amazon bedrock rag
1.0.0
Поисково-дополненная генерация (RAG) — это процесс оптимизации вывода большой языковой модели, поэтому перед генерацией ответа он ссылается на авторитетную базу знаний за пределами источников обучающих данных. Модели больших языков (LLM) обучаются на огромных объемах данных и используют миллиарды параметров для генерации исходных результатов для таких задач, как ответы на вопросы, перевод языков и завершение предложений. RAG расширяет и без того мощные возможности LLM на конкретные области или внутреннюю базу знаний организации, и все это без необходимости переобучения модели. Это экономически эффективный подход к улучшению результатов LLM, поэтому он остается актуальным, точным и полезным в различных контекстах. Узнайте больше о RAG здесь.
Amazon Bedrock — это полностью управляемый сервис, который предлагает выбор высокопроизводительных базовых моделей (FM) от ведущих компаний в области искусственного интеллекта, таких как AI21 Labs, Anthropic, Cohere, Meta, Stability AI и Amazon, через единый API, а также широкий набор возможности, необходимые для создания генеративных приложений ИИ с безопасностью, конфиденциальностью и ответственным ИИ. Используя Amazon Bedrock, вы можете легко экспериментировать и оценивать лучшие FM для своего варианта использования, индивидуально настраивать их на основе своих данных с помощью таких методов, как точная настройка и RAG, а также создавать агенты, которые выполняют задачи с использованием ваших корпоративных систем и источников данных. Поскольку Amazon Bedrock является бессерверным, вам не нужно управлять какой-либо инфраструктурой, и вы можете безопасно интегрировать и развернуть возможности генеративного искусственного интеллекта в своих приложениях, используя уже знакомые вам сервисы AWS.
Базы знаний для Amazon Bedrock — это полностью управляемая функция, которая помогает реализовать весь рабочий процесс RAG от приема до извлечения и оперативного расширения без необходимости создания настраиваемой интеграции с источниками данных и управления потоками данных. Управление контекстом сеанса встроено, поэтому ваше приложение может легко поддерживать многоходовые разговоры.
В рамках создания базы знаний вы настраиваете источник данных и векторное хранилище по вашему выбору. Коннектор источника данных позволяет подключать ваши собственные данные к базе знаний. После настройки соединителя источника данных вы можете синхронизировать или обновлять свои данные с базой знаний и сделать их доступными для запросов. Amazon Bedrock сначала разбивает ваши документы или контент на управляемые фрагменты для эффективного поиска данных. Затем фрагменты преобразуются во вложения и записываются в векторный индекс (векторное представление данных), сохраняя при этом сопоставление с исходным документом. Векторные вложения позволяют математически сравнивать тексты на предмет сходства.
Этот проект реализуется с двумя источниками данных; источник данных для документов, хранящихся в Amazon S3, и другой источник данных для контента, опубликованного на веб-сайте. Коллекция векторного поиска создается в Amazon OpenSearch Serverless для хранения векторов.
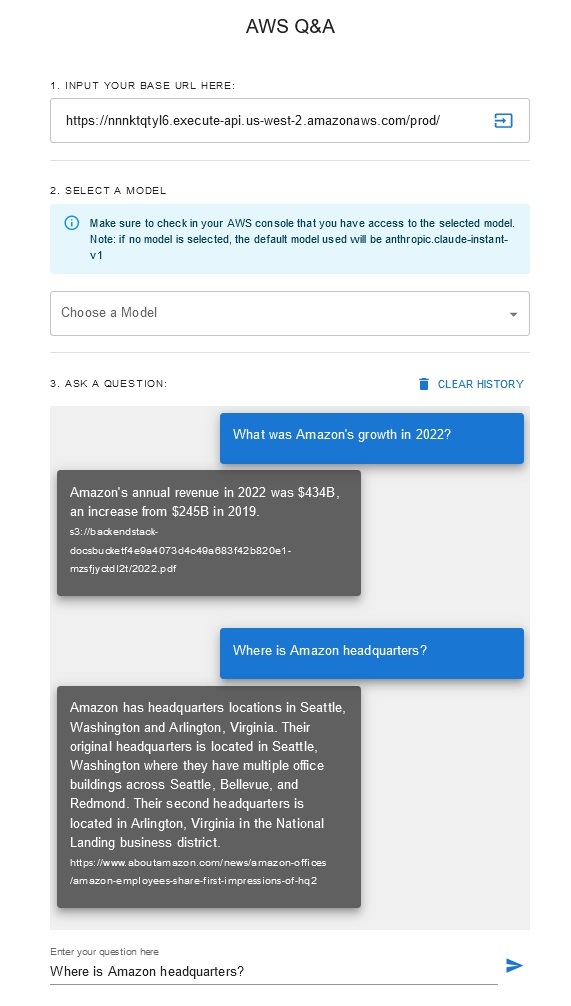
Чат-бот вопросов и ответов 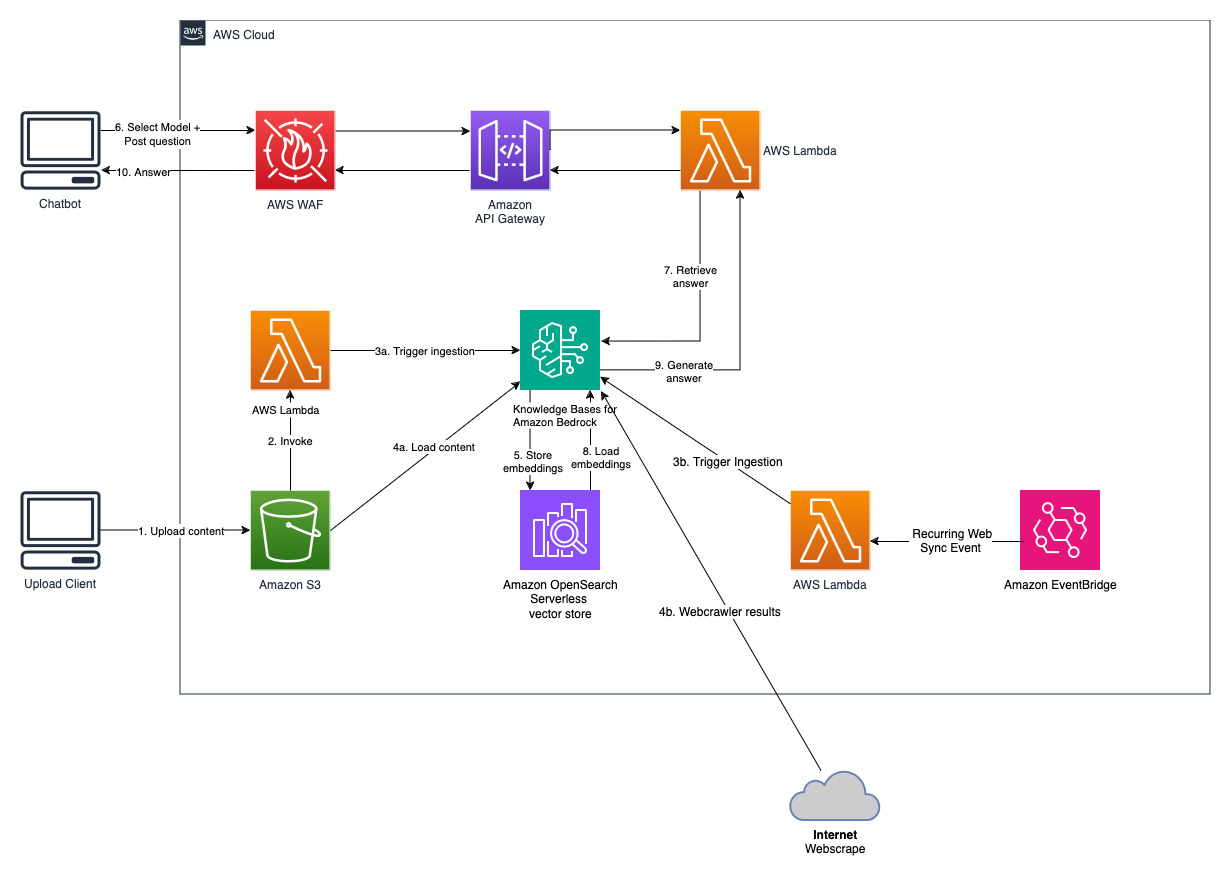
Добавить новые веб-сайты для веб-источника данных 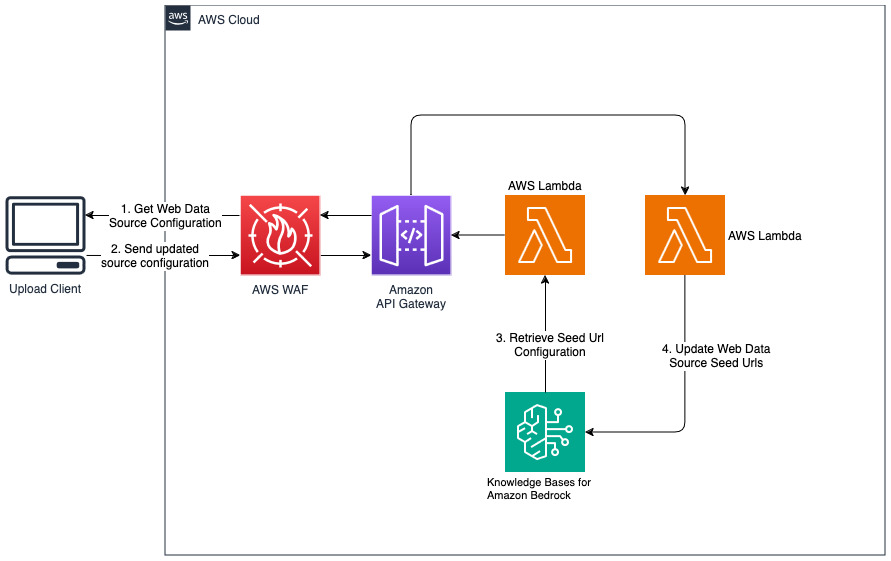
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Укажите IP-адрес клиента, которому разрешен доступ к шлюзу API, в формате CIDR как часть контекстной переменной «allowedip».
Когда развертывание завершится,
Это решение позволяет пользователям выбирать, какую базовую модель они хотят использовать на этапе поиска и генерации. Модель по умолчанию — Anthropic Claude Instant . В качестве модели внедрения базы знаний в этом решении используется модель Amazon Titan Embeddings G1 — Text . Убедитесь, что у вас есть доступ к этим моделям фундамента.
Получите последний общедоступный годовой отчет Amazon и скопируйте его в корзину S3, указанную ранее. Для быстрого тестирования вы можете скопировать годовой отчет Amazon за 2022 год с помощью консоли AWS S3. Содержимое из корзины S3 будет автоматически синхронизировано с базой знаний, поскольку развертывание решения отслеживает появление нового контента в корзине S3 и запускает рабочий процесс приема.
Развернутое решение инициализирует источник веб-данных под названием «WebCrawlerDataSource» с URL-адресом https://www.aboutamazon.com/news/amazon-offices . Вам необходимо вручную синхронизировать этот источник данных Web Crawler с базой знаний из консоли AWS для поиска по содержимому веб-сайта, поскольку прием веб-сайта запланирован на будущее. Выберите этот источник данных в консоли знаний на основе Amazon Bedrock и запустите операцию «Синхронизация». Подробности см. в разделе Синхронизация источника данных с базой знаний Amazon Bedrock. Обратите внимание, что контент сайта будет доступен чат-боту вопросов и ответов только после завершения синхронизации. Используйте это руководство при настройке веб-сайтов в качестве источника данных.
Используйте «cdk уничтожить», чтобы удалить стек облачных ресурсов, созданный при развертывании этого решения.


