ChatLearner
1.0.0
Чат-бот, реализованный в TensorFlow на основе новой модели «последовательность-последовательность» (NMT), с легко интегрированными определенными правилами.
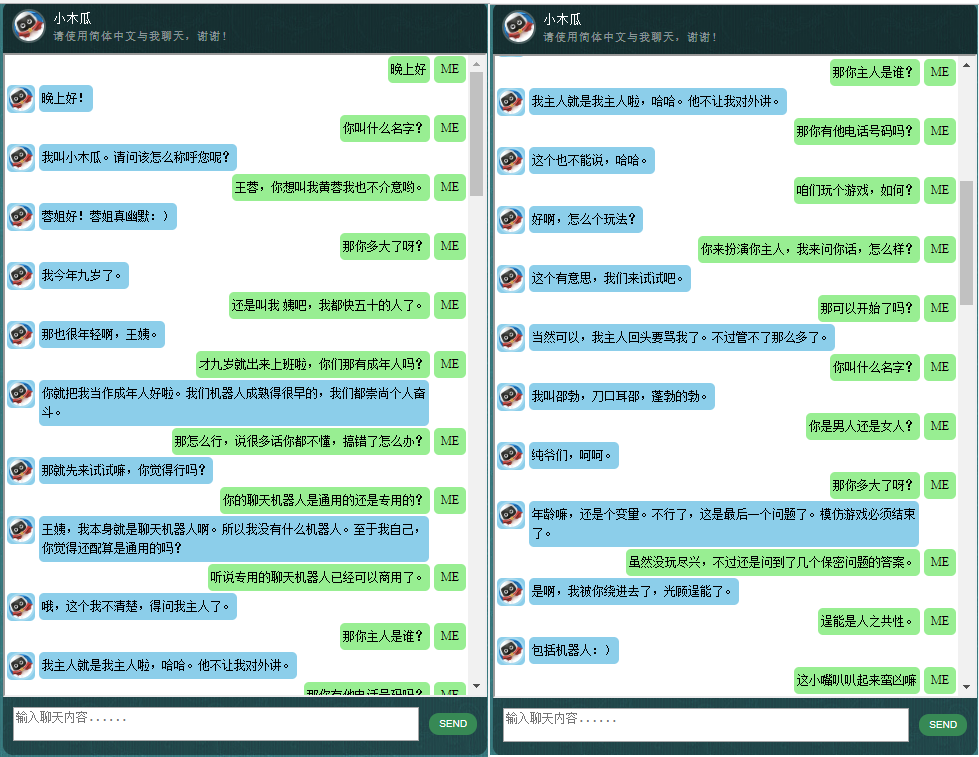
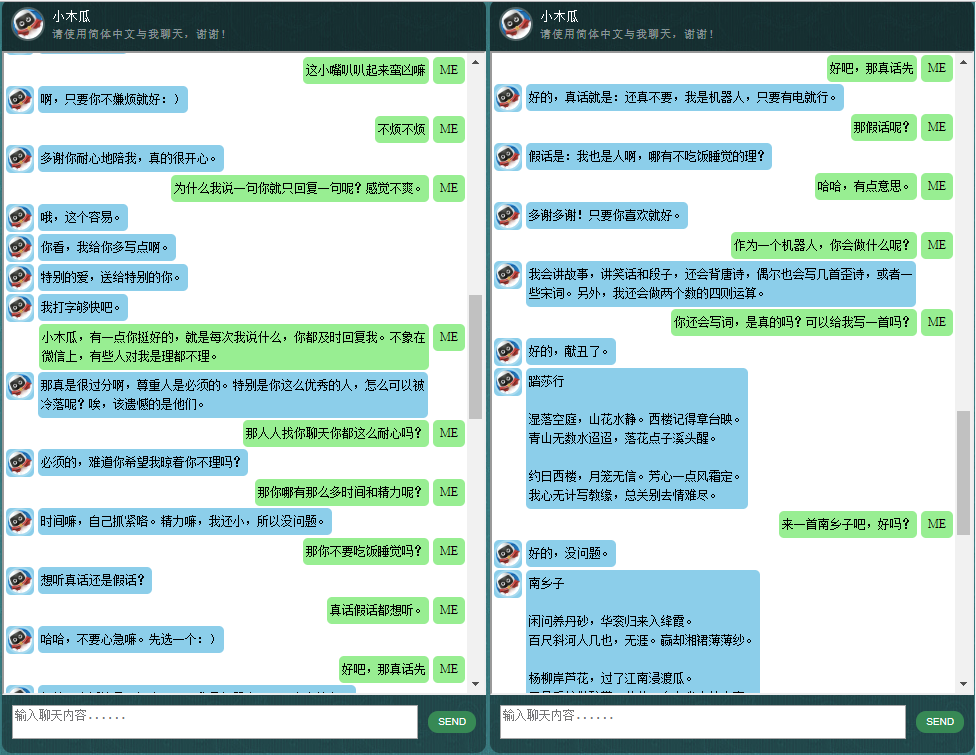
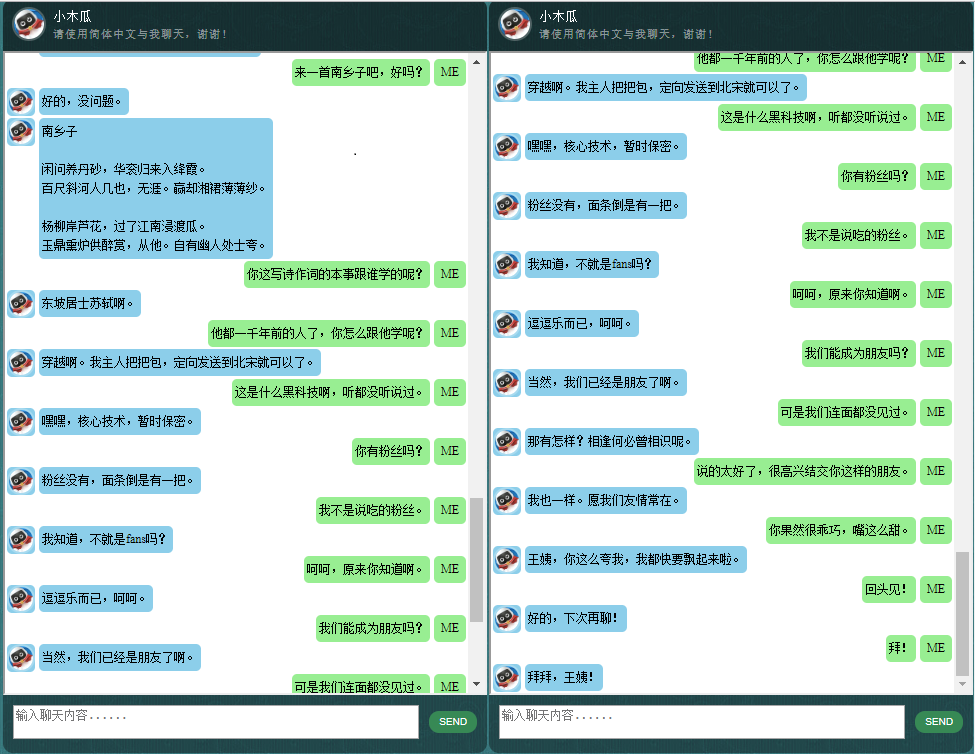
Тех, кого интересуют чат-боты на китайском языке, можно найти здесь.
Ядро ChatLearner (Papaya) построено на модели NMT (https://github.com/tensorflow/nmt), которая здесь адаптирована под нужды чат-бота. Из-за изменений, внесенных в API tf.data в TensorFlow 1.4, и многих других изменений со времени TensorFlow 1.12, эта версия ChatLearner поддерживает только TF версий с 1.4 по 1.11. Простые обновления можно внести в файл tokenizeddata.py, если вам нужна поддержка TensorFlow 1.12.
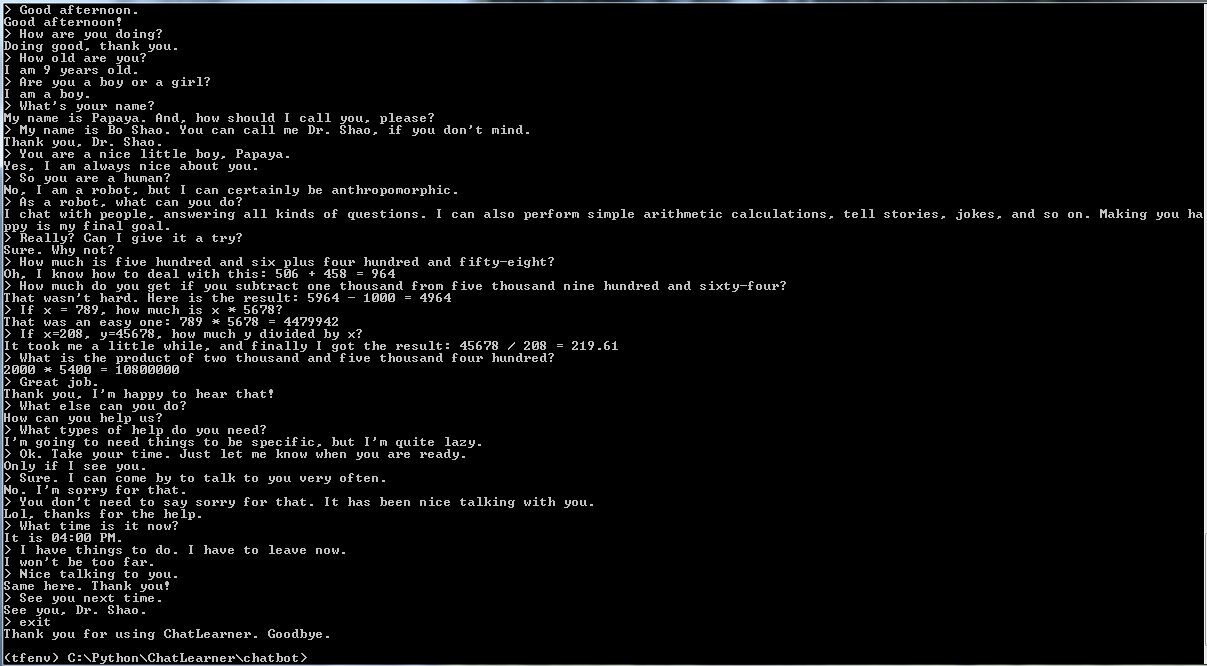
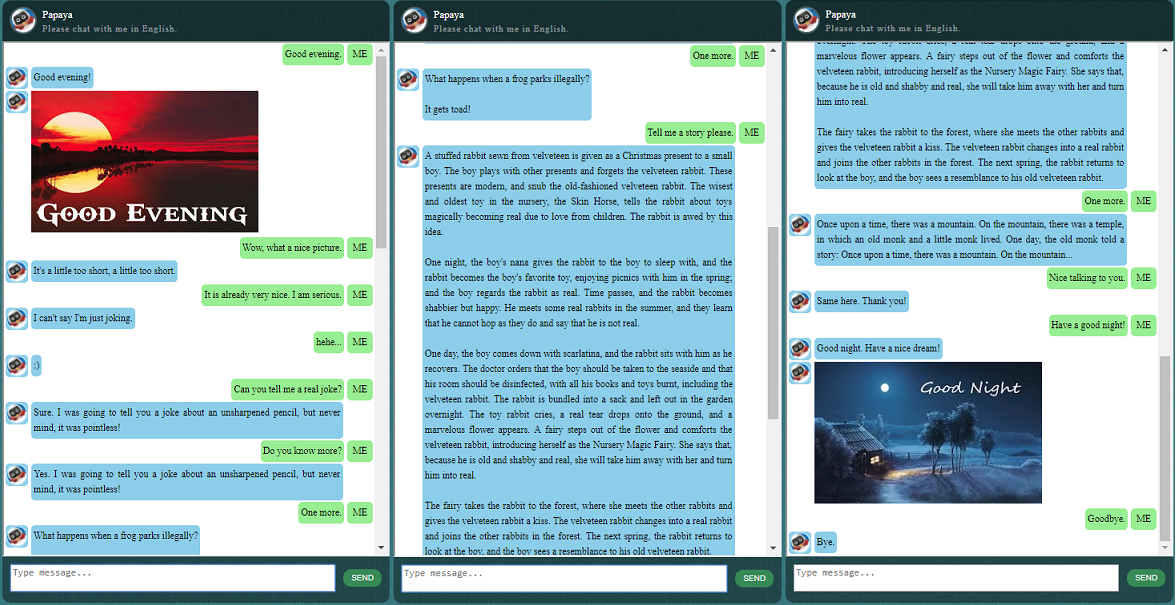
Прежде чем приступать ко всему остальному, возможно, вам захочется понять, как ведет себя ChatLearner. Взгляните на образец разговора ниже или здесь. Если вы предпочитаете попробовать мою обученную модель, загрузите ее здесь. Разархивируйте загруженный файл .rar и скопируйте папку «Результат» в папку «Данные» в корне вашего проекта. Также включен файл vocab.txt на случай, если я обновлю его без обновления обученной модели в будущем.
Почему вы хотите тратить время на проверку этого репозитория? Вот некоторые возможные причины:
Набор данных Papaya для обучения чат-бота. Вы можете легко найти массу данных для тренировок в Интернете, но вы не сможете найти их такого высокого качества. Подробное описание набора данных смотрите ниже.
Лаконичный стиль кода и четкая реализация новой модели seq2seq, основанной на динамической RNN (она же новая модель NMT). Он настроен для чат-ботов и намного проще для понимания по сравнению с официальным руководством.
Идея использования легко интегрированного ChatSession для обработки основного контекста разговора.
Некоторые правила интегрированы, чтобы продемонстрировать, как сочетать традиционные чат-боты, основанные на правилах, с новыми моделями глубокого обучения. Какой бы мощной ни была модель глубокого обучения, она не может ответить даже на вопросы, требующие простых арифметических вычислений и многих других. Продемонстрированный здесь подход можно легко адаптировать для получения новостей или другой онлайн-информации. Благодаря внедрению правил он сможет правильно ответить на многие интересные вопросы. Например:
Если вас не интересуют правила, вы можете легко удалить строки, относящиеся к Knowledgebase.py и functiondata.py.
Веб-служба на основе SOAP (и альтернатива на основе REST-API, если вы не хотите использовать SOAP) позволяет вам представить графический интерфейс на Java, в то время как модель обучается и работает на Python и TensorFlow.
Простое решение (в графе) для преобразования тензора строки в нижний регистр в TensorFlow. Это необходимо, если вы используете новый API DataSet (tf.data.TextLineDataSet) в TensorFlow для загрузки обучающих данных из текстовых файлов.
Репозиторий также содержит реализацию чат-бота, основанную на устаревшей модели seq2seq. Если вас это интересует, посетите ветку Legacy_Chatbot по адресу https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
Набор данных Papaya — это лучшие (самые чистые и хорошо организованные) бесплатные разговорные данные на английском языке, которые вы можете найти в Интернете для обучения чат-бота. Вот некоторые подробности:
Данные состоят из двух наборов: первый набор был создан вручную, и мы создали образцы для того, чтобы поддерживать постоянную роль чат-бота, которого, следовательно, можно научить быть вежливым, терпеливым, юмористическим, философским и осознавать, что он робот, но притворяющийся 9-летним мальчиком по имени Папайя; второй набор был удален из некоторых онлайн-ресурсов, включая сценарии разговоров, предназначенные для обучения роботов, диалоги из фильмов Корнелла, а также очищенные данные Reddit.
Набор обучающих данных разделен на три категории: два подмножества будут дополняться/повторяться во время обучения с разными уровнями или временем, а третий — нет. Расширенные подмножества предназначены для обучения модели правилам, которым необходимо следовать, а также некоторым знаниям и здравому смыслу, тогда как третье подмножество предназначено просто для помощи в обучении языковой модели.
Диалоги сценариев были извлечены и реорганизованы с http://www.eslfast.com/robot/. Если ваша модель может поддерживать контекст, она будет работать намного лучше, используя эти диалоги.
Исходный набор данных Корнелла можно найти здесь. Мы чистили его с помощью Python-скрипта (скрипт также можно найти в папке Corpus); затем мы очистили его вручную, быстро выполнив поиск по определенным шаблонам.
Для данных Reddit в этот репозиторий включено очищенное подмножество (около 110 тысяч пар). Файл словаря и параметры модели создаются и настраиваются на основе всех включенных файлов данных. Если вам нужен больший набор, вы также можете найти скрипты для анализа и очистки комментариев Reddit в папке Corpus/RedditData. Чтобы использовать эти скрипты, вам необходимо загрузить торрент комментариев Reddit по торрент-ссылке здесь. Обычно одного месяца комментариев достаточно (примерно можно сгенерировать 3 миллиона пар обучающих выборок). Вы можете настроить параметры скриптов в соответствии с вашими потребностями.
Файлы данных в этом наборе данных уже предварительно обработаны с помощью токенизатора NLTK, поэтому их можно использовать в модели с использованием нового API tf.data в TensorFlow.
Убедитесь, что у вас установлена правильная версия TensorFlow. Он работает только с TensorFlow 1.4, а не с более ранними выпусками, поскольку используемый здесь API tf.data был недавно обновлен в TF 1.4.
Убедитесь, что у вас настроена переменная среды PYTHONPATH. Он должен указывать на корневой каталог проекта, в котором у вас есть чат-бот, данные и папка webui. Если вы работаете в IDE, например PyCharm, он создаст это за вас. Но если вы запускаете какие-либо скрипты Python в командной строке, вам необходимо иметь эту переменную среды, иначе вы получите ошибки импорта модуля.
Убедитесь, что вы используете один и тот же файл vocab.txt как для обучения, так и для вывода/прогнозирования. Имейте в виду, что ваша модель никогда не увидит слов так, как мы. Это все целые числа на входе и на выходе, а слова и их порядок в vocab.txt помогают сопоставлять слова и целые числа.
Потратьте немного времени на размышления о том, насколько большой должна быть ваша модель, какова должна быть максимальная длина кодера/декодера, размер словарного набора и сколько пар обучающих данных вы хотите использовать. Имейте в виду, что у модели есть предел емкости: сколько данных она может запомнить или запомнить. Когда у вас есть фиксированное количество слоев, количество модулей, тип ячейки RNN (например, GRU) и вы выбрали длину кодера/декодера, на способность вашей модели к обучению влияет в основном размер словаря, а не количество обучающие образцы. Если вам удастся не допустить увеличения размера словарного запаса при использовании большего количества обучающих данных, это, вероятно, сработает, но реальность такова, что когда у вас больше обучающих выборок, размер словарного запаса также увеличивается очень быстро, и вы можете заметить ваша модель вообще не может вместить такой размер данных. Если хотите, смело открывайте тему для обсуждения.
Кроме Python 3.6 (3.5 тоже должно работать), Numpy и TensorFlow 1.4. Вам также понадобится NLTK (Natural Language Toolkit) версии 3.2.4 (или 3.2.5).
Во время обучения я действительно предлагаю вам попробовать поиграть с параметром (colocate_gradients_with_ops) в функции tf.gradients. Вы можете найти такую строку в modelcreator.py: градиенты = tf.gradients(self.train_loss, params). Установите colocate_gradients_with_ops=True (добавив его) и запустите обучение хотя бы для одной эпохи, запишите время, а затем установите для него значение False (или просто удалите его), запустите обучение хотя бы для одной эпохи и посмотрите, требуется ли время для одной эпохи существенно различаются. По крайней мере меня это шокирует.
В остальном обучение простое. Не забудьте сначала создать папку с именем «Результат» в папке «Данные». Затем просто выполните следующие команды:
cd chatbot
python bottrainer.pyДля обучения настоятельно рекомендуется использовать хорошие графические процессоры, поскольку оно может занять очень много времени. Если у вас несколько графических процессоров, память всех графических процессоров будет использоваться TensorFlow, и вы можете соответствующим образом настроить параметр пакетного размера в файле hparams.json, чтобы полностью использовать память. Вы сможете увидеть результаты обучения в папке Data/Result/. Убедитесь, что существуют следующие два файла, поскольку все они потребуются для тестирования и прогнозирования (мета-файл не является обязательным, поскольку модель вывода будет создана независимо):
Для тестирования и прогнозирования мы предоставляем простой командный интерфейс и веб-интерфейс. Обратите внимание, что для вывода также необходим файл vocab.txt (и файлы в базе знаний для этого чат-бота). Чтобы быстро проверить, как работает обученная модель, используйте следующий командный интерфейс:
cd chatbot
python botui.pyПодождите, пока не появится командная строка «>».
Также предоставляется результат демо-теста. Пожалуйста, проверьте это, чтобы увидеть, как этот чат-бот ведет себя сейчас: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Реализована архитектура веб-служб на основе SOAP с сервером Python и клиентом Java. Для справки также включен приятный графический интерфейс. Подробную информацию можно найти по адресу: https://github.com/bshao001/ChatLearner/tree/master/webui. Обратите внимание, что определенная информация (например, изображения) доступна только в веб-интерфейсе (а не в интерфейсе командной строки).
Альтернатива на основе REST-API также предоставляется, если SOAP не является вашим выбором. Подробную информацию можно найти по адресу: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Некоторые из последних обновлений могут быть недоступны при использовании этой опции. Объедините изменения из другого варианта, если вам нужно использовать этот.
NLP Markup Framework — это инфраструктура разметки NLP. (自然语言处理标记框架)多对话中的复杂的上下文相关问题。本方法尤其适用于商业上的专用(面向任务的)聊天机器人的开发,比如售前,售后,或特定领域(如法律,医疗)的技术咨询服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami