clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Совместное использование высокопроизводительных графических процессоров или даже профессиональных и потребительских графических процессоров между несколькими пользователями — наиболее экономически эффективный способ ускорить разработку ИИ. К сожалению, до сих пор единственное существующее решение, применимое для высокопроизводительных графических процессоров MIG/Slicing (A100+) и требующее Kubernetes,
? Добро пожаловать в контейнерный дробный графический процессор для любой карты Nvidia! ?
Мы представляем предварительно упакованные контейнеры, поддерживающие CUDA 11.x и CUDA 12.x, со встроенным ограничением жесткой памяти! Это означает, что на одном и том же графическом процессоре можно запустить несколько контейнеров, гарантируя, что один пользователь не сможет выделить всю память графического процессора хоста! (Больше никаких жадных процессов, захватывающих всю память графического процессора! Наконец-то у нас есть опция жесткого ограничения памяти на уровне драйвера).
ClearML предлагает несколько вариантов оптимизации использования ресурсов графического процессора путем разделения графических процессоров:
Благодаря этим опциям ClearML позволяет выполнять рабочие нагрузки искусственного интеллекта с оптимизированным использованием оборудования и производительностью рабочих нагрузок. Этот репозиторий охватывает дробные графические процессоры на базе контейнеров. Дополнительную информацию о предложениях дробных графических процессоров ClearML см. в документации ClearML.
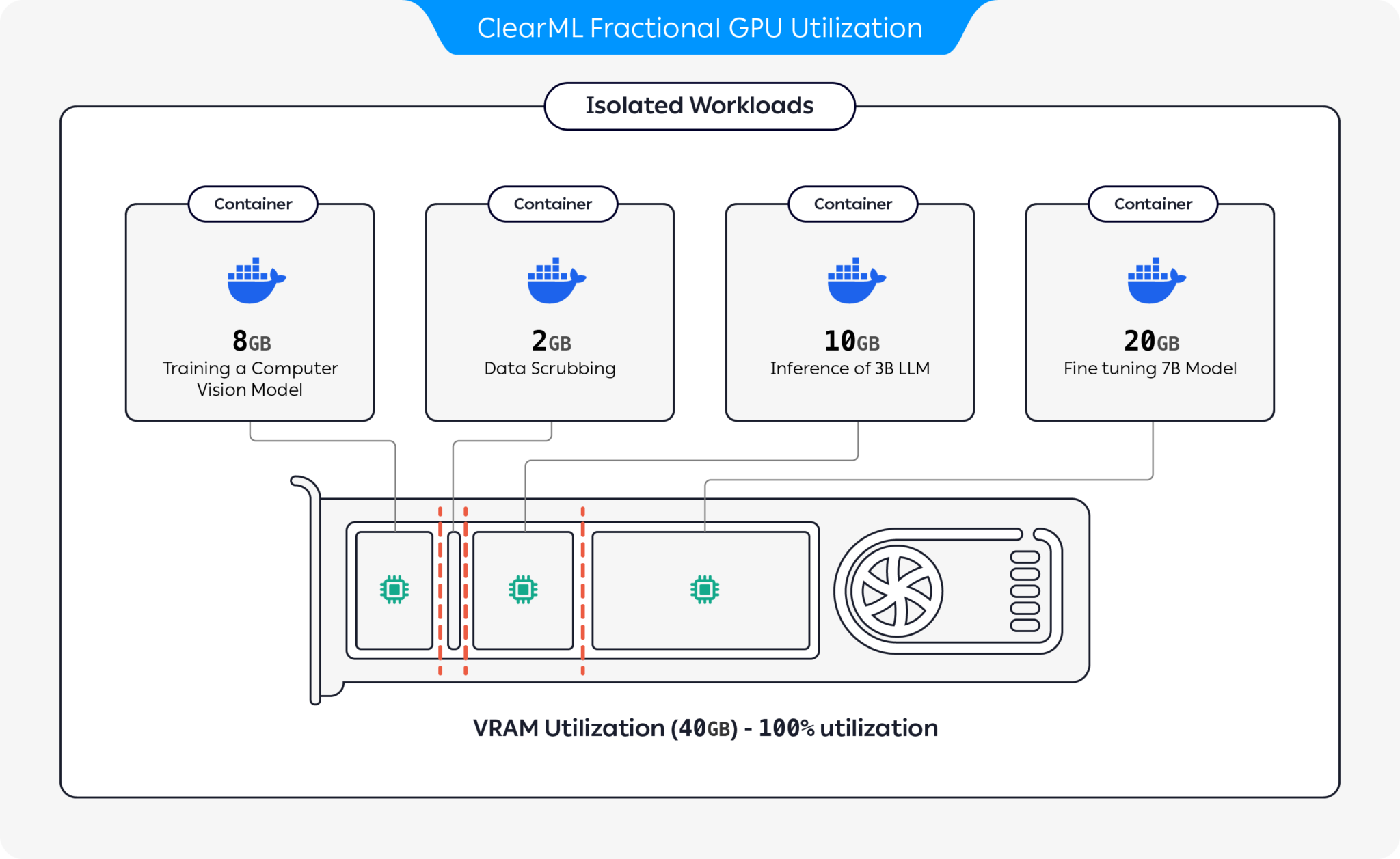
Выберите контейнер, который вам подходит, и запустите его:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashЧтобы убедиться, что ограничение дробной памяти графического процессора работает правильно, запустите внутри контейнера:
nvidia-smiВот пример вывода графического процессора A100:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Ограничение памяти | Версия CUDA | Убунту версия | Докер-образ |
|---|---|---|---|
| 12 ГиБ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 ГиБ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 ГиБ | 11,7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 ГиБ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 ГиБ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 ГиБ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 ГиБ | 11,7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 ГиБ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 ГиБ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 ГиБ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 ГиБ | 11,7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 ГиБ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 ГиБ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 ГиБ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 ГиБ | 11,7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 ГиБ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Важный
Вы должны запустить контейнер с --pid=host !
Примечание
--pid=host необходим, чтобы позволить драйверу различать процессы контейнера и другие процессы хоста при ограничении использования памяти/использования.
Кончик
Пользователи ClearML-Agent добавляют [--pid=host] в раздел agent.extra_docker_arguments вашего файла конфигурации.
Создавайте свои собственные контейнеры и наследуйте исходные контейнеры.
Несколько примеров вы можете найти здесь.
Контейнеры с дробным графическим процессором можно использовать в исполнениях на «голом железе», а также в POD Kubernetes. Да! Используя один из контейнеров Fractional GPU, вы можете ограничить потребление памяти вашим заданием/подом и легко совместно использовать графические процессоры, не опасаясь, что они вызовут сбой памяти друг у друга!
Вот простой шаблон POD Kubernetes:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Важный
Вы должны запустить модуль с hostPID: true !
Примечание
hostPID: true требуется, чтобы драйвер мог различать процессы модуля и другие процессы хоста при ограничении использования памяти/использования.
Контейнеры поддерживают драйверы Nvidia <= 545.xx Мы будем продолжать обновлять и поддерживать новые драйверы по мере их выпуска.
Поддерживаемые графические процессоры : серии RTX 10, 20, 30, 40, серии A и Data-Center P100, A100, A10/A40, L40/s, H100.
Ограничения : хост-компьютеры Windows в настоящее время не поддерживаются. Если для вас это важно, оставьте заявку в разделе «Вопросы».
Вопрос : Будет ли запуск nvidia-smi внутри контейнера сообщать о потреблении графического процессора локальными процессами?
О : Да, nvidia-smi напрямую взаимодействует с драйверами низкого уровня и сообщает как точную память графического процессора контейнера, так и ограничение локальной памяти контейнера.
Обратите внимание, что использование графического процессора будет глобальным (т. е. на стороне хоста), а не использованием графического процессора конкретного локального контейнера.
Вопрос : Как мне убедиться, что мой Python/Pytorch/Tensorflow действительно ограничен по памяти?
О : Для PyTorch вы можете запустить:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Пример нумбы:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Вопрос : Может ли пользователь нарушить ограничение?
О : Мы уверены, что злонамеренный пользователь найдет способ. В наши намерения никогда не входило обеспечение защиты от злонамеренных пользователей.
Если у вас есть злонамеренный пользователь, имеющий доступ к вашим машинам, дробные графические процессоры не являются для вас проблемой номер один?
Вопрос : Как я могу программно обнаружить ограничение памяти?
О : Вы можете проверить переменную среды ОС GPU_MEM_LIMIT_GB .
Обратите внимание, что его изменение не устранит и не уменьшит ограничение.
Вопрос : Запуск контейнера с --pid=host безопасен/безопасен?
Ответ : Это должно быть одновременно надежно и безопасно. Основное предостережение с точки зрения безопасности заключается в том, что процесс контейнера может видеть любую командную строку, запущенную в хост-системе. Если командная строка процесса содержит «секрет», то да, это может стать потенциальной утечкой данных. Обратите внимание, что передавать «секреты» в командной строке не рекомендуется, и поэтому мы не считаем это угрозой безопасности. Тем не менее, если безопасность является ключевым моментом, корпоративная версия (см. ниже) устраняет необходимость использования pid-host и, таким образом, обеспечивает полную безопасность.
Вопрос : Можете ли вы запустить контейнер без --pid=host ?
А : Ты можешь! Но вам придется использовать корпоративную версию контейнераcleml-fractional-gpu (в противном случае ограничение памяти будет применяться для всей системы, а не для всего контейнера). Если эта функция важна для вас, обратитесь в отдел продаж и поддержки ClearML.
Лицензия на использование ClearML предоставляется только в целях исследований или разработок. ClearML можно использовать в образовательных, личных или внутренних коммерческих целях.
Расширенная коммерческая лицензия для использования в продукте или услуге доступна как часть решения ClearML Scale или Enterprise.
ClearML предлагает корпоративную и коммерческую лицензию, добавляющую множество дополнительных функций поверх дробных графических процессоров, в том числе оркестровку, очереди приоритетов, управление квотами, информационную панель вычислительного кластера, управление наборами данных и управление экспериментами, а также безопасность и поддержку корпоративного уровня. Узнайте больше о ClearML Orchestration или свяжитесь с нами напрямую в отделе продаж ClearML.
Расскажите об этом всем! #ClearMLFractionalGPU
Присоединяйтесь к нашему каналу Slack
Сообщите нам, если что-то не работает, и помогите нам отладить проблему на странице «Проблемы».
Этот продукт предоставлен вам командой ClearML с ❤️


