EasyNLU
1.0.0
EasyNLU — это библиотека распознавания естественного языка (NLU), написанная на Java для мобильных приложений. Будучи основанным на грамматике, он хорошо подходит для узких областей, требующих жесткого контроля.
В проекте есть пример приложения для Android, которое может планировать напоминания с помощью ввода на естественном языке:
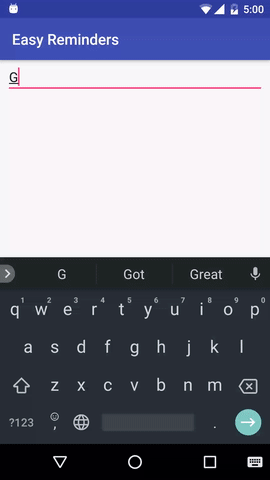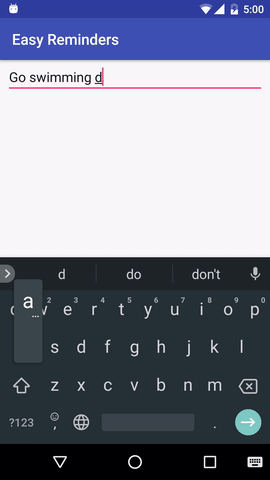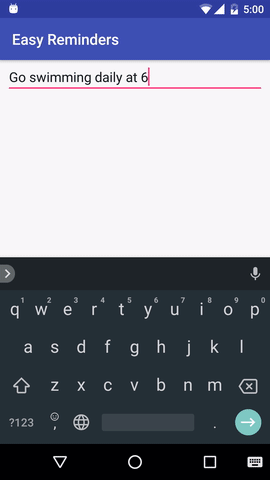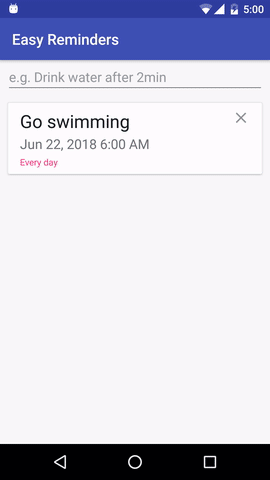
EasyNLU имеет лицензию Apache 2.0.
По своей сути EasyNLU — это семантический анализатор на основе CCG. Хорошее введение в семантический анализ можно найти здесь. Семантический анализатор может анализировать входные данные следующим образом:
Сходи к стоматологу завтра в 17:00.
в структурированную форму:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU предоставляет структурированную форму в виде рекурсивной карты Java. Эта структурированная форма затем может быть преобразована в объект конкретной задачи, который «исполняется». Например, в примере проекта структурированная форма преобразуется в объект Reminder , который имеет такие поля, как task , startTime и repeat , и используется для настройки будильника с помощью службы AlarmManager.
В целом ниже приведены шаги высокого уровня для настройки возможностей NLU:
Прежде чем писать какие-либо правила, нам следует определить объем задачи и параметры структурированной формы. В качестве игрушечного примера предположим, что наша задача — включать и выключать такие функции телефона, как Bluetooh, Wi-Fi и GPS. Итак, поля:
Примером структурированной формы может быть:
{feature: "bluetooth", action: "enable" }
Также полезно иметь несколько примеров входных данных, чтобы понять варианты:
Продолжая пример с игрушкой, можно сказать, что на верхнем уровне у нас есть действие настройки, которое должно иметь функцию и действие. Затем мы используем правила для сбора этой информации:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); Правило содержит как минимум LHS и RHS. По соглашению мы добавляем к слову знак «$», чтобы указать категорию. Категория представляет собой набор слов или других категорий. В приведенных выше правилах $Feature представляет такие слова, как bluetooth, bt, wifi и т. д., которые мы фиксируем с помощью «лексических» правил:
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); Чтобы нормализовать вариации в именах функций, мы структурируем $Features на подфункции:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); Аналогично для $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); Обратите внимание на '?' в третьем правиле; это означает, что категория $Switch является необязательной. Чтобы определить, был ли анализ успешным, синтаксический анализатор ищет специальную категорию, называемую корневой категорией. По соглашению он обозначается как $ROOT . Нам нужно добавить правило для доступа к этой категории:
Rule root = new Rule ( "$ROOT" , "$Setting" );С помощью этого набора правил наш парсер сможет анализировать приведенные выше примеры, преобразуя их в так называемые синтаксические деревья.
Анализ бесполезен, если мы не можем извлечь смысл предложения. Это значение фиксируется структурированной формой (логической формой на жаргоне НЛП). В EasyNLU мы передаем третий параметр в определении правила, чтобы определить, как будет извлекаться семантика. Для этого мы используем синтаксис JSON со специальными маркерами:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first сообщает синтаксическому анализатору выбрать значение первой категории правила RHS. В этом случае это будет либо «включить», либо «отключить» в зависимости от предложения. Другие маркеры включают в себя:
@identity : функция идентификации.@last : выберите значение последней категории RHS.@N : выберите значение N -й категории RHS, например @3 выберет третью.@merge : объединить значения всех категорий. Будут объединены только именованные значения (например {action: enable} ).@append : добавить значения всех категорий в список. Полученный список должен быть назван. Разрешены только именованные значения.После добавления семантических маркеров наши правила становятся такими:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);Если параметр семантики не указан, синтаксический анализатор создаст значение по умолчанию, равное RHS.
Чтобы запустить парсер, клонируйте этот репозиторий и импортируйте модуль парсера в свой проект Android Studio/IntelliJ. Анализатор EasyNLU принимает объект Grammar , содержащий правила, объект Tokenizer для преобразования входного предложения в слова и необязательный список объектов Annotator для аннотирования таких объектов, как числа, даты, места и т. д. После определения правил запустите следующий код:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));Вы должны получить следующий вывод:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
Попробуйте другие варианты. Если синтаксический анализ примера варианта не удался, вы не получите никаких результатов. Затем вы можете добавить или изменить правила и повторить процесс разработки грамматики.
EasyNLU теперь поддерживает списки в структурированной форме. Для вышеуказанного домена он может обрабатывать такие входные данные, как
Отключить определение местоположения через GPS
Добавьте эти 3 дополнительных правила к приведенной выше грамматике:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
Запустите новый запрос, например:
System.out.println(parser.parse("disable location bt gps"));
Вы должны получить этот вывод:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
Обратите внимание, что эти правила срабатывают только в том случае, если в запросе имеется более одного объекта.
Аннотаторы упрощают работу с определенными типами токенов, которые в противном случае были бы громоздкими или совершенно невозможными для обработки с помощью правил. Например, возьмем класс NumberAnnotator . Он обнаружит и пометит все числа как $NUMBER . Затем вы можете напрямую ссылаться на категорию в своих правилах, например:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU в настоящее время поставляется с несколькими аннотаторами:
NumberAnnotator : аннотирует числа.DateTimeAnnotator : аннотирует некоторые форматы дат. Также предоставляет свои собственные правила, которые вы добавляете с помощью DateTimeAnnotator.rules()TokenAnnotator : аннотирует каждый токен ввода как $TOKENPhraseAnnotator : аннотирует каждую непрерывную фразу ввода как $PHRASE Чтобы использовать собственный аннотатор, реализуйте интерфейс Annotator и передайте его анализатору. Обратитесь к встроенным аннотаторам, чтобы понять, как их реализовать.
EasyNLU поддерживает загрузку правил из текстовых файлов. Каждое правило должно быть на отдельной строке. Левая, правая и семантика должны быть разделены табуляцией:
$EnableDisable ?$Switch $OnOff @last
Будьте осторожны и не используйте IDE, которые автоматически преобразуют табуляцию в пробелы.
По мере добавления новых правил в анализатор вы обнаружите, что анализатор находит несколько вариантов анализа для определенных входных данных. Это связано с общей неоднозначностью человеческих языков. Чтобы определить, насколько точен парсер для вашей задачи, вам нужно запустить его на размеченных примерах.
Как и предыдущие правила, EasyNLU использует примеры, определенные в виде обычного текста. Каждая строка должна представлять собой отдельный пример и содержать необработанный текст и структурированную форму, разделенные табуляцией:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
Важно, чтобы вы охватывали приемлемое количество или вариации входных данных. Вы получите больше разнообразия, если поручите эту задачу разным людям. Количество примеров зависит от сложности предметной области. Образец набора данных, представленный в этом проекте, содержит более 100 примеров.
Когда у вас есть данные, вы можете объединить их в набор данных. Часть обучения осуществляется модулем trainer ; импортируйте его в свой проект. Загрузите набор данных следующим образом:
Dataset dataset = Dataset . fromText ( 'filename.txt' )Мы оцениваем парсер для определения двух типов точности.
Для запуска оценки мы используем класс Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
Второй параметр функции оценки — это уровень детализации. Чем выше число, тем более подробный вывод. Функция evaluate() запускает анализатор через каждый пример и показывает неправильные анализы, наконец, отображая точность. Если вы получаете обе точности в пределах 90-х, тогда обучение не требуется, вы, вероятно, сможете справиться с этими несколькими неудачными анализами с помощью постобработки. Если точность оракула высокая, а точность прогнозирования низкая, то обучение системы поможет. Если точность оракула сама по себе низкая, вам нужно больше заниматься грамматической разработкой.
Чтобы получить правильный анализ, мы оцениваем их и выбираем тот, который имеет наивысший балл. EasyNLU использует простую линейную модель для расчета баллов. Обучение выполняется с использованием стохастического градиентного спуска (SGD) с функцией потери шарнира. Входные функции основаны на количестве правил и полях в структурированной форме. Обученные веса затем сохраняются в текстовый файл.
Вы можете настроить некоторые параметры модели/обучения, чтобы добиться большей точности. Для моделей напоминаний использовались следующие параметры:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );Запустите обучающий код следующим образом:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );Это обучит модель в течение 100 эпох с разделением поезд-тест 0,8. Он отобразит точность тестового набора и сохранит веса модели в указанном пути к файлу. Чтобы обучить весь набор данных, установите для параметра развертывания значение true. Вы можете запустить интерактивный режим, введя данные из консоли:
experiement.interactive();
ПРИМЕЧАНИЕ. Это обучение не гарантирует высокую точность даже на большом количестве примеров. В некоторых сценариях предоставленные функции могут быть недостаточно различительными. Если вы застряли в таком случае, зарегистрируйте проблему, и мы сможем найти дополнительные функции.
Вес модели представляет собой обычный текстовый файл. Проект Android можно поместить в папку assets и загрузить с помощью AssetManager. Пожалуйста, обратитесь к ReminderNlu.java для получения более подробной информации. Вы даже можете хранить свои веса и правила в облаке и обновлять свою модель по беспроводной сети (кто-нибудь Firebase?).
Как только синтаксический анализатор хорошо справится с преобразованием входных данных на естественном языке в структурированную форму, вам, вероятно, понадобятся эти данные в объекте, специфичном для задачи. Для некоторых доменов, таких как игрушечный пример выше, это может быть довольно просто. Для других вам, возможно, придется разрешить ссылки на такие вещи, как даты, места, контакты и т. д. В примере напоминания даты часто являются относительными (например, «завтра», «через 2 часа» и т. д.), которые необходимо преобразовать в абсолютные значения. Пожалуйста, обратитесь к ArgumentResolver.java, чтобы узнать, как выполняется разрешение.
СОВЕТ: Сведите логику разрешения к минимуму при определении правил и делайте большую часть ее при постобработке. Это позволит упростить правила.


