duplicut
v2.2 release
В настоящее время создание списка слов паролей обычно подразумевает объединение нескольких источников данных.
В идеале наиболее вероятные пароли должны стоять в начале списка слов, чтобы наиболее распространенные пароли были взломаны мгновенно.
С существующими инструментами дедупликации вы вынуждены выбирать, предпочитаете ли вы сохранять порядок ИЛИ обрабатывать огромные списки слов .
К сожалению, для создания списка слов требуются оба :

Итак, я написал duplicut на высокооптимизированном C, чтобы удовлетворить эту очень специфическую потребность?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt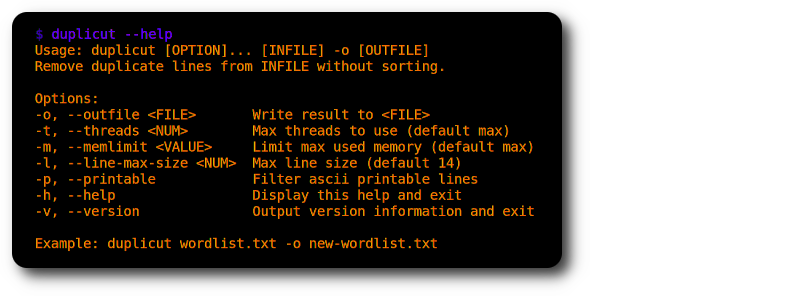
Функции :
-l )-p ).Выполнение :
Ограничения :
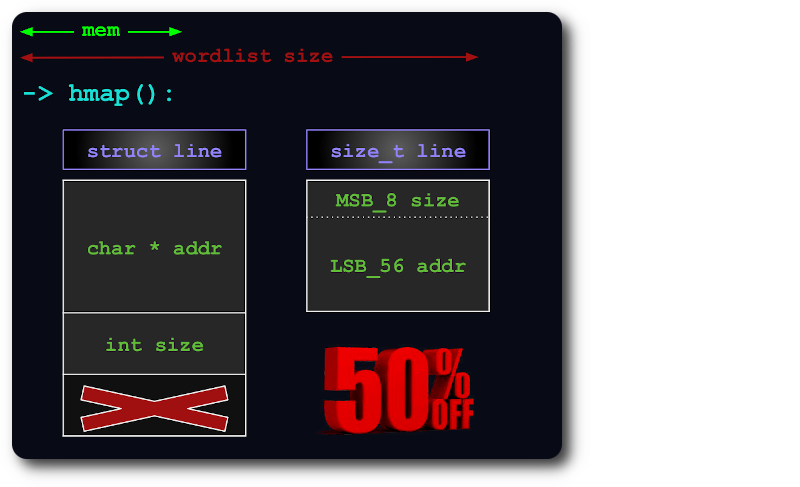
uint64 достаточно для индексации строк в хэш-карте, упаковывая информацию size в дополнительные биты указателя:
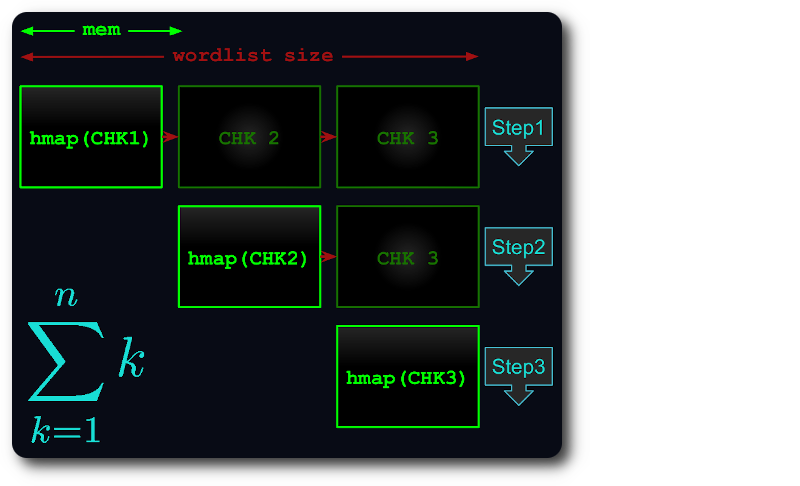
Если весь файл не помещается в памяти, он разбивается на виртуальные фрагменты таким образом, чтобы каждый фрагмент использовал как можно больше оперативной памяти.
Затем каждый фрагмент загружается в хэш-карту, дедуплицируется и тестируется на последующих фрагментах.
Таким образом, время выполнения уменьшится не более чем до числа треугольников :
Если вы обнаружили ошибку или что-то работает не так, как ожидалось, скомпилируйте дубликат в режиме отладки и опубликуйте сообщение о проблеме с прикрепленным выводом:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


