turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) — это решение с открытым исходным кодом (https://github.com/openturing), основными функциями которого являются семантическая навигация и чат-бот. Вы можете выбрать один из нескольких НЛП для обогащения данных. Весь контент индексируется в Solr как поисковой системе.
Техническая документация по Turing ES доступна по адресу https://openviglet.github.io/docs/turing/.
Чтобы запустить Turing ES, просто выполните следующие строки:
# Turing Appmvn -Dmaven.repo.local=D:repo Spring-Boot:run -pl turing-app -Dskip.npm# Новый пользовательский интерфейс Turing ES с использованием Angular 18 и Primer CSS.cd turing-ui## Loginng service Welcome## Консольное обслуживание console## Поисковое обслуживание sn## Чат-бот, обслуживание обратных сообщений
Вы можете запустить Turing ES, используя MariaDB, Solr и Nginx.
докер-составить
Консоль администрирования: http://localhost:2700. (админ/админ)
Пример семантической навигации: http://localhost:2700/sn/Sample.
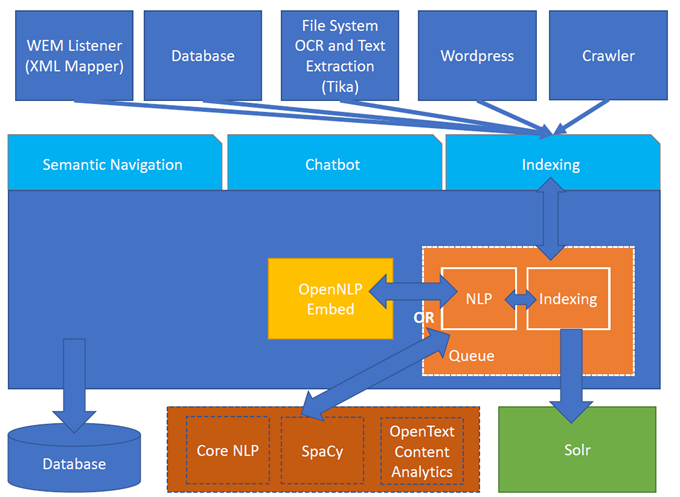
Рисунок 1. Архитектура Turing ES
Turing поддерживает следующих поставщиков:
Apache OpenNLP — это набор инструментов на основе машинного обучения для обработки текста на естественном языке.
Веб-сайт: https://opennlp.apache.org/.
Он преобразует данные в ценную информацию для более эффективного принятия решений и управления информацией, одновременно высвобождая ресурсы и время.
Сайт: https://www.opentext.com/.
CoreNLP — это универсальный магазин для обработки естественного языка на Java! CoreNLP позволяет пользователям получать лингвистические аннотации к тексту, включая границы токенов и предложений, части речи, именованные объекты, числовые значения и значения времени, анализ зависимостей и групп, кореференцию, тональность, атрибуцию цитат и отношения. CoreNLP в настоящее время поддерживает 6 языков: арабский, китайский, английский, французский, немецкий и испанский.
Веб-сайт: https://stanfordnlp.github.io/CoreNLP/,
Это бесплатная библиотека с открытым исходным кодом для обработки естественного языка в Python. Он включает в себя NER, теги POS, анализ зависимостей, векторы слов и многое другое.
Сайт: https://spacy.io.
Polyglot — это конвейер естественного языка, поддерживающий массовые многоязычные приложения.
Сайт: https://polyglot.readthedocs.io.
Он может читать PDF-файлы и документы и конвертировать их в обычный текст, а также использует OCR для обнаружения текста в изображениях и изображений в документах.
Семантическая навигация использует соединители для индексации контента из многих источников.
Плагин для Apache Nutch для индексации контента с помощью сканера.
Узнайте больше на https://docs.viglet.com/turing/connectors/#nitch.
Командная строка, использующая ту же концепцию, что и sqoop (https://sqoop.apache.org/), для создания сложных запросов и сопоставления атрибутов для индексации на основе результата.
Узнайте больше на https://docs.viglet.com/turing/connectors/#database.
Командная строка для индексации файлов, извлечения текста из таких файлов, как Word, Excel, PDF, включая изображения, посредством оптического распознавания символов.
Узнайте больше на https://docs.viglet.com/turing/connectors/#file-system.
OpenText WEM Listener для публикации контента в Виглет Тьюринг.
Узнайте больше на https://docs.viglet.com/turing/connectors/#wem.
Плагин WordPress, который позволяет индексировать сообщения.
Узнайте больше на https://docs.viglet.com/turing/connectors/#wordpress.
С помощью НЛП можно обнаружить такие сущности, как:
Люди
Места
Организации
Деньги
Время
Процент
Определите атрибуты, которые будут использоваться в качестве фильтров для вашей навигации, объединяя весь контент на вашем дисплее.
С помощью атрибутов, определенных в содержимом, можно использовать их для ограничения их отображения на основе профиля пользователя.
Java API (https://github.com/openturing/turing-java-sdk) упрощает использование и доступ к Viglet Turing ES без необходимости поиска потребителями контента со сложными запросами.
Общайтесь со своим клиентом и разрабатывайте сложные намерения, получайте отчеты и постепенно развивайте свое взаимодействие.
Его компоненты:
Обрабатывает разговоры с конечными пользователями. Это модуль обработки естественного языка, который понимает нюансы человеческого языка.
Намерение классифицирует намерение конечного пользователя изменить разговор. Для каждого агента вы определяете несколько намерений, где ваши объединенные намерения могут обрабатывать весь разговор.
Поле действия — это простое поле удобства, помогающее реализовать логику в сервисе.
Каждый параметр намерения имеет тип, называемый типом сущности, который точно определяет, как извлекаются данные в выражении конечного пользователя.
Определяет и корректирует намерения.
Показывает историю разговоров и отчеты.
Turing ES обнаруживает объекты документов OpenText Blazon с помощью оптического распознавания символов и NLP, генерируя XML-код Blazon для отображения объектов в документе.
Turing ES состоит из множества компонентов: поисковая система, НЛП, Converse (чат-бот), семантическая навигация.
При доступе к Turing ES появится страница входа в систему. По умолчанию логин/пароль admin / admin
Рисунок 2. Страница входа в систему
Поисковая система используется Тьюрингом для хранения и получения данных Converse (чат-бот) и сайтов семантической навигации.
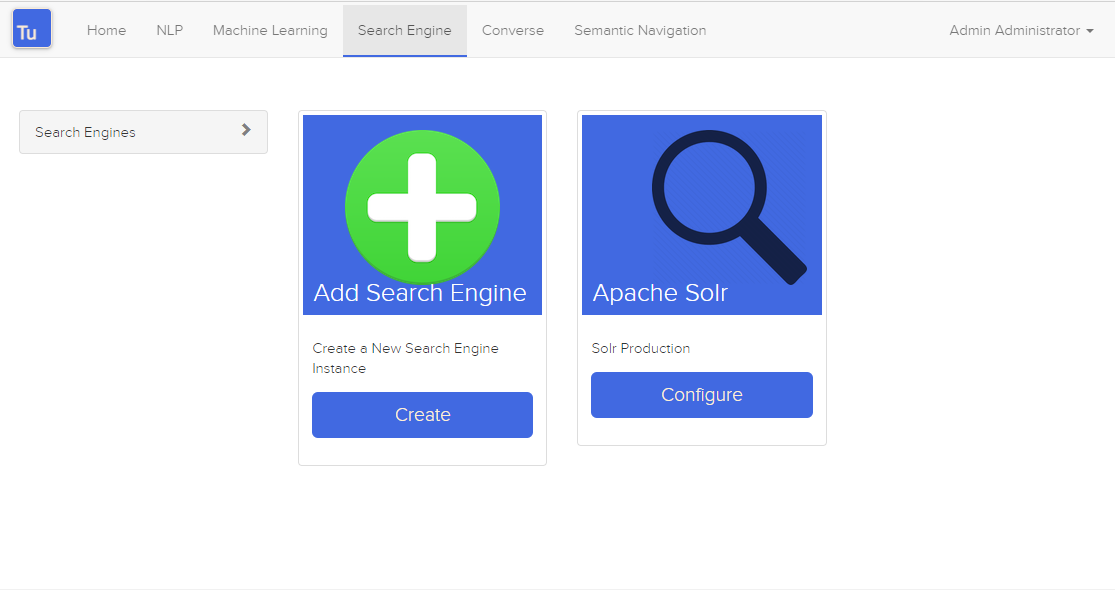
Рисунок 3. Страница поисковой системы
Можно создать или изменить поисковую систему со следующими атрибутами:
| Атрибут | Описание |
|---|---|
Имя | Название поисковой системы |
Описание | Описание поисковой системы |
Продавец | Выберите поставщика поисковой системы. На данный момент он поддерживает только Solr. |
Хозяин | Имя хоста, на котором установлена служба поисковой системы. |
Порт | Порт службы поисковых систем |
Язык | Язык службы поисковой системы. |
Включено | Если поисковая система включена. |
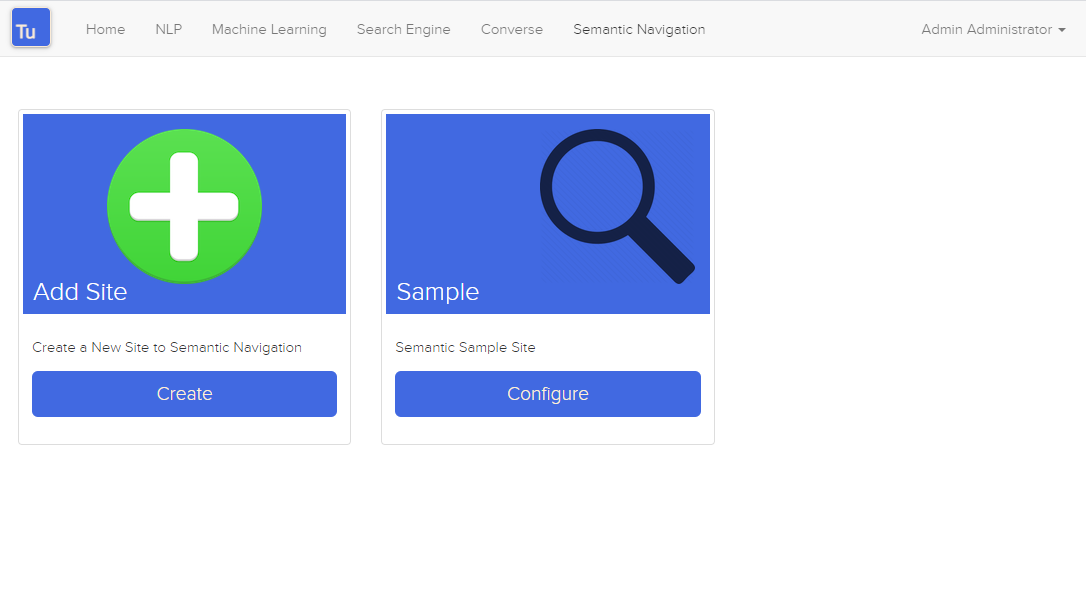
Рисунок 4. Страница семантической навигации
Деталь сайта семантической навигации содержит следующие атрибуты:
| Атрибут | Описание |
|---|---|
Имя | Название сайта семантической навигации. |
Описание | Описание сайта семантической навигации. |
Поисковая система | Выберите поисковую систему, созданную в разделе «Поисковая система». Сайт семантической навигации будет использовать эту поисковую систему для хранения и получения данных. |
НЛП | Выберите НЛП, созданный в разделе НЛП. Сайт семантической навигации будет использовать этот NLP для обнаружения объектов во время индексации. |
Тезаурус | Если вы используете Тезаурус. |
Язык | Язык семантической навигации сайта. |
Основной | Имя ядра поисковой системы, где будут храниться и извлекаться данные. |
Вкладка «Поля» содержит таблицу со следующими столбцами: Столбцы полей семантической навигации сайта.
| Имя столбца | Описание |
|---|---|
Тип | Тип поля. Это может быть: - NER (распознавание именованных объектов), используемый НЛП. - Поисковая система, используемая Solr. |
Поле | Имя поля. |
Включено | Включено ли поле или нет. |
МЛТ | Если это поле будет использоваться в MLT. |
Фасеты | Чтобы использовать это поле как фасет (фильтр) |
Выделение | Если в этом поле будут показаны выделенные строки. |
НЛП | Если это поле будет обработано NLP для обнаружения сущностей (NER), таких как люди, организации и места. |
При нажатии на поле появляется новая страница со сведениями о поле со следующими атрибутами:
| Атрибут | Описание |
|---|---|
Имя | Имя поля |
Описание | Описание поля |
Тип | Тип поля. Это может быть: |
Многозначный | Если это массив |
Имя фасета | Имя метки фасета (фильтра) на странице поиска. |
Фасет | Чтобы использовать это поле как фасет (фильтр) |
Выделение | Если в этом поле будут показаны выделенные строки. |
МЛТ | Если это поле будет использоваться в MLT. |
Включено | Если поле включено. |
Необходимый | Если поле обязательно. |
Значение по умолчанию | Если содержимое индексируется без этих полей, это значение по умолчанию. |
НЛП | Если это поле будет обработано NLP для обнаружения таких сущностей (NER), как люди, организации и места. |
Содержит следующие атрибуты:
| Раздел | Атрибут | Описание |
|---|---|---|
Появление | Количество элементов на странице | Количество элементов, которые будут отображаться в поиске. |
Фасет | Фасет включен? | Если будет показываться Фасет (Фильтры) при поиске. |
Количество элементов на фасет | Количество элементов, которые будут отображаться в каждом фасете (фильтре). | |
Выделение | Подсветка включена? | Определите, следует ли отображать выделенные строки. |
Предварительный тег | HTML-тег, который будет использоваться в начале семестра. Например: <отметка> | |
Тег сообщения | HTML-тег, который будет использоваться в конце семестра. Например: </mark> | |
МЛТ | Больше подобного включено? | Определите, показывать ли MLT |
Поля по умолчанию | Заголовок | Поле, которое будет использоваться в качестве заголовка, определенного в Solr Schema.xml. |
Текст | Поле, которое будет использоваться в качестве заголовка, определенного в Solr Schema.xml. | |
Описание | Поле, которое будет использоваться в качестве описания, определенного в Solr Schema.xml. | |
Дата | Поле, которое будет использоваться в качестве даты, определенной в Solr Schema.xml. | |
Изображение | Поле, которое будет использоваться в качестве URL-адреса изображения, определенного в Solr Schema.xml. | |
URL-адрес | Поле, которое будет использоваться в качестве URL-адреса, определенного в Solr Schema.xml. |
В Turing ES Console > Semantic Navigation > <SITE_NAME> нажмите кнопку Configure и нажмите кнопку Search Page .
Откроется страница поиска, использующая шаблон:
ПОЛУЧИТЕ http://localhost:2700/sn/<ИМЯ_САЙТА>
Эта страница запрашивает API Turing Rest через AJAX. Например, чтобы вернуть все результаты сайта семантической навигации в формате JSON:
GET http://localhost:2700/api/sn/<ИМЯ_САЙТА>/search?p=1&q=*&sort=relevance
| Атрибут | Обязательно/Необязательно | Описание | Пример |
|---|---|---|---|
д | Необходимый | Поисковый запрос. | q=фу |
п | Необходимый | Номер страницы, первая страница — 1. | р=1 |
сортировать | Необходимый | Сортировка значений: | сортировка = релевантность |
fq[] | Необязательный | Поле запроса. Фильтрация по полю, используя следующий шаблон: ПОЛЕ : ЗНАЧЕНИЕ . | fq[]=title:бар |
тр[] | Необязательный | Правило таргетинга. Ограничить поиск по следующим параметрам: ПОЛЕ : ЗНАЧЕНИЕ . | tr[]=отдел:foobar |
ряды | Необязательный | Количество строк, которые вернет запрос. | ряды=10 |
Во внутренней сети страховой компании используется OpenText WEM и OpenText Portal, интегрированный с модулем динамического портала, консолидированный поиск был создан в Viglet Turing ES с использованием коннекторов: WEM, База данных с файловой системой. Таким образом, можно было отображать все содержимое и файлы поисковой интрасети с правилами таргетинга, позволяющими отображать только тот контент, на который у пользователя есть разрешение. Портал OpenText обращается к Java API Viglet Turing ES, поэтому не нужно было создавать сложные запросы для возврата результатов.
Набор API Rest был создан, чтобы сделать весь контент государственных компаний доступным для партнеров. Все это содержимое находится в OpenText WEM, а соединитель WEM использовался для индексации содержимого в Viglet Turing ES. Приложение Spring Boot было создано с набором Rest API, которое использует контент Turing ES через Java API Viglet Turing ES.
Веб-сайт Бразильского университета был разработан с использованием CMS Viglet Shio (https://viglet.com/shio), и все содержимое автоматически индексируется в Viglet Turing ES. Данная конфигурация была выполнена при моделировании контента, а разработка шаблона поиска выполнена в Viglet Shio CMS.


