GenDataAttribution
1.0.0
Проект | Бумага
Шэн-Ю Ван 1 , Алексей А. Эфрос 2 , Цзюнь-Янь Чжу 1 , Ричард Чжан 3 .
Университет Карнеги-Меллон 1 , Калифорнийский университет в Беркли 2 , Adobe Research 2
В ICCV, 2023 г.
Хотя большие модели преобразования текста в изображение способны синтезировать «новые» изображения, эти изображения обязательно являются отражением обучающих данных. Проблема атрибуции данных в таких моделях (какие из изображений в обучающем наборе больше всего ответственны за появление данного сгенерированного изображения) является сложной, но важной. В качестве первого шага к решению этой проблемы мы оцениваем атрибуцию с помощью методов «кастомизации», которые настраивают существующую крупномасштабную модель на данный образцовый объект или стиль. Наша ключевая идея заключается в том, что это позволяет нам эффективно создавать синтетические изображения, на которые по конструкции влияет вычислительный образец. Благодаря нашему новому набору данных таких изображений, созданных под влиянием образцов, мы можем оценить различные алгоритмы атрибуции данных и различные возможные пространства признаков. Более того, обучаясь на нашем наборе данных, мы можем настроить стандартные модели, такие как DINO, CLIP и ViT, для решения проблемы атрибуции. Несмотря на то, что процедура настроена на небольшие наборы образцов, мы показываем обобщение на более крупные наборы. Наконец, принимая во внимание присущую задаче неопределенность, мы можем присвоить мягкие оценки атрибуции набору обучающих изображений.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh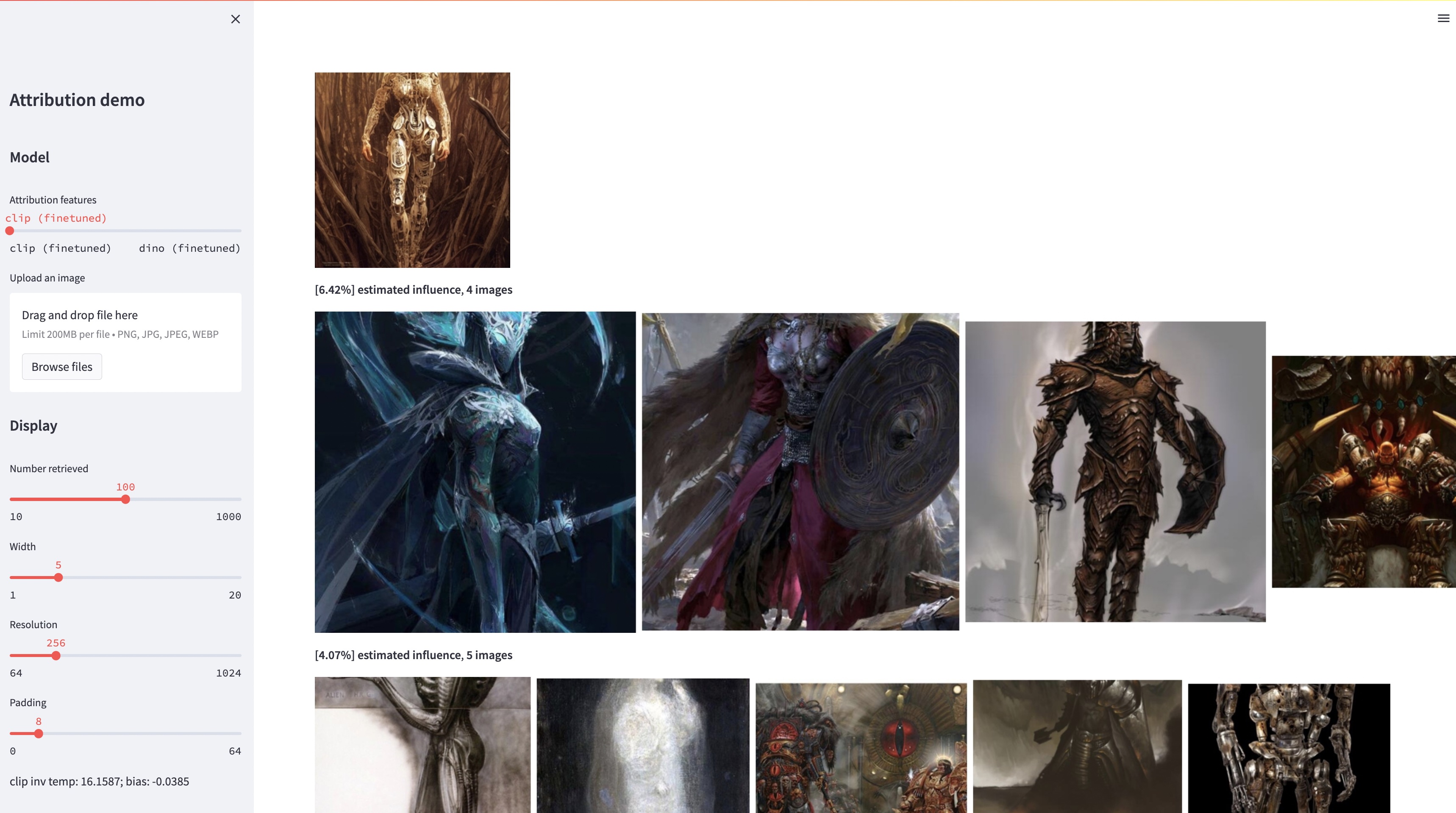
streamlit run streamlit_demo.pyМы выпускаем наш тестовый набор для оценки. Чтобы скачать набор данных:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionНабор данных структурирован следующим образом:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Все изображения-образцы хранятся в dataset/exemplar , все синтезированные изображения хранятся в dataset/synth , а изображения 1M laion в формате png хранятся в dataset/laion_subset . Файлы JSON в dataset/json определяют разделения train/val/test, включая различные тестовые примеры, и служат метками базовой истины. Каждая запись внутри файла JSON представляет собой уникальную точно настроенную модель. Запись также записывает образцы изображений, используемые для точной настройки, и синтезированные изображения, созданные моделью. У нас есть четыре тестовых примера: test_artchive.json , test_bamfg.json , test_observed_imagenet.json и test_unobserved_imagenet.json .
После загрузки набора тестов, предварительно вычисленных функций LAION и предварительно обученных весов мы можем предварительно вычислить функции из набора тестов, запустив extract_feat.py , а затем оценить производительность, запустив eval.py Ниже приведены сценарии bash, которые выполняют оценку в пакетном режиме:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh Метрики хранятся в файлах .pkl в results . В настоящее время сценарий выполняет каждую команду последовательно. Пожалуйста, не стесняйтесь изменять его для параллельного выполнения команд. Следующая команда преобразует файлы .pkl в таблицы, хранящиеся в виде файлов .csv :
python results_to_csv.py Обновление от 18 декабря 2023 г. Чтобы загрузить модели, обученные только на объектно-ориентированных или стильно-ориентированных моделях, запустите bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Мы благодарим Аарона Герцмана за прочтение предыдущего проекта и за содержательные отзывы. Мы благодарим коллег из Adobe Research, в том числе Эли Шехтмана, Оливера Вана, Ника Колкина, Тэсона Пака, Джона Колломоса и Сильвена Пэрис, а также Алекса Ли и Юнлун Тиана за полезное обсуждение. Мы благодарны Нупуру Кумари за руководство по обучению Custom Diffusion, Руйхану Гао за корректуру черновика, Алексу Ли за подсказки по извлечению признаков стабильной диффузии и Дэну Руте за помощь с набором данных BAM-FG. Мы благодарим Брайана Рассела за походы в связи с пандемией и мозговой штурм. Эта работа началась, когда SYW был стажером в Adobe, и частично поддерживалась подарком Adobe и премией факультета исследований JP Morgan Chase.


