inverted_index
1.0.0
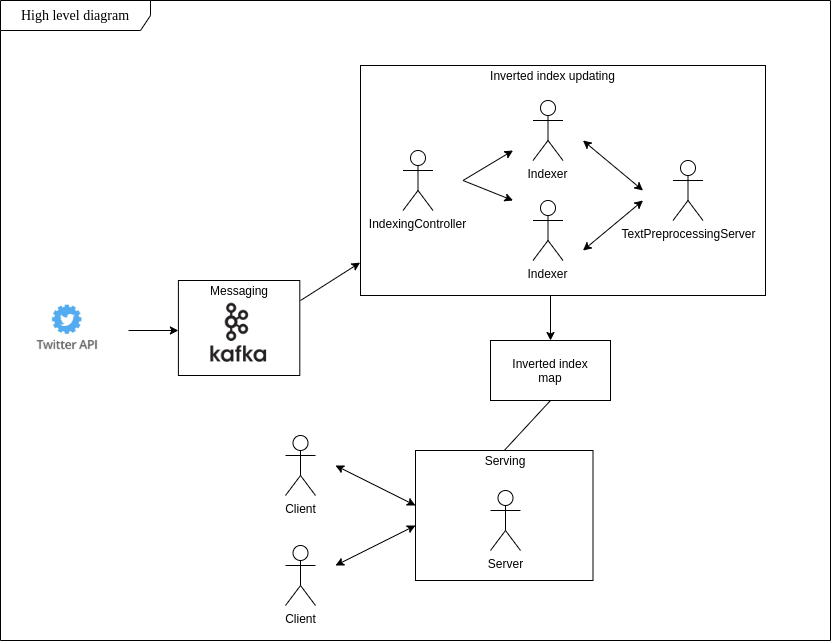
Искать фразы, которые говорят окружающие, может быть непросто. А как насчет динамических обновлений этого набора данных? Масштабируемое хранилище и низкая задержка? Моя главная цель в этом проекте — создать систему, которая отвечает этим требованиям и позволяет быть в курсе тенденций, представленных в твитах, в режиме реального времени.
Следуя идее инвертированного индекса, я реализовал приложение, которое в режиме реального времени находит твиты с определенным содержанием, сохраняет их в локальной файловой системе и позволяет выполнять поиск по словам сразу после инициализации клиентского соединения.
Для того, чтобы запустить приложение вам необходимо:
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' Создайте Dockerfiles для клиента и сервера:
./gradlew clean build createClientDockerfile createMainDockerfile
Это создаст app_server.Dockerfile и app_client.Dockerfile в корневом каталоге.
Запустить приложение:
docker-compose up
Запускаем клиентскую сессию:
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
Начните вводить интересующие вас слова. Сервер вернет местоположение твитов в формате dataset_v2//tweet_N.txt. Например:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
Список предлагаемых функций (и известных проблем) см. в разделе «Открытые проблемы».
Распространяется по лицензии MIT. См. LICENSE для получения дополнительной информации.


