализа данных, им приходится конвертировать данные в удобные для обучения форматы, такие как Rikai/ Петашторм или TFRecord. Множественные одноцелевые преобразования данных, а также синхронизация копий между облачным хранилищем и локальными обучающими экземплярами стали обычной практикой.
Хотя каждый из существующих форматов данных превосходно справляется с той рабочей нагрузкой, для которой он изначально был разработан, нам нужен новый формат данных, адаптированный для многоэтапных циклов разработки машинного обучения, чтобы уменьшить разрозненность данных.
Сравнение различных форматов данных на каждом этапе цикла разработки машинного обучения.
| Лэнс | Паркет и ORC | JSON и XML | TFRecord | База данных | Склад | |
|---|---|---|---|---|---|---|
| Аналитика | Быстрый | Быстрый | Медленный | Медленный | Приличный | Быстрый |
| Особенности проектирования | Быстрый | Быстрый | Приличный | Медленный | Приличный | Хороший |
| Обучение | Быстрый | Приличный | Медленный | Быстрый | Н/Д | Н/Д |
| Разведка | Быстрый | Медленный | Быстрый | Медленный | Быстрый | Приличный |
| Инфраподдержка | Богатый | Богатый | Приличный | Ограниченный | Богатый | Богатый |
В настоящее время Lance используется в производстве: