Dialog
1.0.0
Dialog — японский проект чат-бота.
В этом проекте используется архитектура EncoderDecoder, включающая BERT-кодер и трансформатор-декодер.
Статья написана на японском языке.
Вы можете запустить сценарий обучения и оценки в Google Colab без создания среды.
Пожалуйста, нажмите следующую ссылку.
Обратите внимание, что в учебном блокноте команда загрузки описана в конце примечания, но она еще не проверена. Поэтому, если вы используете тренировочный блокнот и не можете загрузить файл тренированного веса, загрузите его вручную.
блог написан на японском языке
@ycat3 создал пример преобразования текста в речь, используя этот проект для генерации предложений и Parallel Wavenet для синтеза речи. Исходный код не является общедоступным, но вы можете воспроизвести его, если воспользуетесь Parallel Wavenet. В этом блоге есть несколько аудиосэмплов, поэтому попробуйте их послушать.
Я хотел бы создать приложение, позволяющее нам разговаривать с ИИ голосом, используя синтез речи и распознавание речи, если у меня много свободного времени, но сейчас я не могу это сделать из-за подготовки к экзаменам...
2 эпохи
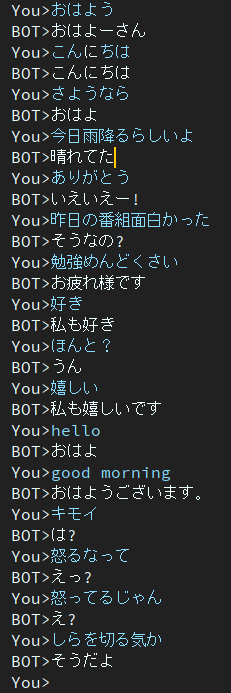
Эта модель все еще содержит проблему тупого отклика.
Чтобы решить эту проблему, я сейчас исследую.
Потом я обнаружил, что в статье рассматривается эта проблема.
Еще одна целевая функция, способствующая разнообразию, для генерации нейронного диалога
Авторы принадлежат Институту науки и технологий Нара, также известному как NAIST.
Они предлагают новую целевую функцию генерации нейронного диалога.
Я надеюсь, что этот метод поможет мне решить эту проблему.
на Гугл диске.
Необходимые пакеты есть
Если из-за пакетов возникают ошибки, установите отсутствующие пакеты.
Пример, если вы используете conda.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'если вы готовы начать обучение, запустите основной скрипт.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pyЕсли вы хотите получить больше данных о разговорах, используйте get_tweet.py.
Обратите внимание, что вам необходимо изменить Consumer_key и Access_Token, чтобы использовать этот скрипт.
Затем выполните следующие команды.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Если вы выполните команду «Пример», скрипт начнет собирать 5 последовательных предложений, если последнее предложение содержит «私は».
Однако вы устанавливаете 3 или более числа для «непрерывных высказываний», make_training_data.py автоматически создает пару высказываний.
Затем выполните следующую команду.
$ python make_training_data.pyЭтот скрипт создает данные обучения, используя «./data/tweet_data_*.txt», как и имя.
Кодировщик: БЕРТ
Декодер: декодер Vanilla Transformer
Потеря: Перекрестная Энтропия
Оптимизатор: AdamW
Токенизатор: BertJapaneseTokenizer
Если вам нужна дополнительная информация об архитектуре BERT или Transformer, обратитесь к следующей статье.


