Seq2seqChatbots
1.0.0
Обертка tensor2tensor для гибкого обучения, взаимодействия и генерации данных для нейронных чат-ботов.
Вики содержит мои заметки и резюме более 150 недавних публикаций, связанных с моделированием нейронных диалогов.
? Проводите собственные тренинги или экспериментируйте с предварительно обученными моделями.
✅ 4 различных набора данных диалогов, интегрированных с tensor2tensor
? Без проблем работает с любой моделью или гиперпараметром, установленным в tensor2tensor.
Легко расширяемый базовый класс для решения проблем с диалогами.
Запустите файл setup.py, который установит необходимые пакеты и поможет загрузить дополнительные данные:
python setup.py
Вы можете скачать все обученные модели, используемые в этой статье, здесь. Каждое обучение содержит две контрольные точки: одну для минимума потерь при проверке, а другую — через 150 эпох. Структура данных и папок тренингов точно совпадают.
python t2t_csaky/main.py --mode=train
Аргумент режима может быть одним из следующих четырех: {generate_data, train, decode, Experiment} . В режиме эксперимента вы можете указать, что делать, внутри функции эксперимента запускаемого файла. Ниже дано подробное объяснение того, что делает каждый режим.
Вы можете управлять флагами и параметрами каждого режима прямо в этом файле. Для каждого запуска, который вы инициируете, этот файл будет копироваться в соответствующий каталог, поэтому вы можете быстро получить доступ к параметрам любого запуска. Для каждого режима необходимо установить несколько флагов (словарь FLAGS в файле конфигурации):
t2t_usr_dir : путь к каталогу, в котором находится мой код. Вам не нужно это менять, если только вы не переименуете каталог.
data_dir : путь к каталогу, в котором вы хотите создать пары источника и цели, а также другие данные. Набор данных будет загружен на один уровень выше из этого каталога в папку raw_data .
проблема : это название зарегистрированной проблемы, которая нужна tensor2tensor. Подробно в разделеgener_data ниже. Все пути должны идти от корня репо.
В этом режиме данные загружаются и предварительно обрабатываются, а также создаются пары источника и цели. На данный момент зарегистрировано 6 задач, которые вы можете использовать помимо задач, предоставленных tensor2tensor:
persona_chat_chatbot : эта проблема реализует набор данных Persona-Chat (без использования персон).
daily_dialog_chatbot : эта проблема реализует набор данных DailyDialog (без использования тем, диалоговых действий или эмоций).
opensubtitles_chatbot : Эту проблему можно использовать для работы с набором данных OpenSubtitles.
cornell_chatbot_basic : Эта проблема реализует Корнеллский корпус диалогов фильмов.
cornell_chatbot_separate_names : в этой задаче используется тот же корпус Корнелла, однако имена говорящих и адресатов каждого высказывания добавляются, в результате чего исходные высказывания получаются, как показано ниже.
BIANCA_m0, что хорошего? КАМЕРОН_m0
character_chatbot : это общая проблема, связанная с персонажами, которая работает с любым набором данных. Прежде чем использовать это, файлы .txt, созданные в результате любой из вышеперечисленных проблем, должны быть помещены в каталог данных, и после этого эту проблему можно использовать для создания символьных файлов данных tensor2tensor.
Словарь PROBLEM_HPARAMS в файле конфигурации содержит параметры, специфичные для проблемы, которые вы можете установить перед созданием данных:
num_train_shards / num_dev_shards : если вы хотите, чтобы сгенерированные данные поезда или разработки были разбиты на несколько файлов.
словарь_размера : размер словаря, который мы хотим использовать для решения задачи. Слова за пределами этого словаря будут заменены токеном.
dataset_size : количество пар высказываний, если мы не хотим использовать полный набор данных (определяется 0).
dataset_split : укажите разделение train-val-test для проблемы.
dataset_version : это относится только к набору данных opensubtitles, поскольку существует несколько версий этого набора данных, вы можете указать год набора данных, который вы хотите загрузить.
name_vocab_size : Это относится только к проблеме Корнелла с отдельными именами. Вы можете установить размер словаря, содержащего только персонажей.
Этот режим позволяет обучать модель с заданной задачей и гиперпараметрами. Код просто вызывает сценарий обучения tensor2tensor, поэтому можно использовать любую модель, которая есть в tensor2tensor. Помимо этого, существует еще модель подкласса с небольшими модификациями:
gradient_checkpointed_seq2seq : небольшая модификация модели seq2seq на основе lstm, позволяющая полностью использовать собственные hparams. Перед расчетом softmax скрытые единицы LSTM прогнозируются до 2048 линейных единиц, как здесь. Наконец, я попытался реализовать контрольную точку градиента в этой модели, но в настоящее время она удалена, поскольку не дала хороших результатов.
Существует несколько дополнительных флагов, которые вы можете указать для обучающего прогона в словаре FLAGS в файле конфигурации, вот некоторые из них:
train_dir : Имя каталога, в котором будут сохранены файлы контрольных точек обучения.
model : Название модели: либо одна из вышеперечисленных, либо модель, определенная tensor2tensor.
hparams : укажите зарегистрированный hparams_set или оставьте пустым, если вы хотите определить hparams в файле конфигурации. Чтобы указать hparams для модели seq2seq или модели преобразователя , вы можете использовать словари SEQ2SEQ_HPARAMS и TRANSFORMER_HPARAMS в файле конфигурации (проверьте его для получения более подробной информации).
В этом режиме вы можете декодировать обученные модели. На декодирование влияют следующие параметры (в словаре FLAGS в файле конфигурации):
decode_mode : может быть интерактивным , где вы можете общаться с моделью, используя командную строку. Режим файла позволяет вам указать файл с исходными высказываниями, для которых будут генерироваться ответы, а режим набора данных будет случайным образом выбирать предоставленные данные проверки и выводить ответы.
decode_dir : каталог, в котором вы можете предоставить файл для декодирования, и здесь будут сохраняться выведенные ответы.
input_file_name : Имя файла, которое вы должны указать в файловом режиме (помещается в decode_dir ).
имя_файла_выходного_файла : Имя файла внутри decode_dir , в котором будут сохранены выходные ответы.
Beam_size : Размер луча при использовании поиска луча.
return_beams : если значение равно False, возвращается только верхняя балка, в противном случае возвращается количество балок beam_size .
Следующие результаты взяты из этих двух статей.
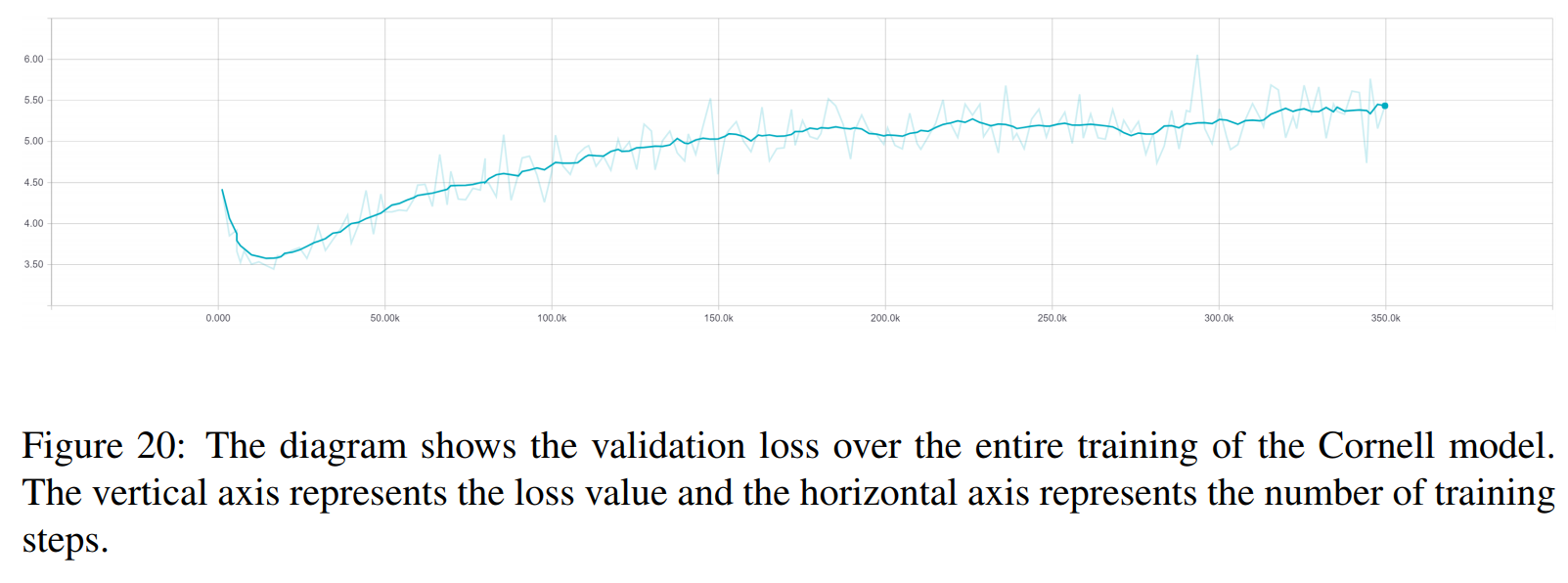

TRF — это модель Трансформера, RT означает случайно выбранные ответы из обучающего набора, а GT означает достоверные ответы. Объяснение показателей см. в статье.
S2S — это простая модель seq2seq с LSTM, обученными на Cornell, другие — модели Transformer. Opensubtitles F предварительно обучен на Opensubtitles и настроен на Cornell. 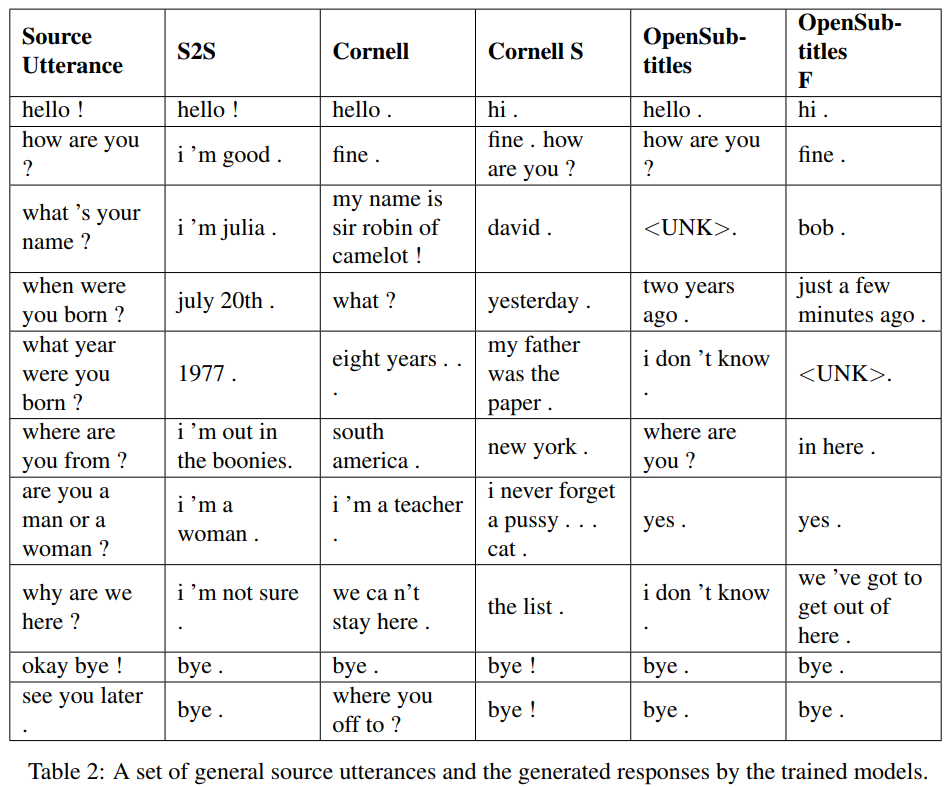
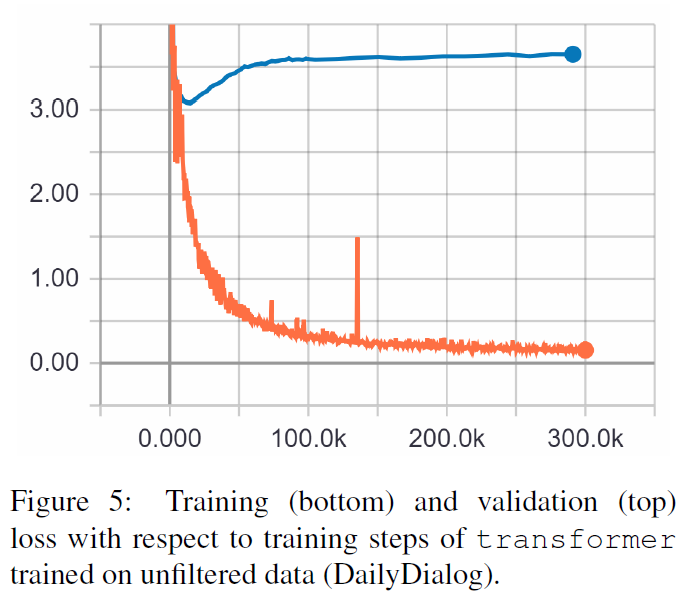

TRF — это модель Трансформера, RT означает случайно выбранные ответы из обучающего набора, а GT означает достоверные ответы. Объяснение показателей см. в статье.
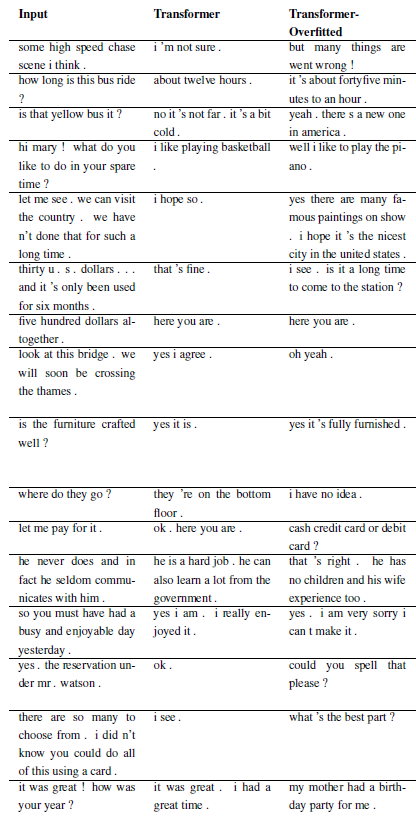
Новые проблемы можно зарегистрировать путем создания подкласса WordChatbot или, что еще лучше, создания подкласса CornellChatbotBasic или OpensubtitleChatbot, поскольку они реализуют некоторые дополнительные функции. Обычно достаточно переопределить функции preprocess и create_data . Дополнительную информацию можно найти в документации, а пример можно найти в daily_dialog_chatbot.
Новые модели и гиперпараметры можно добавить, следуя руководству tensor2tensor.
Ричард Чаки (если вам нужна помощь с запуском кода: [email protected])
Этот проект лицензируется по лицензии MIT — подробности см. в файле LICENSE.
Пожалуйста, укажите ссылку на этот репозиторий, если вы используете его в своей работе, и рассмотрите возможность цитирования следующей статьи:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

