local LLM with RAG
1.0.0

Этот проект представляет собой экспериментальную песочницу для проверки идей, связанных с запуском локальных моделей большого языка (LLM) с помощью Ollama для выполнения поисково-дополненной генерации (RAG) для ответов на вопросы на основе образцов PDF-файлов. В этом проекте мы также используем Ollama для создания вложений с nomic-embed-text для использования с Chroma. Обратите внимание, что внедрения перезагружаются каждый раз при запуске приложения, что неэффективно и делается здесь только в целях тестирования.
Существует также веб-интерфейс, созданный с использованием Streamlit, обеспечивающий другой способ взаимодействия с Ollama.
python3 -m venv .venv .source .venv/bin/activate в Unix или MacOS или ..venvScriptsactivate в Windows.pip install -r requirements.txt . Примечание. При первом запуске проекта он загрузит необходимые модели из Ollama для LLM и встраивания. Это однократный процесс настройки, который может занять некоторое время в зависимости от вашего интернет-соединения.
python app.py -m <model_name> -p <path_to_documents> чтобы указать модель и путь к документам. Если модель не указана, по умолчанию используется мистраль. Если путь не указан, по умолчанию используется Research расположенное в репозитории для примера.-e <embedding_model_name> . Если не указано, по умолчанию используется nomic-embed-text. Это загрузит файлы PDF и Markdown, сгенерирует встраивания, запросит коллекцию и ответит на вопрос, заданный в app.py
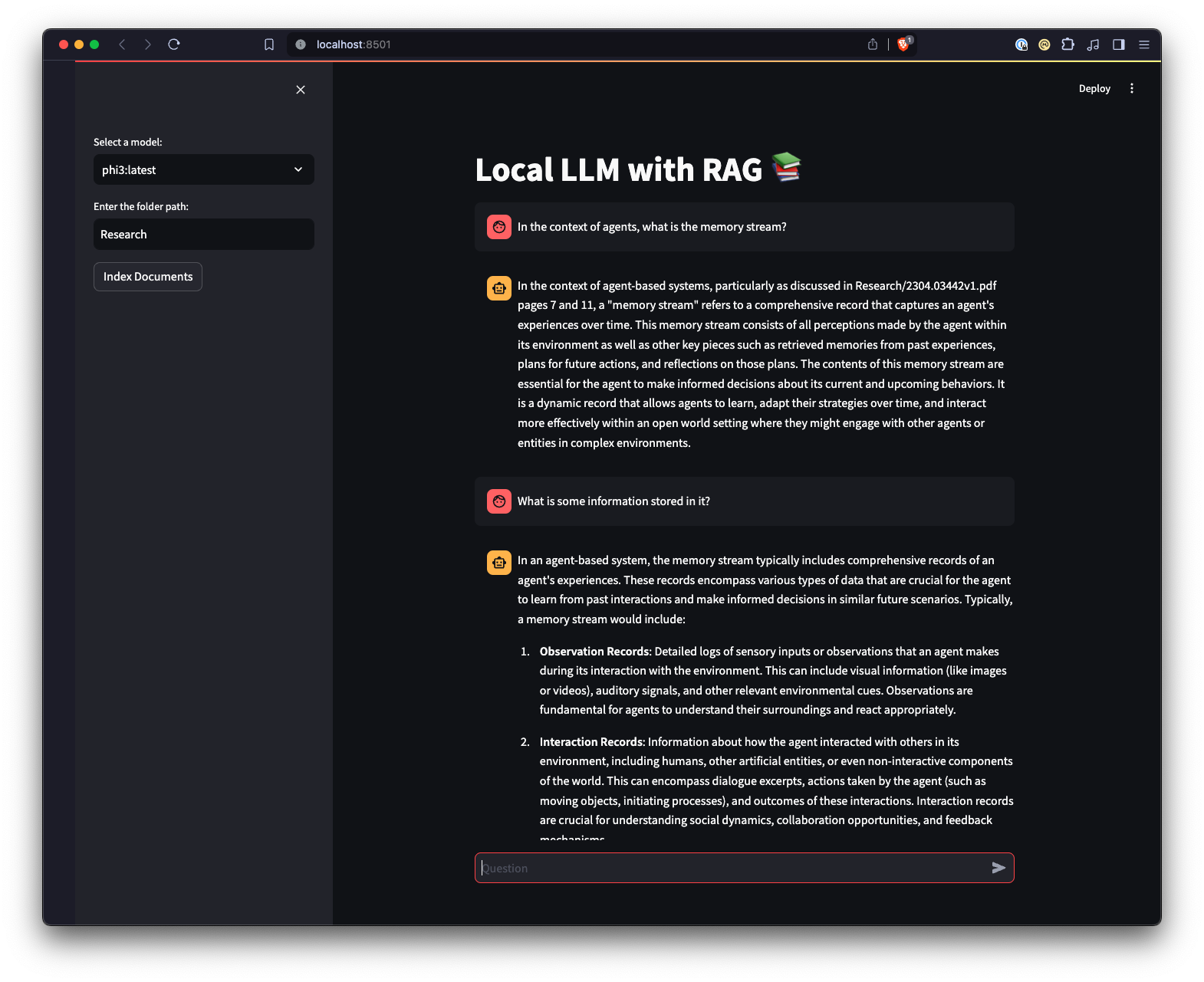
ui.pystreamlit run ui.pyЭто запустит локальный веб-сервер и откроет новую вкладку в веб-браузере по умолчанию, где вы сможете взаимодействовать с приложением. Пользовательский интерфейс Streamlit позволяет выбирать модели, выбирать папку, обеспечивая более простой и интуитивно понятный способ взаимодействия с системой чат-бота RAG по сравнению с интерфейсом командной строки. Приложение будет обрабатывать загрузку документов, генерировать вложения, запрашивать коллекцию и отображать результаты в интерактивном режиме.


