Okapi
1.0.0
Окапи
Настраиваемые модели больших языков на нескольких языках с подкреплением обучения на основе обратной связи от человека
Это репозиторий платформы Okapi, в котором представлены ресурсы и модели для настройки инструкций для моделей большого языка (LLM) с подкреплением обучения на основе обратной связи от человека (RLHF) на нескольких языках. Наша платформа поддерживает 26 языков, включая 8 языков с высоким уровнем ресурсов, 11 языков со средними ресурсами и 7 языков с низкими ресурсами.
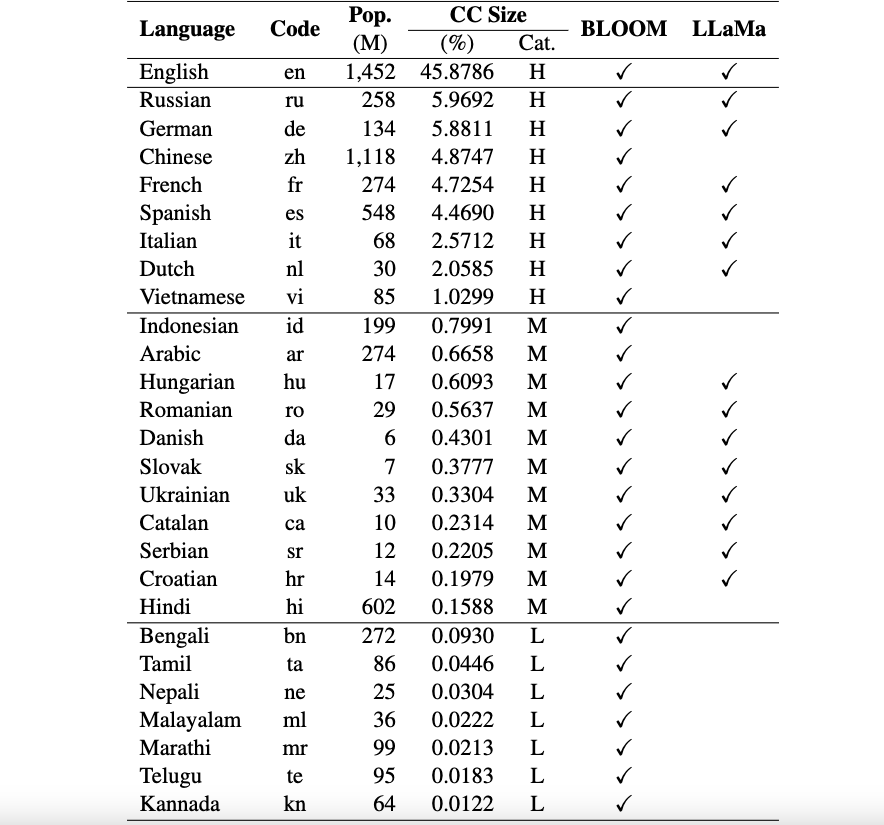
Ресурсы Okapi : мы предоставляем ресурсы для настройки инструкций с помощью RLHF для 26 языков, включая подсказки ChatGPT, многоязычные наборы данных инструкций и данные рейтинга многоязычных ответов.
Модели Окапи : мы предоставляем настроенные инструкции LLM на основе RLHF для 26 языков в наборе данных Okapi. Наши модели включают версии как на базе BLOOM, так и на базе LLaMa. Мы также предоставляем сценарии для взаимодействия с нашими моделями и тонкой настройки LLM с помощью наших ресурсов.
Наборы эталонных данных для многоязычной оценки : мы предоставляем три эталонных набора данных для оценки многоязычных моделей больших языков (LLM) для 26 языков. Вы можете получить доступ к полным наборам данных и сценариям оценки: здесь.
Уведомления об использовании и лицензии : Okapi предназначен и лицензирован только для исследовательского использования. Наборы данных соответствуют требованиям CC BY NC 4.0 (разрешены только некоммерческое использование), а модели, обученные с использованием набора данных, не должны использоваться вне исследовательских целей.
Наш технический документ с результатами оценки можно найти здесь.
Мы выполняем комплексный процесс сбора данных для подготовки необходимых данных для нашей многоязычной платформы Okapi в четыре основных этапа:
Чтобы загрузить весь набор данных, вы можете использовать следующий скрипт:
bash scripts/download.shЕсли вам нужны данные только для определенного языка, вы можете указать код языка в качестве аргумента скрипта:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viПосле загрузки наши опубликованные данные можно найти в каталоге наборов данных . Он включает в себя:
multilingual-alpaca-52k : переведенные данные для 52 тысяч английских инструкций в альпаке на 26 языков.
multilingual-ranking-data-42k : данные рейтинга многоязычных ответов для 26 языков. Для каждого языка мы предоставляем 42 тыс. инструкций; каждый из них имеет 4 ранжированных ответа. Эти данные можно использовать для обучения моделей вознаграждения для 26 языков.
multilingual-rl-tuning-64k : данные многоязычных инструкций для RLHF. Мы предоставляем 62 тыс. инструкций для каждого из 26 языков.
Используя наши наборы данных Okapi и технику настройки инструкций на основе RLHF, мы представляем многоязычные точно настроенные LLM для 26 языков, основанные на версиях 7B LLaMA и BLOOM. Модели можно получить на HuggingFace здесь.
Okapi поддерживает интерактивные чаты с помощью многоязычных модулей LLM с инструкциями на 26 языках. Выполните следующие шаги для чатов:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )Мы также предоставляем сценарии для точной настройки LLM с использованием данных наших инструкций с использованием RLHF, охватывающие три основных этапа: контролируемая точная настройка, моделирование вознаграждения и точная настройка с помощью RLHF. Используйте следующие шаги для точной настройки LLM:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]Если вы используете данные, модель или код из этого репозитория, укажите:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

