MELD
1.0.0
Если вас интересуют программы LLM по тестированию IQ, ознакомьтесь с нашей новой работой: AlgoPuzzleVQA.
Мы опубликовали визуальные функции, извлеченные с помощью Resnet — https://github.com/declare-lab/MM-Align.
Для получения обновленных базовых показателей перейдите по этой ссылке: conv-emotion
Для загрузки данных используйте wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
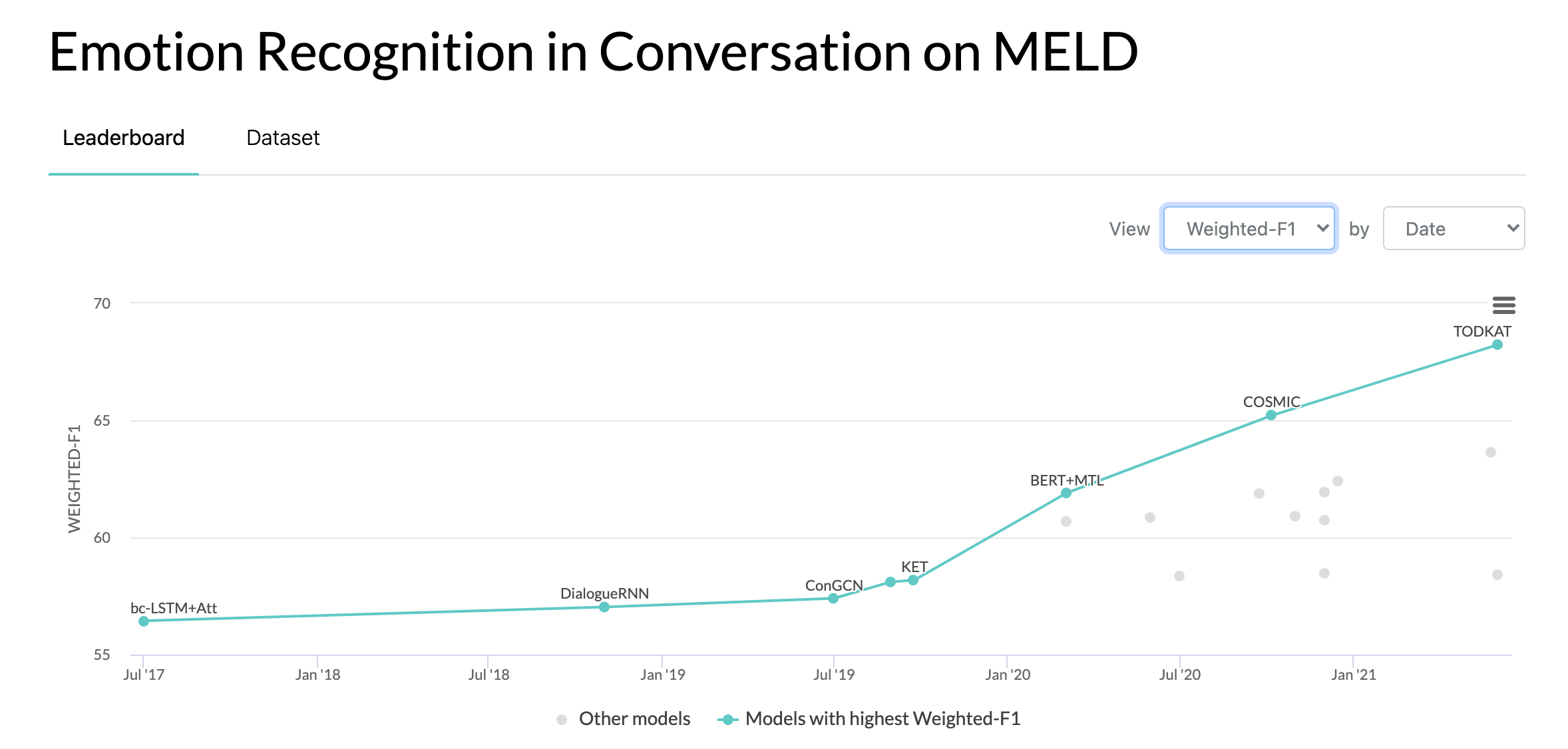
10.10.2020: Новая статья и SOTA по распознаванию эмоций в разговорах по набору данных MELD. Код см. в каталоге COSMIC. Прочтите статью — COSMIC: Знания COMmonSense для идентификации eMotion в разговорах.
22.05.2019: MELD: Мультимодальный многосторонний набор данных для распознавания эмоций в разговоре был принят в качестве полноценного документа на ACL 2019. Обновленный документ можно найти здесь — https://arxiv.org/pdf/1810.02508. PDF
05.22.2019: Вышел Dyadic MELD. Его можно использовать для тестирования диадических диалоговых моделей.
11.15.2018: Исправлена проблема в train.tar.gz.
Чжан, Ячжоу, Цючи Ли, Давэй Сун, Пэн Чжан и Панпань Ван. «Квантовые интерактивные сети для разговорного анализа настроений». IJCAI 2019.
Чжан, Дун, Лянцин Ву, Чанлун Сунь, Шушань Ли, Цяомин Чжу и Годун Чжоу. «Моделирование зависимости от контекста и говорящего для обнаружения эмоций в разговорах с несколькими говорящими». IJCAI 2019.
Госал, Дипанвей, Навонил Маджумдер, Суджанья Пориа, Нияти Чхая и Александр Гельбух. «DialogueGCN: графовая сверточная нейронная сеть для распознавания эмоций в разговоре». ЭМНЛП 2019.
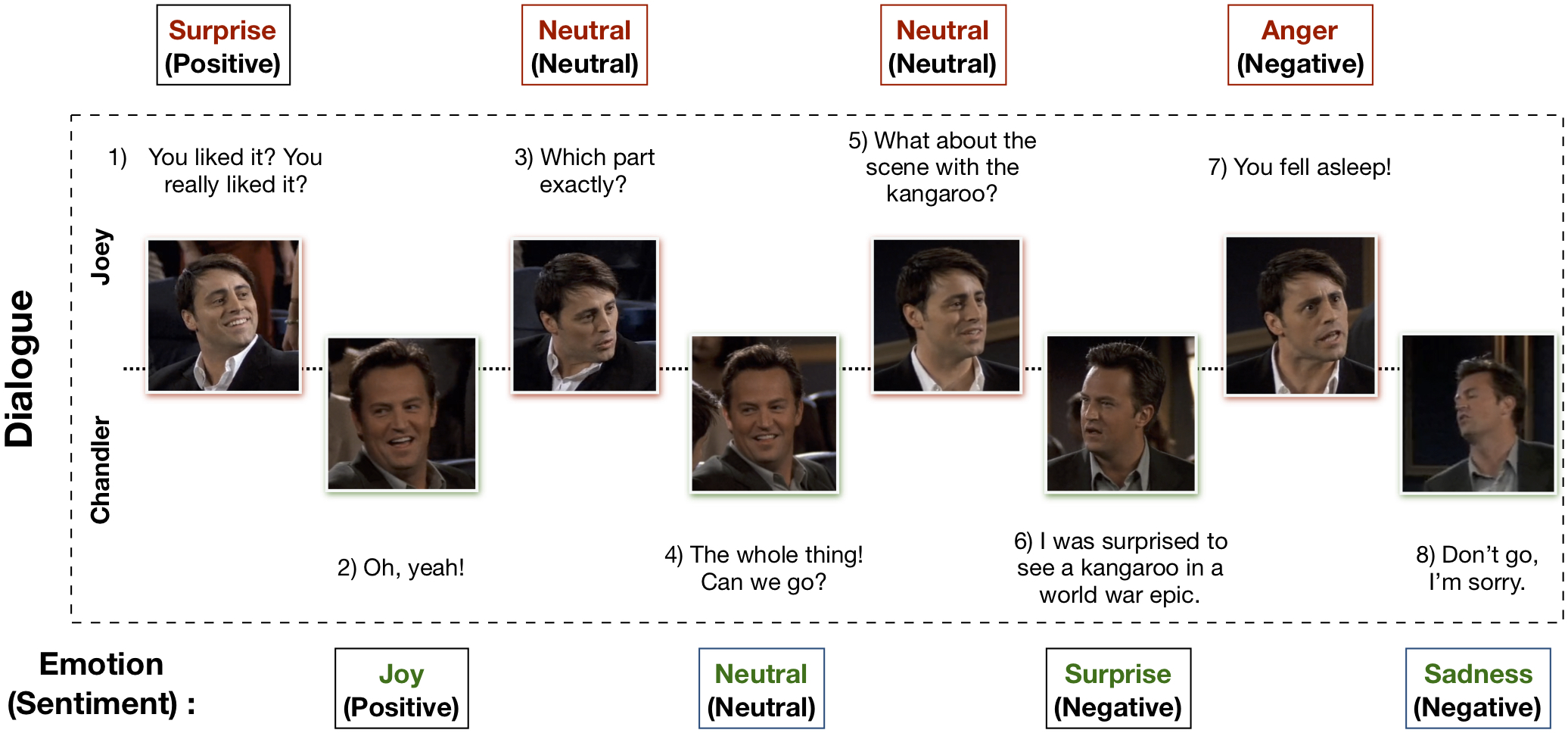
Мультимодальный набор данных EmotionLines (MELD) был создан путем улучшения и расширения набора данных EmotionLines. MELD содержит те же экземпляры диалогов, что и EmotionLines, но помимо текста он также включает в себя аудио и визуальную модальность. В MELD более 1400 диалогов и 13000 высказываний из сериала «Друзья». В диалогах приняли участие несколько спикеров. Каждое высказывание в диалоге было отмечено любой из этих семи эмоций — гневом, отвращением, грустью, радостью, нейтральностью, удивлением и страхом. MELD также имеет аннотацию настроений (положительных, отрицательных и нейтральных) для каждого высказывания.
| Статистика | Тренироваться | Дев | Тест |
|---|---|---|---|
| # модальности | {а,в,т} | {а,в,т} | {а,в,т} |
| # уникальных слов | 10 643 | 2384 | 4,361 |
| Среднее длина высказывания | 8.03 | 7,99 | 8.28 |
| Макс. длина высказывания | 69 | 37 | 45 |
| Среднее Количество эмоций за диалог | 3.30 | 3.35 | 3.24 |
| количество диалогов | 1039 | 114 | 280 |
| количество высказываний | 9989 | 1109 | 2610 |
| количество спикеров | 260 | 47 | 100 |
| # смены эмоций | 4003 | 427 | 1003 |
| Среднее продолжительность высказывания | 3,59 с | 3,59 с | 3,58 с |
Пожалуйста, посетите https://affective-meld.github.io для получения более подробной информации.
| Тренироваться | Дев | Тест | |
|---|---|---|---|
| Злость | 1109 | 153 | 345 |
| Отвращение | 271 | 22 | 68 |
| Страх | 268 | 40 | 50 |
| Радость | 1743 г. | 163 | 402 |
| Нейтральный | 4710 | 470 | 1256 |
| Грусть | 683 | 111 | 208 |
| Сюрприз | 1205 | 150 | 281 |
Мультимодальный анализ данных использует информацию из нескольких параллельных каналов данных для принятия решений. С быстрым развитием искусственного интеллекта мультимодальное распознавание эмоций приобрело большой исследовательский интерес, в первую очередь из-за его потенциального применения во многих сложных задачах, таких как создание диалогов, мультимодальное взаимодействие и т. д. Система разговорного распознавания эмоций может использоваться для генерации соответствующих ответов путем анализ эмоций пользователей. Хотя существует множество работ по мультимодальному распознаванию эмоций, лишь немногие из них действительно сосредоточены на понимании эмоций в разговоре. Однако их работа ограничена только пониманием диадического разговора и, следовательно, не может быть масштабирована для распознавания эмоций в многосторонних разговорах, в которых участвует более двух участников. EmotionLines можно использовать в качестве ресурса для распознавания эмоций только по тексту, поскольку он не включает данные из других модальностей, таких как визуальные и аудио. В то же время следует отметить, что не существует мультимодального многостороннего разговорного набора данных, доступного для исследования распознавания эмоций. В этой работе мы расширили, улучшили и доработали набор данных EmotionLines для мультимодального сценария. Распознавание эмоций в последовательных поворотах сопряжено с рядом проблем, и понимание контекста — одна из них. Изменение эмоций и поток эмоций в последовательности поворотов диалога делают точное моделирование контекста сложной задачей. Поскольку в этом наборе данных у нас есть доступ к мультимодальным источникам данных для каждого диалога, мы предполагаем, что это улучшит моделирование контекста, что повысит общую производительность распознавания эмоций. Этот набор данных также можно использовать для разработки мультимодальной системы аффективного диалога. IEMOCAP, SEMAINE — это мультимодальные наборы разговорных данных, которые содержат метки эмоций для каждого высказывания. Однако эти наборы данных носят диадический характер, что оправдывает важность нашего набора данных Multimodal-EmotionLines. Другими общедоступными наборами данных мультимодального распознавания эмоций и настроений являются MOSEI, MOSI, MOUD. Однако ни один из этих наборов данных не является диалоговым.
Первый шаг связан с поиском временной метки каждого высказывания в каждом из диалогов, представленных в наборе данных EmotionLines. Для этого мы просканировали файлы субтитров всех эпизодов, которые содержат временные метки начала и окончания высказываний. Этот процесс позволил нам получить идентификатор сезона, идентификатор эпизода и временную метку каждого высказывания в эпизоде. При получении временных меток мы наложили два ограничения: (а) временные метки высказываний в диалоге должны быть в порядке возрастания, (б) все высказывания в диалоге должны принадлежать к одному и тому же эпизоду и сцене. Ограничение этими двумя условиями показало, что в EmotionLines некоторые диалоги состоят из нескольких естественных диалогов. Мы отфильтровали эти случаи из набора данных. Из-за этого шага исправления ошибок в нашем случае мы имеем другое количество диалогов по сравнению с EmotionLines. Получив временную метку каждого высказывания, мы извлекли соответствующие аудиовизуальные клипы из исходного эпизода. Отдельно мы также извлекли из этих видеоклипов аудиоконтент. Наконец, набор данных содержит визуальные, звуковые и текстовые модальности для каждого диалога.
Документ, объясняющий этот набор данных, можно найти — https://arxiv.org/pdf/1810.02508.pdf.
Посетите http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz, чтобы загрузить необработанные данные. Данные хранятся в формате .mp4 и их можно найти в файлах XXX.tar.gz. Аннотации можно найти по адресу https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Имя столбца | Описание |
|---|---|
| Сэр Нет. | Серийные номера высказываний в основном для ссылки на высказывания в случае разных версий или нескольких копий с разными подмножествами. |
| высказывание | Отдельные высказывания из EmotionLines в виде строки. |
| Спикер | Имя говорящего, связанное с высказыванием. |
| Эмоции | Эмоция (нейтральная, радость, печаль, гнев, удивление, страх, отвращение), выраженная говорящим в высказывании. |
| Настроение | Настроение (положительное, нейтральное, отрицательное), выраженное говорящим в высказывании. |
| ID_диалога | Индекс диалога начиная с 0. |
| ID высказывания_ID | Индекс конкретного высказывания в диалоге начиная с 0. |
| Сезон | Сезон №. телешоу «Друзья», к которому принадлежит конкретное высказывание. |
| Эпизод | Эпизод №. телешоу «Друзья» в конкретном сезоне, к которому относится высказывание. |
| Время начала | Время начала высказывания в данном эпизоде в формате «чч:мм:сс,мс». |
| Время окончания | Время окончания высказывания в данном эпизоде в формате «чч:мм:сс,мс». |
Существует 13 файлов Pickle, содержащих данные и функции, используемые для обучения базовых моделей. Ниже приводится краткое описание каждого файла Pickle.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))В «./utils/» есть два скрипта Python:
Для эксперимента все метки представлены в виде one-hot кодировок, индексы для которых следующие:
Для базовой классификации эмоций использовались следующие веса классов. Индексация такая же, как указано выше. Веса классов: [4,0, 15,0, 15,0, 3,0, 1,0, 6,0, 3,0].
Пожалуйста, выполните следующие действия, чтобы запустить базовый уровень:
./data/pickles/baseline/baseline.py следующим образом:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h чтобы получить текст справки для параметров../data/models/ . Пожалуйста, процитируйте следующие статьи, если вы найдете этот набор данных полезным в вашем исследовании.
С. Пориа, Д. Хазарика, Н. Маджумдер, Г. Найк, Э. Камбрия, Р. Михалча. MELD: мультимодальный многосторонний набор данных для распознавания эмоций в разговоре. АКЛ 2019.
Чен, С.Ю., Сюй, К.С., Куо, К.С. и Ку, Л.В. EmotionLines: Корпус эмоций многосторонних разговоров. Препринт arXiv arXiv:1802.08379 (2018).
Мультимодальный набор данных EmoryNLP Emotion Detection был создан путем улучшения и расширения набора данных EmoryNLP Emotion Detection. Он содержит те же экземпляры диалогов, что и набор данных EmoryNLP Emotion Detection, но наряду с текстом включает в себя аудио- и визуальную модальность. В мультимодальном наборе данных EmoryNLP содержится более 800 диалогов и 9000 высказываний из сериала «Друзья». В диалогах приняли участие несколько спикеров. Каждое высказывание в диалоге было отмечено любой из этих семи эмоций: нейтральной, радостной, мирной, мощной, испуганной, безумной и грустной. Аннотации заимствованы из исходного набора данных.
| Статистика | Тренироваться | Дев | Тест |
|---|---|---|---|
| # модальности | {а,в,т} | {а,в,т} | {а,в,т} |
| # уникальных слов | 9,744 | 2123 | 2345 |
| Среднее длина высказывания | 7,86 | 6,97 | 7,79 |
| Макс. длина высказывания | 78 | 60 | 61 |
| Среднее Количество эмоций в сцене | 4.10 | 4.00 | 4.40 |
| количество диалогов | 659 | 89 | 79 |
| количество высказываний | 7551 | 954 | 984 |
| количество спикеров | 250 | 46 | 48 |
| # смены эмоций | 4596 | 575 | 653 |
| Среднее продолжительность высказывания | 5,55 с | 5,46 с | 5,27 с |
| Тренироваться | Дев | Тест | |
|---|---|---|---|
| Радостный | 1677 г. | 205 | 217 |
| Безумный | 785 | 97 | 86 |
| Нейтральный | 2485 | 322 | 288 |
| Мирный | 638 | 82 | 111 |
| Мощный | 551 | 70 | 96 |
| Грустно | 474 | 51 | 70 |
| Испуганный | 941 | 127 | 116 |
Видеоклипы этого набора данных можно скачать по этой ссылке. Файлы аннотаций можно найти по адресу https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Есть 3 файла .csv. Каждая запись в первом столбце этих CSV-файлов содержит высказывание, соответствующий видеоклип которого можно найти здесь. Каждое высказывание и его видеоклип индексируются по номеру сезона, номеру эпизода, идентификатору сцены и идентификатору высказывания. Например, sea1_ep2_sc6_utt3.mp4 подразумевает, что клип соответствует высказыванию с номером сезона. 1, серия №. 2, Scene_id 6 и utterance_id 3. Сцена — это просто диалог. Эта индексация соответствует исходному набору данных. Файлы .csv и видеофайлы разделены на обучающий, проверочный и тестовый наборы в соответствии с исходным набором данных. Аннотации были напрямую заимствованы из исходного набора данных EmoryNLP (Захири и др. (2018)).
| Имя столбца | Описание |
|---|---|
| высказывание | Отдельные высказывания из EmoryNLP в виде строки. |
| Спикер | Имя говорящего, связанное с высказыванием. |
| Эмоции | Эмоция (Нейтральная, Радостная, Мирная, Сильная, Испуганная, Безумная и Грустная), выраженная говорящим в высказывании. |
| Идентификатор_сцены | Индекс диалога начиная с 0. |
| ID высказывания_ID | Индекс конкретного высказывания в диалоге начиная с 0. |
| Сезон | Сезон №. телешоу «Друзья», к которому принадлежит конкретное высказывание. |
| Эпизод | Эпизод №. телешоу «Друзья» в конкретном сезоне, к которому относится высказывание. |
| Время начала | Время начала высказывания в данном эпизоде в формате «чч:мм:сс,мс». |
| Время окончания | Время окончания высказывания в данном эпизоде в формате «чч:мм:сс,мс». |
Примечание . Для некоторых высказываний нам не удалось определить время начала и окончания из-за некоторых несоответствий в субтитрах. Такие высказывания были исключены из набора данных. Тем не менее, мы рекомендуем пользователям находить соответствующие высказывания в исходном наборе данных и создавать для них видеоклипы.
Пожалуйста, процитируйте следующие статьи, если вы найдете этот набор данных полезным в вашем исследовании.
С. Захири и Дж. Д. Чой. Обнаружение эмоций в стенограммах телешоу с помощью сверточных нейронных сетей на основе последовательностей. На семинаре AAAI по анализу аффективного контента, AFFCON'18, 2018.
С. Пориа, Д. Хазарика, Н. Маджумдер, Г. Найк, Э. Камбрия, Р. Михалча. MELD: мультимодальный многосторонний набор данных для распознавания эмоций в разговоре. АКЛ 2019.


